知识总结(14)Zabbix常见面试题汇总+zabiix与Nagios、Open-falcon的对比
目录
Zabbix
1.zabbix 是怎么实施监控的
【主动监测】通信过程
【被动监测】通信过程
zabbix 自定义发现是怎么做的
zabbix 是怎么微信报警的
zabbix 怎么开启自定义监控
zabbix 监控了多少客户端 客户端是怎么进行批量安装的
Nagios
Nagios的监控原理
Open-falcon
Open-falcon监控原理
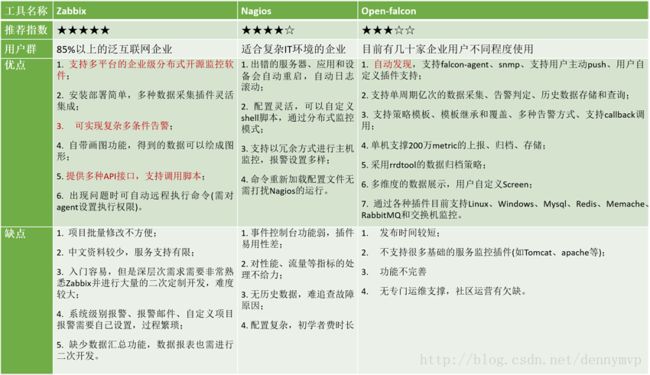
Zabbix、Nagios、Open-falcon的对比
Zabbix
1.zabbix 是怎么实施监控的
一个监控系统运行的大概的流程是这样的:
agentd需要安装到被监控的主机上,它负责定期收集各项数据,并发送到zabbix server端,zabbix
server将数据存储到数据库中,zabbix web根据数据在前端进行展现和绘图。这里agentd收集数据分为主动和被动两种模式:
主动:agent请求server获取主动的监控项列表,并主动将监控项内需要检测的数据提交给server/proxy
被动:server向agent请求获取监控项的数据,agent返回数据。
【主动监测】通信过程
zabbix首先向ServerActive配置的IP请求获取active items,获取并提交active
tiems数据值server或者proxy。很多人会提出疑问:zabbix多久获取一次active
items?它会根据配置文件中的RefreshActiveChecks的频率进行,如果获取失败,那么将会在60秒之后重试。分两个部分:
获取ACTIVE ITEMS列表
Agent打开TCP连接(主动检测变成Agent打开)
Agent请求items检测列表
Server返回items列表
Agent 处理响应
关闭TCP连接
Agent开始收集数据
主动检测提交数据过程如下:
Agent建立TCP连接
Agent提交items列表收集的数据
Server处理数据,并返回响应状态
关闭TCP连接
【被动监测】通信过程
Server打开一个TCP连接
Server发送请求agent.ping\n
Agent接收到请求并且响应
Server处理接收到的数据
关闭TCP连接
注意:
1、新建监控项目时,选择的是zabbix代理还是zabbix端点代理程式(主动式),前者是被动模式,后者是主动模式。
2、agentd配置文件中StartAgents参数的设置,如果为0,表示禁止被动模式,否则开启。一般建议不要设置为0,因为监控项目很多时,可以部分使用主动,部分使用被动模式。
zabbix 自定义发现是怎么做的
1、首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值。
2、过滤器中间要添加你需要的用到的值宏。
3、然后要创建一个监控项原型,也是一个名称和一个键值。
4、然后需要去写一个这样的键值的收集。
自动发现实际上就是需要首先去获得需要监控的值,然后将这个值作为一个新的参数传递到另外一个收集数据的item里面去。
zabbix 是怎么微信报警的
1、首先,需要有一个微信企业号。(一个实名认证的[微信号]一个可以使用的[手机号]一个可以登录的[邮箱号]
2、下载并配置微信公众平台私有接口。
3、配置Zabbix告警,(增加示警媒介类型,添加用户报警媒介,添加报警动作)。
zabbix 怎么开启自定义监控
1、写一个脚本用于获取待监控服务的一些状态信息。
2、在zabbix客户端的配置文件zabbix_agentd.conf中添加上自定义的“UserParameter”,目的是方便zabbix调用我们上面写的那个脚本去获取待监控服务的信息。
3、在zabbix服务端使用zabbix_get测试是否能够通过第二步定义的参数去获取zabbix客户端收集的数据。
4、在zabbix服务端的web界面中新建模板,同时第一步的脚本能够获取什么信息就添加上什么监控项,“键值”设置成前面配置的“UserParameter”的值。
5、数据显示图表,直接新建图形并选择上一步的监控项来生成动态图表即可。
zabbix 监控了多少客户端 客户端是怎么进行批量安装的
根据实际公司台数回答。
1、使用命令生成密钥。
2、将公钥发送到所有安装zabbix客户端的主机。
3、安装 ansible 软件,(修改配置文件,将zabbix 客户机添加进组)。
4、创建一个安装zabbix客户端的剧本。
5、执行该剧本。
6、验证。
Nagios
Nagios的监控原理
nagios的功能是监控服务和主机,但是它自身并不包括这部分功能,所有的监控,检测功能都是通过各种插件来完成的,启动nagios后,它会周期性的自动调用插件去检测服务器状态,同时nagios会维持一个队列,所有的插件返回来的信息状态都进入队列,nagios每次都从开始读取信息,并进行处理后,把状态结果通过web下次显示出来,nagios提供了许多插件,利用插件可以方便得监控很多服务器状态,安装完成后,在nagios主目录下的libexec里放油nagios自带的可以使用的所有插件,如,check_disk是检查磁盘空间的插件,check_load是检查cpu负载的,等等,每一个插件可以通过运行./check_xxx -h 来查看其使用的方法和功能。
nagios可以识别的状态有4种
0 (ok) 表示正常状态
1 (warning) 表示一定的异常
2 (critical) 出现严重的错误
3 (unkown) 被监控的对象已经停止了
nagios根据插件返回来的值,来判断被监控对象的状态,并通过web显示出来,以供管理员及时发现故障
Open-falcon
Open-falcon监控原理
每台服务器,都有安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计200多项指标。
只要安装了falcon-agent的机器,就会自动开始采集各项指标,主动上报,不需要用户在server做任何配置(这和zabbix有很大的不同),这样做的好处,就是用户维护方便,覆盖率高。当然这样做也会server端造成较大的压力,不过open-falcon的服务端组件单机性能足够高,同时都可以水平扩展,所以自动多采集足够多的数据,反而是一件好事情,对于SRE和DEV来讲,事后追查问题,不再是难题。
另外,falcon-agent提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
Zabbix、Nagios、Open-falcon的对比