【架构设计】分布式链路追踪理论(一)
0. 前言
微服务架构系统,每个用户请求往往涉及多个服务,且不同服务可能由不同团队开发,可能使用不同编程语言实现,还可能布在了横跨多个数据中心的几千台服务器上。在这种背景下,就需要一些能帮助理解系统行为、分析性能问题的工具,且在发生故障的时候能够快速定位和解决问题,这工具就是分布式追踪系统,也称为 APM(Application Performance Monitor) 系统。
最早的分布式追踪系统可以说就是 Google Dapper 了,Google 在 2010 年发表了《Dapper - a Large-Scale Distributed Systems Tracing Infrastructure》论文介绍了这个系统。虽然 Dapper 系统没有开源,但受该论文的启发,之后不断有团队研发出新的分布式追踪系统,比如阿里的 EagleEye、Twitter 的 Zipkin、大众点评的 CAT、京东的 Hydra、韩国的 PinPoint,Uber 的 Jaeger,还有由华为吴晟研发并在 2017 年加入 Apache 孵化器的 SkyWalking,等等。不过,这些名单中,EagleEye 没有开源,CAT 和 Hydra 早已停止维护。
另外,还有一个开源项目不得不提,那就是 OpenTracing。由于不同的分布式追踪系统的 API 不兼容,那如果需要切换追踪系统就需要做很大的改动,为了解决这个问题,就诞生了 OpenTracing。OpenTracing 并不是一个具体的分布式追踪实现系统,而只是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间,请看下图:
+-------------+ +---------+ +----------+ +------------+
| Application | | Library | | OSS | | RPC/IPC |
| Code | | Code | | Services | | Frameworks |
+-------------+ +---------+ +----------+ +------------+
| | | |
| | | |
v v v v
+------------------------------------------------------+
| OpenTracing |
+------------------------------------------------------+
| | | |
| | | |
v v v v
+-----------+ +-------------+ +-------------+ +-----------+
| Tracing | | Logging | | Metrics | | Tracing |
| System A | | Framework B | | Framework C | | System D |
+-----------+ +-------------+ +-------------+ +-----------+1. OpenTracing
OpenTracing 正在为全球的分布式追踪,提供统一的概念和数据标准。OpenTracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。其支持的语言已经包括了 Go、Java、JavaScript、Python、Ruby、PHP、C++、C#、Objective-C。兼容 OpenTracing 的 APM 也包括了 Jaeger、SkyWalking,还有其他项目,如 LightStep、Instana、Datadog、Elastic APM 等。
那么,分布式追踪系统这么多,目前也没有一枝独大,选型其实不太好做。我这里只提供一点我的见解。首先,我会倾向于选择兼容 OpenTracing 的,毕竟 OpenTracing 已经越来越受到开源和商业团队的追捧。其次,我会考虑社区的活跃度,优先选择活跃度高的,这从 Github 上的 Star 数就可以看出来。结合这两点,最后的选择只剩下 Jaeger 和 SkyWalking,两者都支持了多种语言,包括 Java、Go、C++ 等,也支持集成到服务网格 Istio + Envoy。要说差异点的话,可能 Jaeger 更多用于 Go 系,而 SkyWalking 则主要用于 Java 系。
- OpenTracing 官网:https://opentracing.io/docs/overview/
- github-opentracing-java :https://github.com/opentracing/opentracing-java
- opentracing 理论中文文档:https://wu-sheng.gitbooks.io/opentracing-io/content/
- opentracing-java使用官方文档:https://opentracing.io/guides/java/
随着并发和异步成为现代软件应用的必然特性,分布式追踪系统成为有效监控的一个必须的组成部分。尽管如此,监控并追踪一个系统的调用情况,至今仍是一个耗时而复杂的任务。随着系统的调用分布式程度(超过10个进程)和并发度越来越高,移动端与web端、客户端到服务端的调用关系越来越复杂,追踪调用关系带来的好处是显而易见的。但是选择和部署一个追踪系统的过程十分复杂。OpenTracing标准将改变这一点,OpenTracing尽力让监控一个分布式调用过程简单化。正如我下面视频演示的那样,你能在10分钟内快速配置一个监控系统。
