master-worker模式以及几种实现
模型介绍
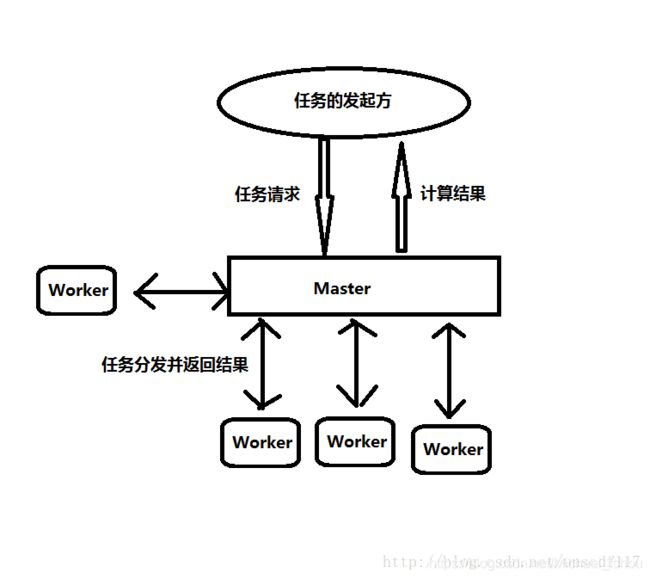
Master-Worker模式是常用的并行模式之一,它的核心思想是,系统有两个进程协作工作:Master进程,负责接收和分配任务;Worker进程,负责处理子任务。当Worker进程将子任务处理完成后,结果返回给Master进程,由Master进程做归纳汇总,最后得到最终的结果。
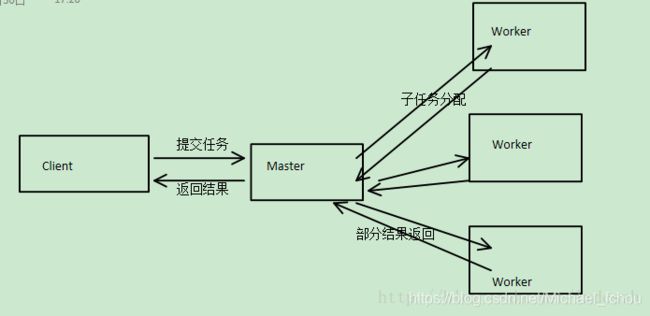
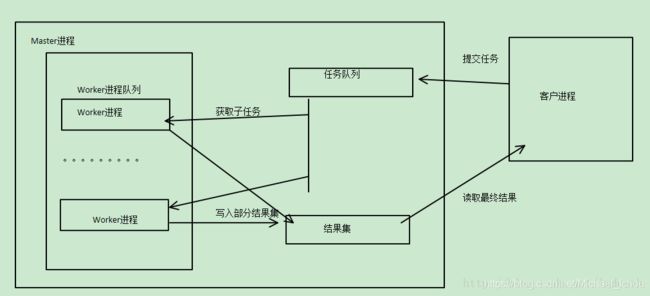
1.ZooKeeper中的master-worker实现
每个worker的监控与调度可以交给第三方工具去实现,比如Zookeeper便可以充当这样的角色,zookeeper是一个分布式文件系统,我们可以把worker挂载在它的/worker目录(结点)下,注意这个worker目录应该是一个临时的目录,且目录下的worker结点应该是有序的,但当worker挂掉后,又该如何知道它被分配了哪些任务呢,所以还应该有个/assign目录,记录worker结点已被分配的任务,当然,任务被挂载在/job结点下面,所以通过Zookeeper监控和调度时,应当有四个结点,三个角色。监听/job目录,如果该目录下的结点发生了变化,就将待分配的job分配给空闲的worker结点,而如何知道该worker是否空闲呢,就看其对应的assign节点是否为空,如果为空,便可继续分配。
private void onNodeChange(WatchedEvent event){
// event的类型为数量更新
if (Watcher.Event.EventType.NodeChildrenChanged != event.getType()) {
return;
}
try {
// 如果节点数量更新,那么遍历子节点,还没被处理的job
List jobPathList = zooKeeper.getChildren("/job", false);
if (CollectionUtils.isEmpty(jobPathList)) {
return;
}
JobMessage initJobMessage = null;
String initJobPath = "";
for (String jobPath : jobPathList) {
String jobCurrentPath = "/job/" + jobPath;
byte[] jobDataByteArray = zooKeeper.getData(jobCurrentPath, false, null);
String jobData = new String(jobDataByteArray);
if (StringUtils.isEmpty(jobData)) {
continue;
}
// 将其转换为 jobMessage ,其中的status为 0 ,也就是没被分配的时候,才会分配
JobMessage jobMessage = JSON.parseObject(jobData, JobMessage.class);
if (jobMessage == null) {
continue;
}
// 将path设置进去
if (JobMessage.StatusEnum.INIT.getValue() == jobMessage.getStatus()) {
initJobMessage = jobMessage;
initJobPath = jobPath;
break;
}
}
if (initJobMessage == null) {
return;
}
// 遍历 /worker 节点,如果对应节点在 /assign 中没有子节点,那么将其分配在/ assgin 中
List workNodeList = zooKeeper.getChildren("/worker", false);
if (CollectionUtils.isEmpty(slaveNodeList)) {
return;
}
boolean assignSuccess = false;
for (String workerNodePath : workerNodeList) {
String assignWorkerCurrentPath = "/assign/" + workerNodePath;
// 查询其有无子节点,如果没有子节点,说明可以分配给任务
List assignWorkerChildNodeList = zooKeeper.getChildren(assignWorkerCurrentPath, false);
if (CollectionUtils.isNotEmpty(assignWorkerChildNodeList)) {
continue;
}
// 给assign的对应节点增加一个子节点
String jobAssignPath = assignWorkerCurrentPath + "/" + initJobPath;
zooKeeper.create(jobAssignPath, JSON.toJSONString(initJobMessage).getBytes(), OPEN_ACL_UNSAFE , CreateMode.PERSISTENT);
