神经网络的传播原理——看不懂你来打我
神经网络的传播原理
本文介绍的是指深度神经网络 DNN 和 BP算法。
读 N 遍,推导一遍,用代码实现一遍 。还不懂,再来打我。
前不久换了一份工作,使得我能够真正的在工作中使用到机器学习中的神经网络。在此之前自学机器学习其他算法时也曾经去看过有关神经网络的文章,当时看完是一脸懵逼,不知所云,后来不了了之。幸运的去年参加了考研(虽然没有考上),复习了数学三的知识点,对我理解机器学习算法有很大的帮助。之所以写这篇文章主要是为了记下自己对于神经网络理解的思路,并分享给有需要的人。
首先说一下,要看懂神经网络必备的数学知识,那就是高等数学中多元微分(偏导数的求解),里面涉及到链式求导法则,这是我在复习数三的时候学到的,以前并不知道,还有就是比较简单的线性代数(矩阵的乘积)。
我会尽量将表达的详细些,但可能依然有人不会一遍就能看明白,反正我在学习的过程中是看了好多篇才看明白的,正所谓“书读百遍,其意自现。”所以大家如果一遍没看懂,不要灰心,或许只是这个笔者的表达方式不符合你的理解逻辑,多搜索几篇就好。
下面进入正题……篇幅有点长,但一定要逐句看完并理解。
名词解释
很多博客对于表达神经网络时,都会有些专业词语,比如:神经元,节点,xx层等等,我第一次看的时候是没有看明白的,WTF!什么鬼?
神经网络必须包含输入层、输出层,隐藏层可以没有,也可以包含多层隐藏层。每层都有一些节点,也叫神经元,但是你最好理解为特征向量,一个节点(神经元)就是一个特征向量。下面我将通俗的解释几个主要词汇。
-
神经元(节点,维度)
有时候在搜索博客时,你可能常常会看到‘某层有多少个神经元’,或者‘某层有多少个节点’,又或者‘某层有多少个维度’等等等等。但你只要知道,它们指的都是一个特征向量。在输入层的,就是你的原始数据的输入的特征向量,在其他层的,则是通过一系列线性或非线性变换得到的特征向量。直观上不正式的讲,就是数据中的‘一列’。
-
输入层
有了神经元的理解,下面理解网络层的概念就不难。由于一个神经元是一个特征向量,那么一个层由多个神经元组成,则它是一个矩阵,最常见的就是二维矩阵(表格数据)了。
那么输入层,顾名思义,就是输入数据的那一层。这一层的节点个数就是你数据的特征(变量)个数,每个节点(神经元)就是一个特征列向量(我假设了你的数据是一个csv文件,每一列是一个特征,每一个行是一个样本。)
-
隐藏层
其实就是输入层中的二维数据,经过各种矩阵点积、公式变换后的特征向量,也是每个节点(神经元)就是一个特征向量。
-
输出层
这个理解稍微难一点,先说定义,如果是分类任务,则输出节点(神经元)就是类别的个数,每个节点(神经元)同样是一个列向量,但对于二分类,输出节点可以是1个,也可以是2个,而回归任务,输出的节点(神经元)就是一个。
看完上门的三个定义,我猜你肯定一脸懵逼,WTF!你这写的还没其他博客详细,下面我来举个例子来解释下输入层的节点(神经元)(输出层和隐藏层是一个意思,后面会详细表述)。假设你的数据如下:
| V1 | V2 | Y |
|---|---|---|
| 0.2 | 0.1 | 1 |
| 0.5 | 0.8 | 0 |
| 0.1 | 0.2 | 1 |
这个数据应该很容易懂,V1,V2是变量,Y是标签,每一行对应的一个样本,做机器学习的不可能看不懂这个,对吧?
