国庆堵车 | AI“高速”车辆检测轻而易举监测大家安全
关注并星标
从此不迷路
计算机视觉研究院

、.

学习群|扫码在主页获取加入方式
欢迎关注“
计算机视觉研究院
”
计算机视觉研究院专栏
作者:Edison_G
国庆节不管是离开小城镇还是进入大城市,每个高速路口都是堵车,现在人工智能愈来愈发达,不再用通过交警得知高速公路上的案发事件,现在都是摄像机覆盖,AI可以通过镜头&算法检测到行驶的车辆,如果有交通事故都是第一时间传达交警来处理。以至于有些路段都是通过无人机来进行交通事故处理!

一、简要
Single-stage目标检测方法因其具有实时性强、检测精度高等特点,近年来受到广泛关注。通常,大多数现有的single-stage检测器遵循两个常见的实践:它们使用在ImageNet上预先训练的网络主干来完成分类任务,并使用自顶向下的特征金字塔表示来处理规模变化。

好比在国庆节的高速路上,车辆较多,而且车辆的行驶速度不一,大多数都是高速行驶状态中,所以有研究者研究了一个single-stage检测框架,它结合了微调预训练模型和从零开始训练的优点。新框架构成了一个标准的网络,使用一个预先训练的主干网络和一个并行的轻型辅助网络从零开始训练。

此外,研究者认为通常使用的自顶向下的金字塔表示只关注于将高级语义从顶层传递到底层。然而在新的检测框架中引入了一个双向网络,它可以有效地传递中低层次和高层次的语义信息。
二、背景&动机
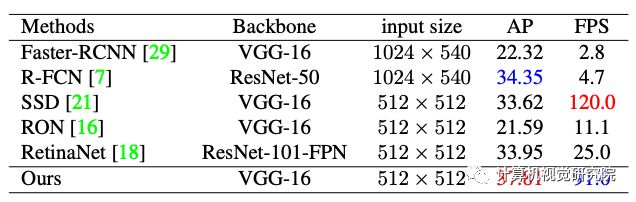
研究表明,训练检测模型从零开始解决这个问题,导致精确定位。但是与基于微调的对应网络相比,从零开始训练时间花费多。因此研究者引入一个训练模型,将训练前的和从零开始训练的优点结合起来,该框架使用一个预训练前的主干和一个从零开始训练的浅辅助网络。提出的方法相比baseline在AP指标上分别提高了7.4%和4.2%。在COCO测试集上,固定300×300输入,提出的以ResNet为backbone的检测器在单级推理方面超过了现有的单级检测方法,AP达到了34.3 ,在一个Titan X GPU上时间为19毫秒,同时兼顾了精度和速度。

