教你用python爬取王者荣耀英雄皮肤图片,并将图片保存在各自英雄的文件夹中。(附源码)
教你用python爬取王者荣耀英雄皮肤图片,并将图片保存在各自英雄的文件夹中。(附源码)
代码展示:
保存在各自的文件夹中
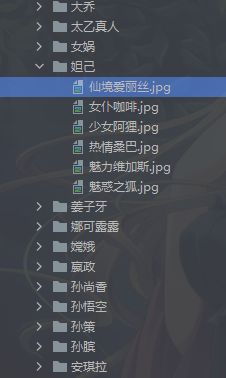
美么?
让我们开始爬虫之路
开发环境
windows 10
python3.6
引用库存
import requests
import os
import json
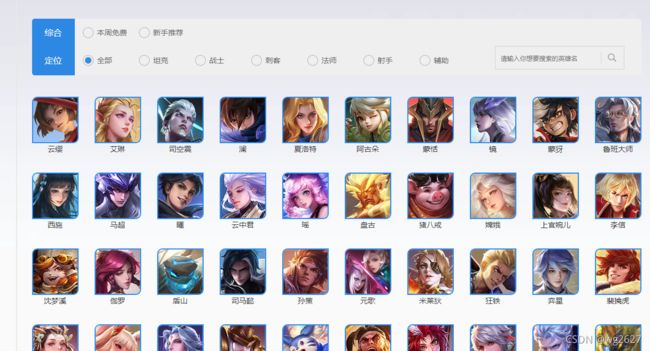
打开王者荣耀官网点击游戏资料
https://pvp.qq.com/web201605/herolist.shtml
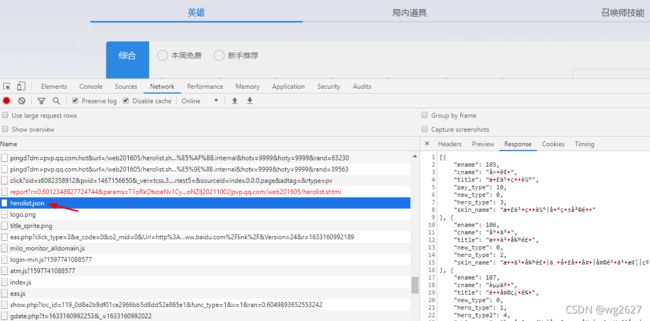
发现herolist.json文件中有英雄的信息,英雄ID、英雄名称,及皮肤的名称
通过英雄ID构造英雄皮肤地址
不需要webdriver 也能快速实现下载图片
import requests
import os
import json
def quid():
url='https://pvp.qq.com/web201605/js/herolist.json'
response=requests.get(url).text
response=json.loads(response)
for i in response:
print(i['ename']) #id
name=i['cname'] #英雄名字
id=i['ename']
word=i.setdefault('skin_name','没有找到')
print(word)
b=word.count('|') #count 查询字符出现的次数 python内置函数
bb=word.split('|') #split 分割字符返回列表
print(b)
if not os.path.exists(name): #创建图片保存目录
os.mkdir(name)
c = b + 1
for a in range(0,c):
aa=a+1
url4='http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/%s/%s-bigskin-%d.jpg'%(id,id,aa) #构造英雄皮肤地址
img2 = requests.get(url4)
print(url4)
图片名字 = bb[a]
with open(name + '/' + 图片名字+'.jpg', 'wb') as f:
f.write(img2.content)
print('爬取成功')
if __name__== '__main__':
quid()
代码仅供学习,欢迎一键三连,感谢各位的支持!
祝大家学习python顺利!