好,接下来,你打算设计一个神经网络模型,于是你在草稿纸上设计了一下,像下面这个这样:

这是一个没有隐藏层、也没有偏置的神经网络结构,或许叫它神经网络不够严谨,但对于理解神经网络有非常重要的作用。
对应数据,图中的节点的意思是这样的:
V1 = [0.2, 0.5, 0.1];
V2 = [0.1, 0.8, 0.2];
写成向量的形式的话,应该是这样:
V 1 = [ 0.2 0.5 0.1 ] , V 2 = [ 0.1 0.8 0.2 ] V1 = \begin{bmatrix} 0.2 \\ 0.5 \\ 0.1\end{bmatrix}, V2 = \begin{bmatrix} 0.1 \\ 0.8 \\ 0.2\end{bmatrix} V1=⎣⎡0.20.50.1⎦⎤,V2=⎣⎡0.10.80.2⎦⎤
**重点声明,重点声明,重点声明:**一个节点表示一个向量,一层是多个节点组成的矩阵,一条黑线表示一个数字,每两层之间的黑线组成一个矩阵。
下面会同个一个比较详细的例子解释各个节点以及各条黑线之间的关系。
神经网络的原理
神经网络的原理其实很简单,就是反复进行这两个操作 前向传播→反向传播 ,下面详细说一下,如何前向传播和反向传播。
神经网络的前向传播
所谓神经网络的前向传播,其实是一系列计算公式而已,这里面有矩阵计算,也有数学计算。举个简单的栗子,你有三个这个的公式:
{ x = 1 x 1 = 2 x + 3 y = 2 x 1 2 \begin{cases} x = 1 \\ x_1 = 2x + 3 \\ y = 2x_1^2 \end{cases} ⎩⎪⎨⎪⎧x=1x1=2x+3y=2x12
如果我们输入 x = 1 x = 1 x=1 ,依次向前经过三个公式的运算,我们可以得到 y = 50 y=50 y=50 ;
如果我们输入 x = 2 x = 2 x=2 ,依次向前经过三个公式的运算,我们可以得到 y = 98 y=98 y=98 。
这个 y y y 就是 x x x 前向传播的结果,也就相当于神经网络的一次预测。我们根据 x x x 预测出了与 x x x 对应的 y y y 值。
下面进入正题,假设你的数据还是像上面那样,为了方便查看,我把它复制了下来:
| 1 | 2 | Y |
|---|---|---|
| 0.2 | 0.1 | 1 |
| 0.5 | 0.8 | 0 |
| 0.1 | 0.2 | 1 |
为了方便,我把 V1,V2 改成了 1,2。
下面这张神经网络结构图,是一个最简单的结构图。它包含一个输入层,一个隐藏层(是的,一个,你没看错),一个输出层。
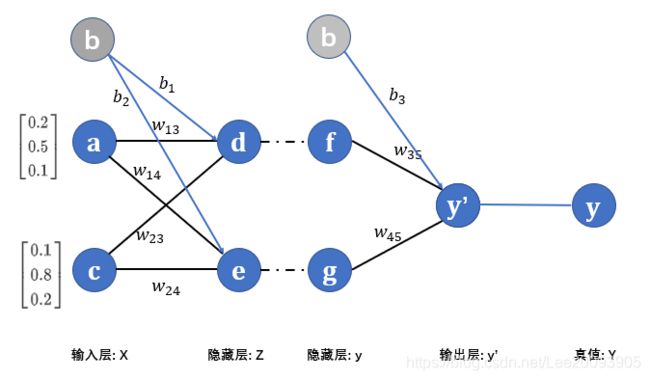
先解释图中字母的含义:
a,c 分别是输入层的两个节点,含义已经写在旁边。
d,e,f,g 是隐藏层的节点。注意都属于隐藏层,但是数据不一样,一个表示 z,一个表示 y,下面有提到他们之间的关系。
w ∗ w_{*} w∗ , b ∗ b_* b∗ 系列是指权重和偏置,他们分别代表一个数字,组合起来代表一个矩阵。比如: W 1 = [ w 13 w 23 w 14 w 24 ] = [ 1 2 4 2 ] W1 = \begin{bmatrix} w_{13} & w_{23} \\ w_{14} & w_{24} \end{bmatrix} = \begin{bmatrix} 1 & 2 \\ 4 & 2 \end{bmatrix} W1=[w13w14w23w24]=[1422] , W 2 = [ w 35 w 45 ] = [ 3 5 ] W2 = \begin{bmatrix} w_{35} \\ w_{45}\end{bmatrix} = \begin{bmatrix} 3 \\ 5\end{bmatrix} W2=[w35w45]=[35]
根据开始提的那个小栗子,那么在神经网络中的前向传播公式则是这样的:
{ X = [ a c ] z = W 1 ⋅ X T + b = [ w 13 w 23 w 14 w 24 ] ⋅ [ a c ] T + [ b 1 b 2 ] y = s i g m o i d ( z ) = 1 1 + e − z y ′ = W 2 ⋅ y + b = [ w 35 w 45 ] ⋅ [ y 1 y 2 ] + b 3 \begin{cases} X = \begin{bmatrix} a & c \end{bmatrix} \\ z = W1 · X^T + b = \begin{bmatrix} w_{13} & w_{23} \\ w_{14} & w_{24} \end{bmatrix} · \begin{bmatrix} a & c \end{bmatrix} ^ T + \begin{bmatrix} b_1 \\ b_2 \end{bmatrix}\\ y = sigmoid(z) = \frac{1}{1+e^{-z}} \\ y'= W2 · y + b= \begin{bmatrix} w_{35} & w_{45} \end{bmatrix} · \begin{bmatrix} y_1 \\ y_2 \end{bmatrix} + b_3 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧X=[ac]z=W1⋅XT+b=[w13w14w23w24]⋅[ac]T+[b1b2]y=sigmoid(z)=1+e−z1y′=W2⋅y+b=[w35w45]⋅[y1y2]+b3
叉会腰,公式敲得好累!!!!!
回到正题。跟上面的小栗子一样,依次按这四个公式进行运算,从 X X X 传播到最终的 y ′ y' y′ 就是我们所要求的。再次提醒一下,这里的 X X X 是一个 3×2 的矩阵, y ′ y' y′ 则是个 3×1 的向量,因为我们的输出层只有一个节点(神经元),还记得前面的吗?一个节点(神经元)表示一个向量。
神经网络的前向传播原理是:
- 第一步:线性变换
z = [ d e ] = W ⋅ X T + b = [ w 13 w 23 w 14 w 24 ] ⋅ [ a c ] T + [ b 1 b 2 ] = [ w 13 w 23 w 14 w 24 ] ⋅ [ 0.2 0.5 0.1 0.1 0.8 0.2 ] + [ b 1 b 2 ] z = \begin{bmatrix} d \\ e \end{bmatrix} = W · X^T + b = \begin{bmatrix} w_{13} & w_{23} \\ w_{14} & w_{24} \end{bmatrix} · \begin{bmatrix} a & c \end{bmatrix} ^ T + \begin{bmatrix} b_1 \\ b_2 \end{bmatrix} = \begin{bmatrix} w_{13} & w_{23} \\ w_{14} & w_{24} \end{bmatrix} ·\begin{bmatrix} 0.2 & 0.5 & 0.1 \\ 0.1 & 0.8 & 0.2 \end{bmatrix} + \begin{bmatrix} b_1 \\ b_2 \end{bmatrix} z=[de]=W⋅XT+b=[w13w14w23w24]⋅[ac]T+[b1b2]=[w13w14w23w24]⋅[0.20.10.50.80.10.2]+[b1b2]
注意上面的转置,以及向量的形式。由于我们的数据在csv里就是以列向量的形式存在的,所以我这里的写法和布局是按真实数据来的。这里得到的 [ d e ] \begin{bmatrix} d \\ e \end{bmatrix} [de] 是 2 × 3 的矩阵。
- 第二步:非线性变换
y = [ f g ] = s i g m o i d ( [ d e ] ) y = \begin{bmatrix} f \\ g \end{bmatrix} = sigmoid(\begin{bmatrix} d \\ e \end{bmatrix}) y=[fg]=sigmoid([de])
这里没有矩阵乘积的操作,就是对应元素应用到 s i g m o i d sigmoid sigmoid 函数。 s i g m o i d sigmoid sigmoid 函数的性质在这里我就赘述了,网上很多资料随便搜就搜得到。
同样,我们这里得到的 [ f g ] \begin{bmatrix} f \\ g \end{bmatrix} [fg] 是 2 × 3 的矩阵,
- 第三步:线性变换