现在遇到的问题:
小目标检测的难点
小目标检测是一个具有挑战性的问题,它既需要精确描述对象的低层/中层信息,也需要区分目标对象与背景或其他对象类别的高级语义信息。
近来的one-stage探测器的目标是获得与two-stage相近的检测精度。
尽管在大中型目标上效果较好,但这些探测器在小目标上的性能却低于预期。
例如:
当使用一个500×500的输入时,使用RetinaNet在COCO数据集上,
AP为47,但在小目标上,AP只有 14。预训练网络的利弊
主流的one-stage目标检测框架的通用策略是:利用一个经过ImageNet预训练的backbone完成分类任务。然后利用检测目标的数据集进行微调,从而达到快速收敛的效果。但是目标检测中的分类任务和定位任务之间仍然存在较大差异,尤其是在目标框重叠阈值高的情况下。
在ICCV2019Kaiming He的最新论文中,也对利用ImageNet
进行预训练然后fine-tune这种模式进行了思考,并且认为从
零开始训练检测模型,有助于精确定位。但是另一方面,与典
型的基于微调的网络相比,从零开始训练非常深的网络需要的
训练时间要长得多。三、新框架
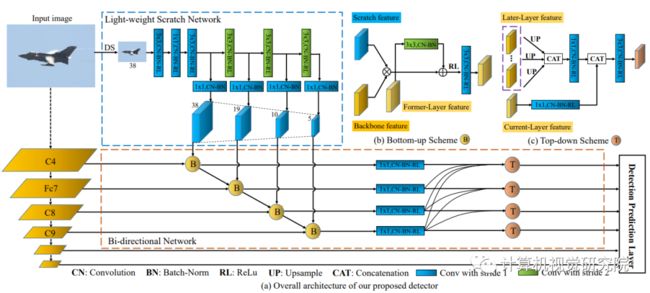
新框架图图显示了由三个主要组件组成的总体架构:标准SSD网络,轻量级暂存网络(LSN)和双向网络。
标准SSD使用预先训练的网络主干。因此将来自标准SSD层的功能(conv4_3,FC_7,conv8_2,conv9_2,conv10_2和conv11_2)称为主干特征,因为它们源自预先训练的网络主干。研究者采用VGG-16作为主干网络。轻量级暂存网络(LSN)产生低/中级特征表示,然后将其注入到后续标准预测层的主干特征中以改善其性能。然后,将当前层和前一层的结果特征以自下而上的方式组合到双向网络中。双向网络中的自顶向下方案包含独立的并行连接,以将高级语义信息从网络的较后一层注入到前一层。
不同之处:
新框架中双向网络与现有的几个单级检测器使用的特征金字塔网络(FPN)相比有以下不同之处。
首先,FPN的自底向上部分遵循了标准中使用的CNN的金字塔特征层次结构SSD的框架。FPN和SSD的自底向上部分都遵循骨干网的前馈计算,建立了特征层次结构。除了FPN/标准SSD中的自底向上部分外,新框架中的双向网络中的自底向上方案以级联的方式将前一层的特性传播到后一层。此外,FPN中的topdown金字塔通过级联操作逐层融合了许多CNN层。在双向网络的自顶向下方案中,预测层通过独立的并行连接进行融合,而不是逐层逐层的级联/顺序融合。
LSN Feature Extraction
在现有检测框架中常用的特征提取策略包括从网络主干,如VGG-16,在多个卷积块和最大池层的重复堆栈中提取特征,以产生语义强的特征(见下图)。
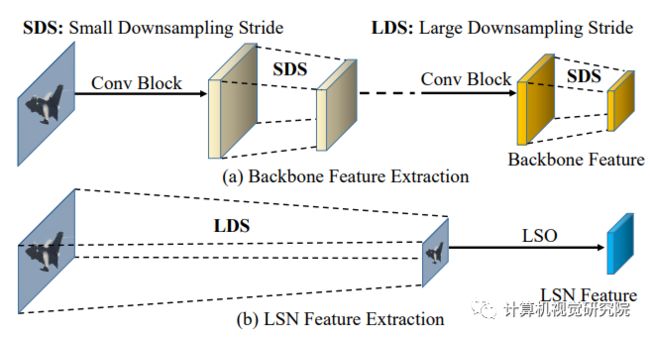
这种特征提取策略有利于偏好平移不变性的图像分类任务。与图像分类不同,目标检测还需要精确的目标描述,其中局部低/中水平特征(如纹理)信息也是至关重要的。为了补偿预先训练的网络的主干特征中的信息损失,在新框架的LSN中使用了另一种特征提取方案,如上图(b)。
首先,通过池化操作将输入图像下采样到第一SSD预测层的目标大小。然后,得到的下采样图像通过轻量级串行操作(LSO),包括卷积、batch-norm和ReLU层。请注意,LSN是用随机初始化从零开始训练的。它遵循类似的金字塔特征层次,如标准SSD。
四、实验

[18] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollr. Focal loss for dense object detection. In ICCV, 2017


@The End
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
Github源码|扫码回复“SSOD”获取