扩展Scikit-Learn -- EuroPython 2014 笔记
本文是EuroPython 2014 嘉宾 Florian Wilhelm 的讲座 《Extending Scikit-Learn with your own Regressor》的笔记。我写笔记是因为全部翻译比较费时间,而且很多英文句子翻译过来就很怪了。
Theil Sen 回归
嘉宾首先介绍了Scikit-learn和最小二乘法线性回归。
这里,最小二乘法有个问题,它对异常值(Outliers)比较敏感。

解决的方法是使用Theil Sen算法。Theil Sen算法的思想是。用斜率的中位数替换斜率的平均值。我们都知道使用平均值统计是会有偏差的,往往和我们的感受相差较大,这是因为马云一个人,和我们很多人平均,大家都成了百万富翁。所以平均值意义不大。中位数才可靠。
Theil Sen的算法非常简单。
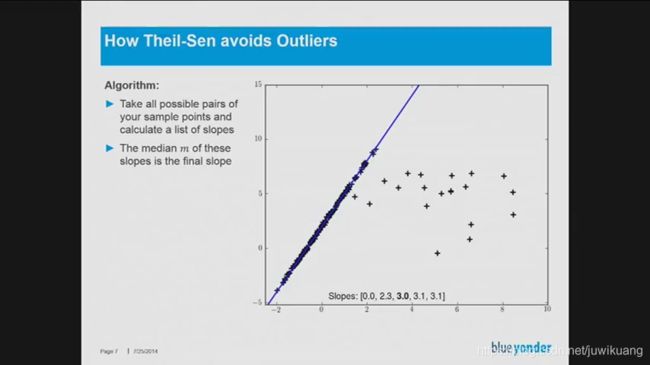
- 所有的点对,计算斜率
- 计算斜率的中位数
如果要使用Scikit-Learn编写Theil Sen,就要先了解Scikit-Learn的结构。Florian直接帮我们画了UML:

还给出了示例代码:

我的实现
我找来了Theil Sen的Scikit-Leran示例,并作图如下:

然后,几行代码,就实现了Theil Sen,当然,我这里只管一元一次。
class MyTheilSenRegressor(LinearModel, RegressorMixin):
def __init__(self):
...
def fit(self, X, y):
n_samples, n_features = X.shape
# get the slop using for loops
slops = []
for i in range(n_samples):
for j in range(i+1, n_samples):
slop = (y[j] - y[i]) / (X[j][0] - X[i][0])
slops.append(slop)
final_slop = np.median(slops)
x_bar = np.mean(X)
y_bar = np.mean(y)
intercept = y_bar - final_slop * x_bar
self.intercept_ = intercept
self.coef_ = np.array([final_slop])
return self
然后,把我的算法放到前面的示例里:

我发现,我的代码居然还比Scikit-Learn快。其实还可以更快的,我决定用numba。
import numba
def get_slop(X, y):
slops = []
for i in range(n_samples):
for j in range(i+1, n_samples):
slop = (y[j] - y[i]) / (X[j][0] - X[i][0])
slops.append(slop)
final_slop = np.median(slops)
return final_slop
这里测试结果是26毫秒。
然后,我直接在这个函数上面加上了装饰器@numba.njit(),结果报错。
TypingError: Failed in nopython mode pipeline (step: nopython frontend) final_slop = np.median(slops)
好吧,我可以把numpy函数拿到numba函数的外面。如下:
@numba.njit()
def get_slops(X, y):
slops = []
for i in range(n_samples):
for j in range(i+1, n_samples):
slop = (y[j] - y[i]) / (X[j][0] - X[i][0])
slops.append(slop)
#final_slop = np.median(slops)
return slops
def get_slop2(X, y):
slops = get_slops(X, y)
return np.median(slops)
这里测试结果是949微妙,比纯python版快了几十倍。
重写算法:
class FastTheilSenRegressor(LinearModel, RegressorMixin):
def __init__(self):
...
def fit(self, X, y):
n_samples, n_features = X.shape
# get the slop using for loops
final_slop = get_slop2(X, y)
x_bar = np.mean(X)
y_bar = np.mean(y)
intercept = y_bar - final_slop * x_bar
self.intercept_ = intercept
self.coef_ = np.array([final_slop])
return self
测试:

结论
演讲中Florian 还提到了joblib,unittest, 文档,以及最终把Theil Sen提交到Scikit-Learn等。这里略去。
今天,听了25分钟的演讲,又经过之后的代码练习。让我掌握了新的技能,以后,我自己写算法的时候,可以不必从头开始了。还是要利用好Scikit-Learn已有的类,进行扩展。
代码地址
https://github.com/EricWebsmith/articles/blob/main/extend_scikit_learn.ipynb
大陆地区请访问:
https://nbviewer.jupyter.org/github/EricWebsmith/articles/blob/main/extend_scikit_learn.ipynb