Python数据分析9-综合案例-网站日志分析
目录
9.1数据来源
9.1.1网站日志解析
9.1.2日志数据清洗
9.2日志数据分析
9.2.1网站流量分析
9.2.2状态码分析
9.2.3IP地址分析
网站的日志数据记录了所有Web对服务器的访问活动。本章主要讲解如何通过Python第三方库解析网站日志;如何利用pandas对网站日志数据进行预处理,并结合前面章节中的数据分析和数据可视化计数,对网站日志数据进行分析。
9.1数据来源
9.1.1网站日志解析
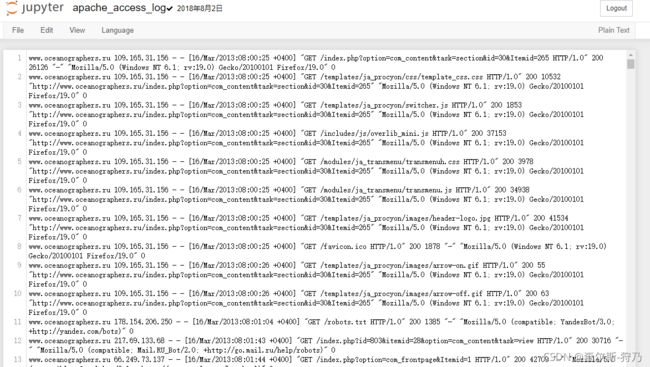
注:该数据集可以从从网上资源下载
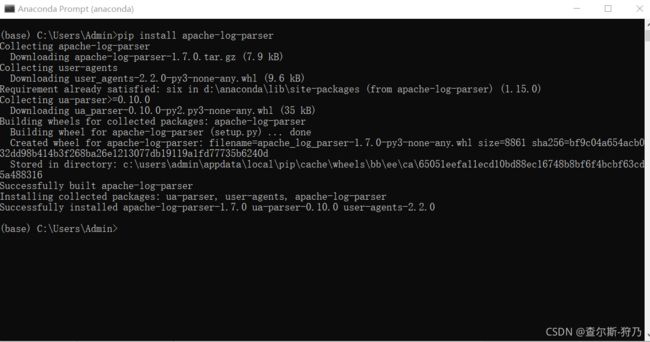
网站日志数据是有对应格式的,这里需要通过apache-log-parser库对该数据进行解析,使其变为规范的数据结构。如下图 ,首先通过pip安装这个解析库
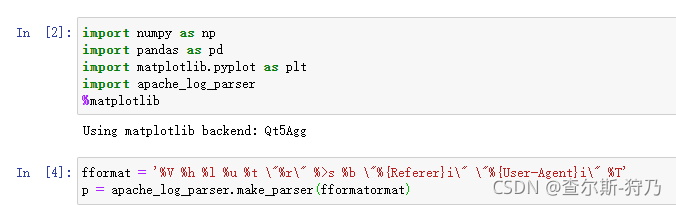
apache-log-parser解析库的使用方法很简单,首先需要了解该日志的格式,以此定义网站日志的数据格式,然后通过make_parser传入即可创建解析器,如图
注:各字段的含义可参考网站https://stackoverflow.com/questions/9234699/understanding-apache-acess-log上的说明
在log文件中提取一条日志,利用解析器去分析,如下图,可以看出,解析后的数据为字典格式
sample_string = 'koldunov.net 85.26.235.202 - - [16/Mar/2013:00:19:43 +0400] "GET /?p=364 HTTP/1.0" 200 65237 "http://koldunov.net/?p=364" "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11" 0'
data = p(sample_string)
data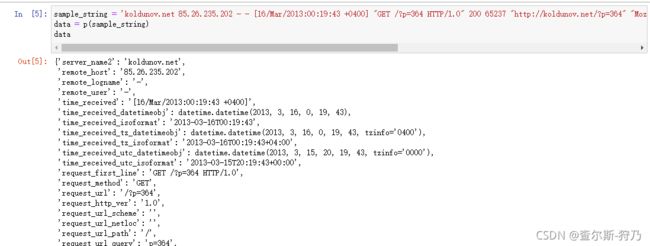
通过以下代码读取log文件,逐行进行读取并解析为字典,然后将字典传入列表中,以此构造DataFrame,如下图。这里提取感兴趣的几个字段,status为状态码,response_bytes_clf为返回的字节数(流量),remote_host为远端主机IP地址,requests_first_line为请求内容,time_received为时间数据。
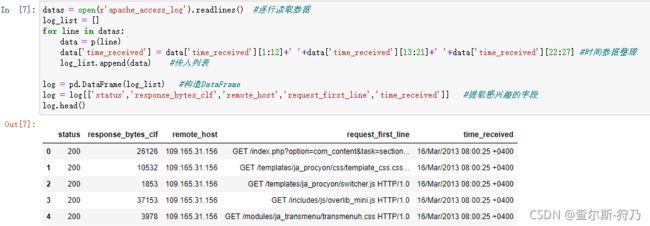
9.1.2日志数据清洗
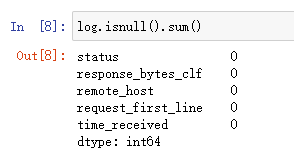
首先查看各字段是否有缺失值,如下图所示。可以看出,各字段中没有缺失值。
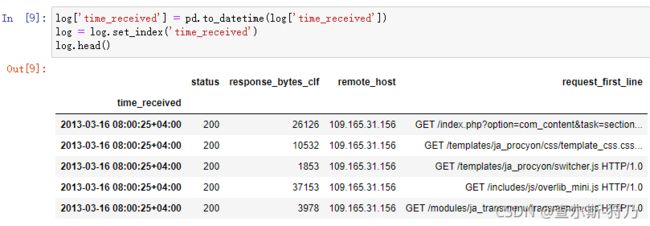
然后把time_received字段转换为时间数据类型,并设置为索引,如下图
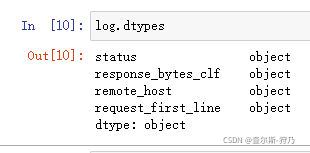
接着查看各字段数据类型,将status字段转换为int类型,如下图
此时在对 response_bytes_clf字段进行转换的过程中报错,查找原因发现其中含有“-”字符数据,如下图
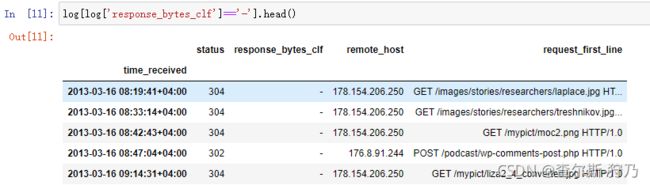
这里定义转换函数,当为“-”字符时,将其替换为空值,并将字节数据转换为M数据,如图所示