assignSuccess = true;
break;
}
LogUtils.printLog("分配 " + (assignSuccess ? "成功" : "失败"));
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
代码中的onNodeChange是个回调方法,当master结点监听到node节点有变动时,回调该方法。
既然master结点负责任务的分配和调度,那worker结点也要监听自己被分配的任务的变化,执行完毕任务后,还要删除在/assign目录下的自己的结点信息,基本原理和上述代码差不多。
2.Netty中的master-worker实现
netty中的serverBootstrap的启动代码如下
bootstrap bootstrap = new ServerBootstrap(
new NioServerSocketChannelFactory(
Executors.newCachedThreadPool(),//master线程池
Executors.newCachedThreadPool(),//worker线程池
)
);
在netty中,一个master对应一个端口,当master接收了socket的连接请求后,channel通道就此建立,建立连接请求后的消息交给worker线程处理,实际上是master线程调用serverSocketChannel后,由factory从worker线程池(NioEventLoopGroup)中找出一个worker线程(NioEventLoop)进行后续处理,一个worker可以服务不同的socket(即IO多路复用,原理是NioEventLoop持有selector多路复用器和任务队列queue,每个channel都会注册在selector上,并持有selectKey,select表示其注册在哪个选择器上,所以worker线程可以同时接收到多个就绪事件),当然,也可以设置成阻塞模式,即一个worker只能服务一个socket,但是现在服务器都会采取keep-alive,所以最好设置成非阻塞的模式,不然对worrker资源会造成很大的消耗与浪费。
在worker线程中,接收到的消息实际上交给ChannelPipeline处理(这个pipeline实际上就是filter,而filter通常采用责任链模式,由许多handler组成),当所有的handler走完没有异常,证明worker的工作完毕,会被worker线程池回收,其中还可以再优化,比如碰到耗时的handler(通常是业务handler),可以再开一个新线程处理,这个新线程也最好来自别的新线程池,从而当前worker可以尽早释放,提高worker线程的周转率。
3.Golang中的master-worker实现
通过channel来进行通信。
下面是worker的实现代码:
package worker
import (
"fmt"
)
//需要处理的任务,简单定义一下
type Job struct {
num int
}
func NewJob(num int) Job {
return Job{num: num}
}
type Worker struct {
id int //workerID
WorkerPool chan chan Job //worker池
JobChannel chan Job //worker从JobChannel中获取Job进行处理
Result map[interface{}]int //worker将处理结果放入reuslt
quit chan bool //停止worker信号
}
func NewWorker(workerPool chan chan Job, result map[interface{}]int, id int) Worker {
return Worker{
id: id,
WorkerPool: workerPool,
JobChannel: make(chan Job),
Result: result,
quit: make(chan bool),
}
}
func (w Worker) Start() {
go func() {
for {
//将worker的JobChannel放入master的workerPool中
w.WorkerPool <- w.JobChannel
select {
//从JobChannel中获取Job进行处理,JobChannel是同步通道,会阻塞于此
case job := <-w.JobChannel:
//处理这个job
//并将处理得到的结果存入master中的结果集
x := job.num * job.num
fmt.Println(w.id, ":", x)
w.Result[x] = w.id
//停止信号
case <-w.quit:
return
}
}
}()
}
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}
下面是master的实现代码:
package master
import (
"MasterWorkerPattern/worker"
)
type Master struct {