y ′ = W 2 ⋅ y + b = [ w 35 w 45 ] ⋅ [ f g ] + b 3 y' = W2 · y + b= \begin{bmatrix} w_{35} & w_{45} \end{bmatrix} · \begin{bmatrix} f \\ g \end{bmatrix} + b_3 y′=W2⋅y+b=[w35w45]⋅[fg]+b3
这里,前面的 W 2 ⋅ y + b W2 · y + b W2⋅y+b 得到的是 1×3 的向量或矩阵(有个维度是1),而 b 3 b_3 b3 是一个数字,因此前面的没一个元素都要加 b 3 b_3 b3 。最终得到的向量就是输出节点,形似这样:
[ 3 5 1 ] \begin{bmatrix} 3 & 5 & 1 \end{bmatrix} [351]
-
第四步:非线性变换
同第二步。非线性变换的函数都叫激活函数,sigmoid 或者 softmax 或者其他,你会遇到很多种。
经过非线性变换(激活函数)后,数据变成这样:
[ 0.25 0.85 0.3 ] \begin{bmatrix} 0.25 & 0.85 & 0.3 \end{bmatrix} [0.250.850.3] -
第五步:计算损失
如果是回归任务,可以不做第四步,直接拿第三步的结果 y ′ y' y′ 与 真实的 y y y 计算 R M S E RMSE RMSE 或者 M S E MSE MSE 损失。
但如果是分类任务,则第四步的激活函数需要是 s i g m o i d sigmoid sigmoid(二分类)或者 s o f t m a x softmax softmax(多分类)。对于多分类,你的输出层 y ′ y' y′ 应该是长这样:
[ 2 3 3 4 6 5 ] \begin{bmatrix} 2 & 3 \\ 3 & 4 \\ 6 & 5 \end{bmatrix} ⎣⎡236345⎦⎤
经过第四步的激活函数后,变成这样:
[ 0.25 0.75 0.35 0.64 0.66 0.34 ] \begin{bmatrix} 0.25 & 0.75 \\ 0.35 & 0.64 \\ 0.66 & 0.34 \end{bmatrix} ⎣⎡0.250.350.660.750.640.34⎦⎤
s i g m o i d sigmoid sigmoid(二分类)或者 s o f t m a x softmax softmax(多分类)都有个共同的特点。就是每一行相加等于 1 1 1,里面的小数表示样本对应的类别的预测概率,如 0.75 0.75 0.75 表示第一个样本属于类别 1 1 1 的概率。由于输出节点为两个,所以这里损失函数并不能使用常见 M S E MSE MSE ,要使用交叉熵损失,具体怎么算就不写了,代码可以直接调用函数使用。不能自己按切片索引等方式取得对应的分类然后与真实值对比做 RMSE 损失计算,否则无法反向传播,无法更新参数,迭代训练。
到此,关于神经网络的前向传播已经解释清楚。
对于多个隐藏层的神经网络,就是重复第一步、第二步,每两步为一层。
神经网络的反向传播
前面已经说了前向传播,再复习一下,前向传播就是按每一层的权重矩阵和激活函数,依次往后计算,最后得到输出层矩阵。
在讲反向传播之前,我依然要拿前面的那个栗子出来,这次我们将公式稍微改动一下:
{ x = 1 x 1 = a ⋅ x + b y = c ⋅ x 1 2 \begin{cases}x = 1 \\x_1 = a·x + b \\y = c ·x_1^2 \end{cases} ⎩⎪⎨⎪⎧x=1x1=a⋅x+by=c⋅x12
现在我们让这些公式是系数变成 a , b , c a,b,c a,b,c 三个参数,他们就是我们所讲的需要训练的参数。一脸懵逼,对吗?别急,继续往下看。
神经网络的反向传播原理就是:由 y y y 分别对所有的参数求一阶偏导数。然后按梯度下降的公式,更改参数值,之后再前向传播,如此反复。
梯度下降的公式如下:
w = w − α ⋅ ∂ y ∂ w w = w - \alpha · \frac {\partial y}{\partial w} w=w−α⋅∂w∂y
α \alpha α 称为学习率,不用管什么意思,先知道它是一个小数就行,往往设置成 0.01 或者 0.001 等。