9.2日志数据分析
本节将利用时间序列绘图计数和pandas可视化计数,来可视化分析网站流量、网站的状态码和IP地址信息
9.2.1网站流量分析
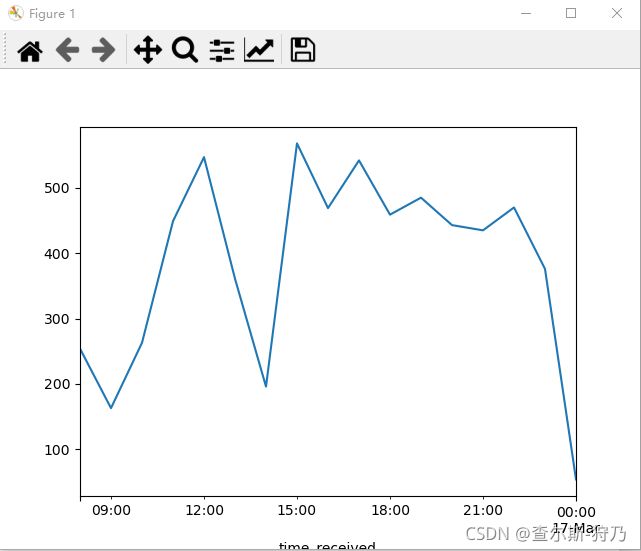
首先对流量字段进行可视化,如下图。可以看出,流量起伏不大,但又有一个极大峰值超过了20MB.
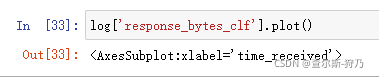
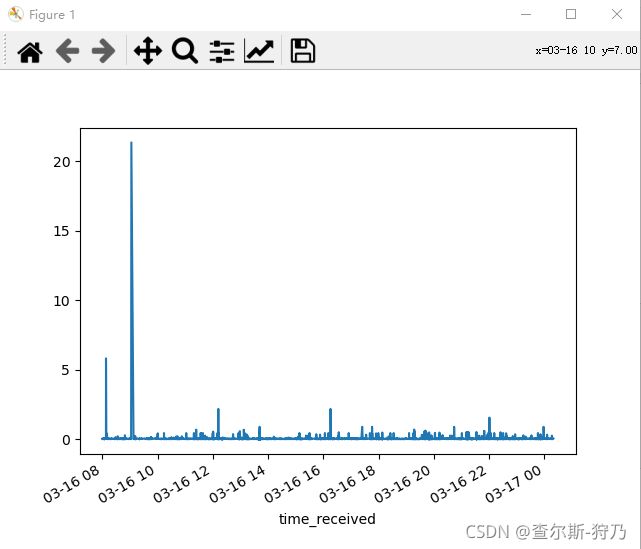
这个流量峰值 时怎样造成的?是网络攻击嘛?找到该条数据发现是用户下载了一个PDF文件,因此导致流量很大,如下图