WorkerPool chan chan worker.Job //worker池
Result map[interface{}]int //存放worker处理后的结果集
jobQueue chan worker.Job //待处理的任务chan
workerList []worker.Worker //存放worker列表,用于停止worker
}
var maxworker int
//maxWorkers:开启线程数
//result :结果集
func NewMaster(maxWorkers int, result map[interface{}]int) *Master {
pool := make(chan chan worker.Job, maxWorkers)
maxworker = maxWorkers
return &Master{WorkerPool: pool, Result: result, jobQueue: make(chan worker.Job, 2*maxWorkers)}
}
func (m *Master) Run() {
//启动所有的Worker
for i := 0; i < maxworker; i++ {
work := worker.NewWorker(m.WorkerPool, m.Result, i)
m.workerList = append(m.workerList, work)
work.Start()
}
go m.dispatch()
}
func (m *Master) dispatch() {
for {
select {
case job := <-m.jobQueue:
go func(job worker.Job) {
//从workerPool中取出一个worker的JobChannel
jobChannel := <-m.WorkerPool
//向这个JobChannel中发送job,worker中的接收配对操作会被唤醒
jobChannel <- job
}(job)
}
}
}
//添加任务到任务通道
func (m *Master) AddJob(num int) {
job := worker.NewJob(num)
//向任务通道发送任务
m.jobQueue <- job
}
//停止所有任务
func (m *Master) Stop() {
for _, v := range m.workerList {
v.Stop()
}
}
test
package main
import (
"MasterWorkerPattern/master"
"fmt"
"time"
)
func main() {
result := map[interface{}]int{}
mas := master.NewMaster(4, result)
mas.Run()
for i := 0; i < 10; i++ {
mas.AddJob(i)
}
time.Sleep(time.Millisecond)
//mas.Stop()
fmt.Println("result=", result)
}
运行结果是不确定的
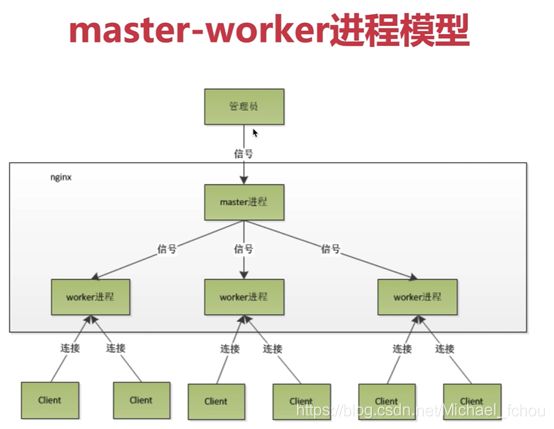
4.Nginx中的master-worker实现
基本原理和Netty差不多,如图所示
Nginx采用的就是大名鼎鼎的Linux中的IO复用模型Epoll,这里简单描述一下
首先,Epoll会在Linux内核中申请一颗B+树作为文件系统,然后会调用epoll_create方法建立一个epoll对象,用于存放通过event_ctl()方法向epoll对象注册的事件,这些注册的事件挂载在红黑树下,这些注册的事件都会与设备驱动(都可以抽象成一个socket)建立回调关系,当相应的事件发生时,便会把这些事件(通常是一个类似于key的标识,即socketFd)放入event_poll结构体(双向链表,在linux内核中)。然后event_wait()返回给用户时只要检查内核中的双向链表是不是为空就行,(与select相比,不需要轮询了,因为事件就绪触发回调函数后会自动放入链表)不为空直接返回,这就是一个reactor反应器模式的实现,即事件驱动,事实上,事件驱动非常适用于IO密集型的场所。
for( ; ; ) // 无限循环
{
nfds = epoll_wait(epfd,events,20,500); // 最长阻塞 500s
for(i=0;ifd;
send( sockfd, md->ptr, strlen((char*)md->ptr), 0 ); //发送数据
ev.data.fd=sockfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev); //修改标识符,等待下一个循环时接收数据
}
else
{
//其他的处理
}
}
}
总结:
可以看出,master-worker模型在大数据计算场景下和fork-join思想一致,而在一些开发场景下,则是很明显的I/O多路复用的思想。
参考:https://blog.csdn.net/lmdcszh/article/details/39698189
https://www.cnblogs.com/moonyaoo/p/12846605.html