所谓反向传播更新梯度,其实就是求目标函数值 y y y 对所有参数的偏导数。下面依次求 y y y 对参数 a , b , c a, b,c a,b,c 的偏导数,根据链式求导法则,有:
∂ y ∂ a = ∂ y ∂ x 1 ⋅ ∂ x 1 ∂ a = 2 c x 1 ⋅ x \frac{\partial y}{\partial a} = \frac{\partial y}{\partial x_1} · \frac{\partial x_1}{\partial a} = 2cx_1 · x ∂a∂y=∂x1∂y⋅∂a∂x1=2cx1⋅x
这个公式一定要看明白,不然后面更弄不明白了,把上的分项拆开,得,
∂ y ∂ x 1 = c ⋅ 2 x 1 ∂ x 1 ∂ a = d x 1 d a = x \frac{\partial y}{\partial x_1} = c·2x_1\\ \frac{\partial x_1}{\partial a} = \frac{dx_1}{da} =x \quad \quad ∂x1∂y=c⋅2x1∂a∂x1=dadx1=x
更新梯度,现在更新参数 a a a ,
a = a − α ⋅ ∂ y ∂ a = a − α ⋅ ( 2 c ⋅ x 1 ⋅ x ) a=a-\alpha·\frac{\partial y}{\partial a} = a - \alpha · (2c·x_1·x) a=a−α⋅∂a∂y=a−α⋅(2c⋅x1⋅x)
式中 ‘=’ 号右边的 a , α , c a, \alpha, c a,α,c 都是初始参数, x x x 是输入变量, x 1 x_1 x1 是中间变量(也是已知的),故可以求得一个新的 a a a。
同理:
更新参数 b b b :
∂ y ∂ b = ∂ y ∂ x 1 ⋅ ∂ x 1 ∂ b = 2 c ⋅ x 1 ⋅ 1 b = b − α ⋅ ∂ y ∂ b = b − α ⋅ ( 2 c ⋅ x 1 ⋅ 1 ) \frac{\partial y}{\partial b} = \frac{\partial y}{\partial x_1}·\frac{\partial x_1}{\partial b} = 2c·x_1·1 \\ b = b - \alpha·\frac{\partial y}{\partial b} = b - \alpha·(2c·x_1·1) ∂b∂y=∂x1∂y⋅∂b∂x1=2c⋅x1⋅1b=b−α⋅∂b∂y=b−α⋅(2c⋅x1⋅1)
更新参数 c c c :
∂ y ∂ c = d y d c = x 1 2 c = c − α ⋅ ∂ y ∂ c = c − α ⋅ x 1 2 \frac{\partial y}{\partial c} = \frac{dy}{dc} =x_1^2\\ c = c - \alpha·\frac{\partial y}{\partial c} = c - \alpha·x_1^2 ∂c∂y=dcdy=x12c=c−α⋅∂c∂y=c−α⋅x12
更新好三个参数后,再传入 x x x ,作前向传播,如此往复。这个在代码当中就是等价于循环迭代,往复多少次就是迭代多少次。
上面这个栗子是为了帮助大家理解梯度是如何更新的,但是,但是,但是在实际当中,我们的 a , b , c , x , x 1 a,b,c,x,x_1 a,b,c,x,x1 等都是矩阵或者向量,这样一来求偏导的难度就增加了,因为要对矩阵中的每一个元素进行求导。
下面转载一篇文章,这个作者不仅些了理论,还写了个手动推导的实例,看完很是收益,我就是看这个看明白的。
前向传播算法(Forward propagation)与反向传播算法(Back propagation)
但是我有自己的实现代码,跟他的不一样,放上来仅供大家参考。此处转载,既是收藏,也是分享,如有侵权,联系删除。
# —*- coding: utf-8 -*-
"""
神经网络演示脚本,全线性函数,无激活函数,可解决回归问题
注意我这个是为了能让自己明白神经网络原理的代码,网络结构中没有 偏置项 b 和 激活函数。
我相信代码没几个人会自己研读,提几个注意点。
1、初始化矩阵的尺寸,要弄明白矩阵的位置和尺寸,是 w @ x, 还是 x @ w 还是w @ x.T?