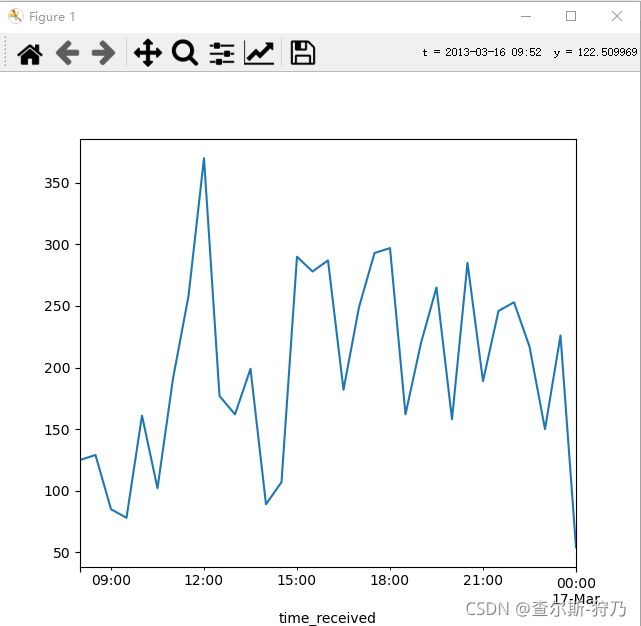
然后对时间进行重采样(30min)并继续计数,可以看出每个时间段访问的次数。如下图,在早上8.的访问次数最多,其余时间处于上线波动中。

当继续转换频率到低频率时,上下波动就不明显了,如下图

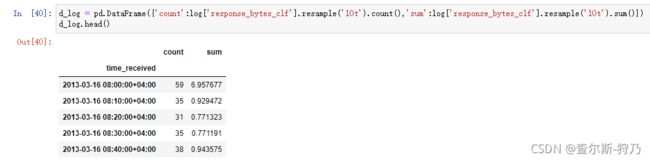
这里构造访问次数和访问流量的DataFrame,以分析他们之间的关联,如下图
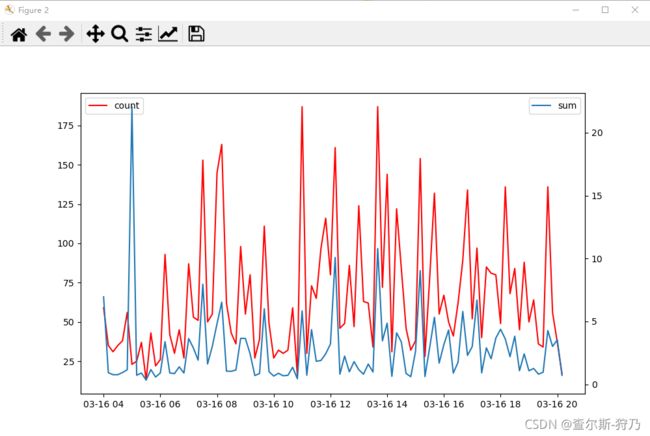
通过以下代码绘制折线图,效果如下图所示。可以看出,访问次数与流量具有相关性

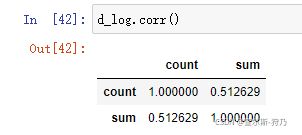
对于相关性大小,可以通过求相关系数来计算,如下图
9.2.2状态码分析
首先对状态码进行分组统计,如下图
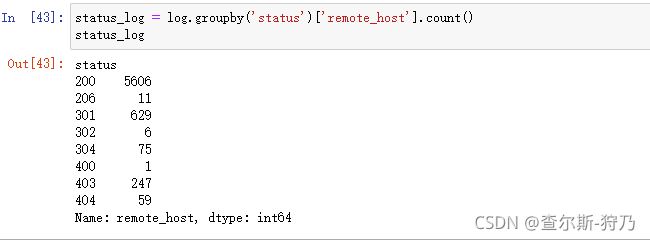
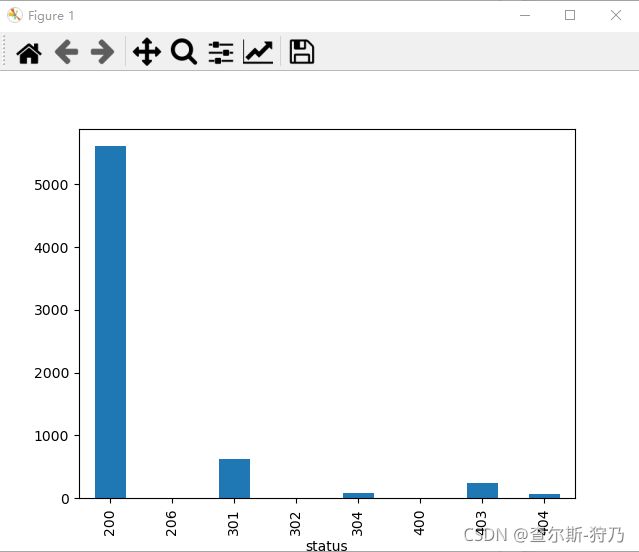
然后对状态码数据进行可视化,效果如图,可以看出正常访问的状态是最多的。

紧接着对404、403和200状态码进行时间序列分析,通过以下代码构造DataFrame。在这之前我们需要把状态码数据进行以下数据类型的处理,这样才方便我们后续操作,如下图
log['status'] = log['status'].astype('int') #将status数据类型转换为int类型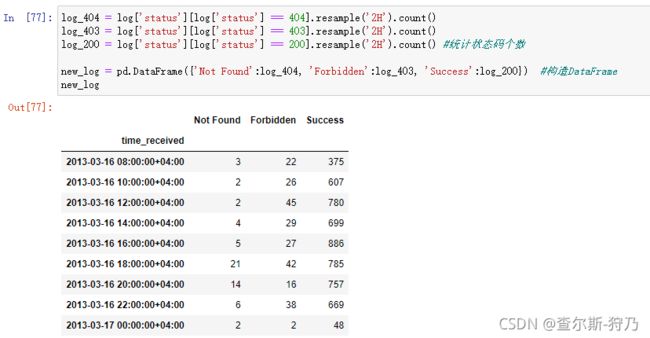
然后将这些数据进行可视化,代码和效果如图

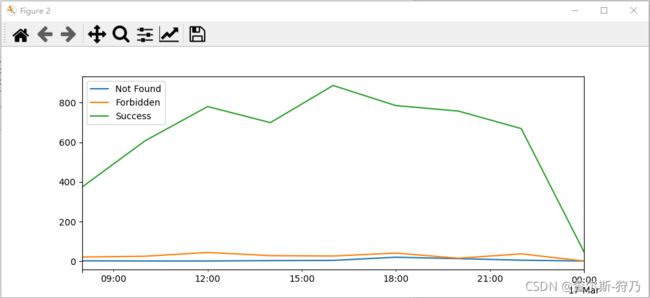
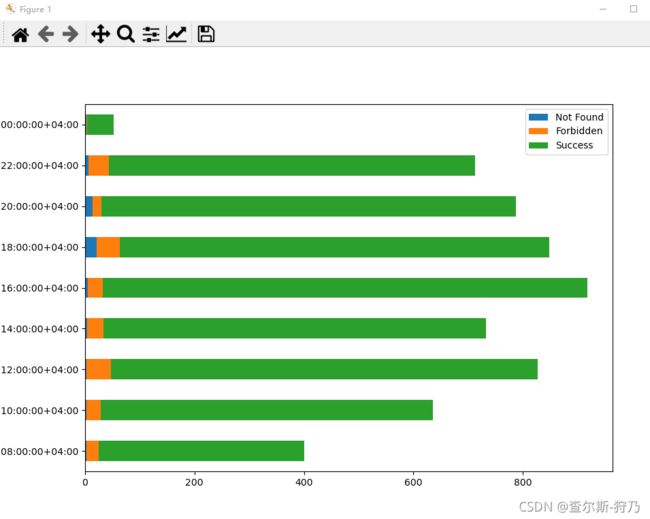
也可以通过这些数据来绘制堆积柱状图,如下图

9.2.3IP地址分析
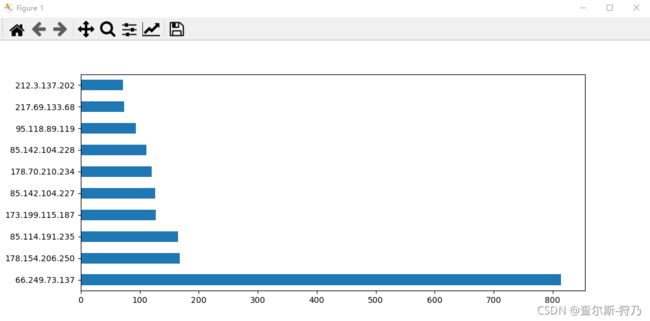
首先对remote_host字段进行计数,筛选前10为的IP进行绘图,效果如图所示。代码如下

pygeoip库可以将IP地址解析为地理数据,通过PIP进行安装,如下图。于此同时,需要在该网站上(https://dev.maxmind.com/geoip/legacy/geolite/)下载DAT文件才可以解析IP地址,如下图
回头更新,下面的先拖着