2、反向求梯度时,也要弄明白矩阵乘积的摆放位置,所以为了能清楚,意见设置的权重矩阵 a×b中的a不等于b,这样方便观察是否需要转置?是几维的?
"""
import numpy as np
# ---------------------基于numpy实现BP----------------------------
def simulate(n, d, seed=25):
np.random.seed(seed)
x = np.random.randn(n, d).astype('float64')
y = BP(in_nodes=x.shape[1]).forward(x) + np.random.randn()
return x, y[0]
def mse(pre_y, y):
n = y.size
return np.sum((pre_y - y) ** 2) / n
class BP(object):
def __init__(self, in_nodes, hid_num=1, hid_nodes=3, out_nodes=1, lr=0.0001, iter=100000, w=None):
self.in_nodes = in_nodes
self.hid_num = hid_num
self.hid_nodes = hid_nodes
self.out_nodes = out_nodes
self.lr = lr
self.iter = iter
if w:
self.w = w
elif hid_num == 0:
self.w = [np.random.randint(1, 10, size=(out_nodes, in_nodes)).astype('float64')]
else:
w0 = np.random.randint(1, 10, size=(hid_nodes, in_nodes)).astype('float64')
self.w = [w0]
w1 = np.random.randint(1, 10, size=(out_nodes, hid_nodes)).astype('float64')
for i in range(hid_num - 1):
w = np.random.randint(1, 10, size=(hid_nodes, hid_nodes)).astype('float64')
self.w.append(w)
self.w.append(w1)
def forward(self, x):
z = x.T
for w in self.w:
z = w @ z
return z
def backward(self, x, y, y_pre):
self.grad = [0] * len(self.w)
n = x.shape[0]
# 记录前向传播的每一层的节点向量
x = x.T
z = [x]
for w in self.w:
x = w @ x
z.append(x)
# 反向迭代求梯度
w = np.eye(1)
for i in range(self.hid_num, -1, -1):
if i == self.hid_num:
w = np.eye(1)
else:
w = self.w[i + 1].T @ w
self.grad[i] = w * (2 / n) * ((y_pre - y) @ z[i].T) # 最难的是这一步,我手推了几张A4纸才找到这么个规律,类似与数学归纳法得出来的
def fit(self, x, y):
for i in range(self.iter):
# 前向传播
y_pre = self.forward(x)
# 计算损失
loss = mse(y_pre, y.reshape(y_pre.shape))
if loss < 1e-10:
print('iter: {}, w: {}, loss: {}'.format(i, self.w, loss))
break
if i == self.iter - 1:
print('iter: {}, w: {}, loss: {}'.format(i, self.w, loss))
# 反向传播
self.backward(x, y, y_pre)
# 更新权重
for j, _ in enumerate(self.w):
self.w[j] -= (self.lr * self.grad[j])
def predict(self, x):
return self.forward(x)
if __name__ == '__main__':
x, y = simulate(1000, 5)
bp = BP(in_nodes=x.shape[1], lr=0.00001)
bp.fit(x[:800,:], y[:800])
# print(bp.predict(x[800:, ]))
# print(y[800:])
print(bp.grad)
最后,反复研读此文,和文中的转载文章,并自己拿笔和纸手动推导一遍,至少能推1个隐藏层结构的,找出规律推广到多层,理解了之后,自己用代码去实现一次,只用一个numpy库。这么做,对于想要理解更难一点 CNN、RNN、LSTM 等神经网络结构有很大的帮助,毕竟这是基本功。