试想一个简单的web网站。当用户访问你的首页时,web服务器发起两个HTTP调用,其中每个调用又访问了数据库。这个过程是否简单直白,我们可以不费什么力气就能发现请求缓慢的原因。如果你考虑到调用延迟,你可以为每个调用分布式唯一的ID,并通过HTTP头进行传递。如果请求耗时过长,你通过使用唯一ID来grep日志文件,发现问题出在哪里。现在,想想一下,你的web网站变得流行起来,你开始使用分布式架构,你的应用需要跨越多个机器,多个服务来工作。随着机器和服务数量的增长,日志文件能明确解决问题的机会越来越少。确定问题发生的原因将越来越困难。这时,你发现投入调用流程追踪能力是非常有价值的。
1.1 概念和术语
一个tracer过程中,各span的关系
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G 在 Span F 后被调用, FollowsFrom)
上述tracer与span的时间轴关系
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]- Traces:一个trace代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。一个trace可以认为是多个span的有向无环图(DAG)
- Spans:一个span代表系统中具有开始时间和执行时长的逻辑运行单元。span之间通过嵌套或者顺序排列建立逻辑因果关系。
- Logs:每个span可以进行多次Logs操作,每一次Logs操作,都需要一个带时间戳的时间名称,以及可选的任意大小的存储结构。
- SpanContext:每个span必须提供方法访问SpanContext。SpanContext代表跨越进程边界,传递到下级span的状态。(例如,包含
- Baggage:Baggage是存储在SpanContext中的一个键值对(SpanContext)集合。它会在一条追踪链路上的所有span内全局传输,包含这些span对应的SpanContexts。在这种情况下,"Baggage"会随着trace一同传播,他因此得名(Baggage可理解为随着trace运行过程传送的行李)。Baggage拥有强大功能,也会有很大的消耗。由于Baggage的全局传输,如果包含的数量量太大,或者元素太多,它将降低系统的吞吐量或增加RPC的延迟。
- Operation Names:span的操作名应该是一个抽象、通用的标识,能够明确的、具有统计意义的名称;更具体的子类型的描述,请使用Tags
例如,假设一个获取账户信息的span会有如下可能的名称:
| 操作名 | 指导意见 |
|---|---|
get |
太抽象 |
get_account/792 |
太明确 |
get_account |
正确的操作名,关于account_id=792的信息应该使用Tag操作 |
相关文章
- 参考来源:https://wu-sheng.gitbooks.io/opentracing-io/content/pages/spec.html
2.Jaeger
受到Dapper和OpenZipkin启发的Jaeger是由Uber Technologies作为开源发布的分布式跟踪系统。它用于监视和诊断基于微服务的分布式系统,包括:分布式上下文传播、分布式交易监控、性能/延迟优化。Uber在Uber上发表了一篇博客文章Evolving Distributed Tracing,其中他们解释了Jaeger在架构选择方面的历史和原因。Jaeger的创建者Yuri Shkuro还出版了《掌握分布式跟踪》一书,深入介绍了Jaeger设计和操作的各个方面,以及一般的分布式跟踪
- jaeger 官网:https://www.jaegertracing.io
- github-jaeger-java:https://github.com/jaegertracing/jaeger-client-java
- jaeger 使用文档:https://www.jaegertracing.io/docs/1.22/getting-started/
- jaeger-ui:https://github.com/jaegertracing/jaeger-ui
- jaeger-spring整合:https://github.com/opentracing-contrib/java-spring-cloud
2.1 jaeger 架构
Jaeger可以作为多合一二进制(其中所有Jaeger后端组件都在单个进程中运行)进行部署,也可以作为可扩展的分布式系统进行部署,如下所述。有两个主要的部署选项:
- 收集器正在直接写入存储。
- 收集者正在写信给Kafka作为初步缓冲。
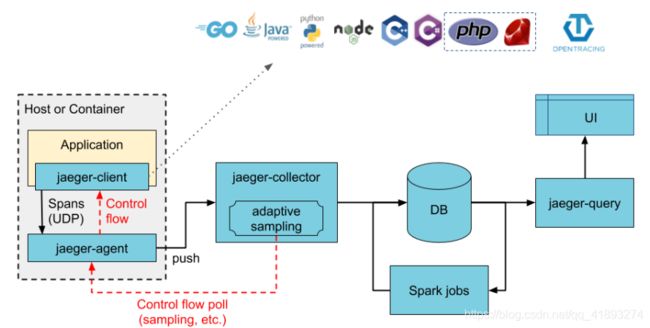
直接存储架构的插图 ,Kafka作为中间缓冲区的体系结构 [图片来源]
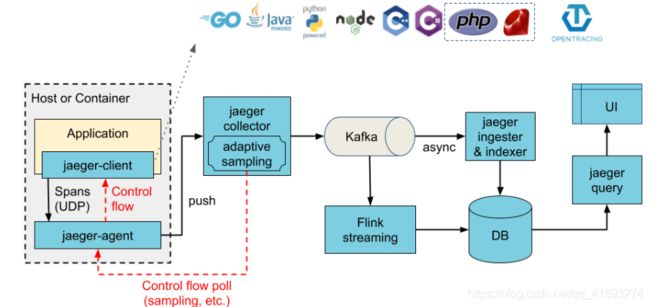
jaeger组件介绍:
- jaeger-client:jaeger 的客户端,实现了opentracing协议;
- jaeger-agent:jaeger client的一个代理程序,client将收集到的调用链数据发给agent,然后由agent发给collector;
- jaeger-collector:负责接收jaeger client或者jaeger agent上报上来的调用链数据,然后做一些校验,比如时间范围是否合法等,最终会经过内部的处理存储到后端存储;
- jaeger-query:专门负责调用链查询的一个服务,有自己独立的UI;
- jaeger-ingester:中文名称“摄食者”,可用从kafka读取数据然后写到jaeger的后端存储,比如Cassandra和Elasticsearch;
- spark-job:基于spark的运算任务,可以计算服务的依赖关系,调用次数等;
其中jaeger-collector和jaeger-query是必须的,其余的都是可选的,我们没有采用agent上报的方式,而是让客户端直接通过endpoint上报到collector。
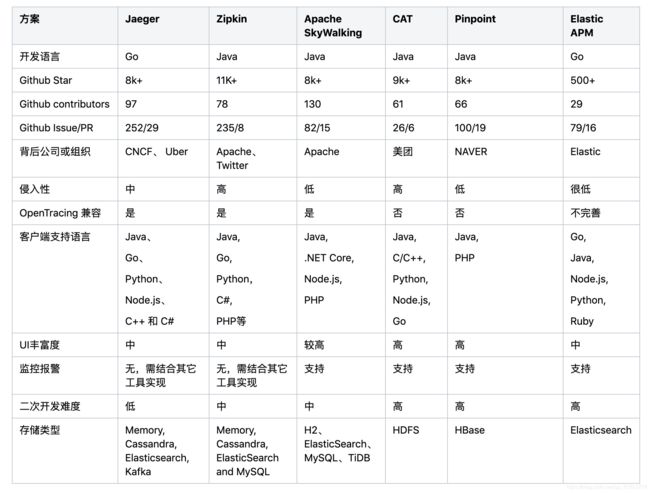
3. 目前主流开源方案及对比
目前比较主流的Tracing开源方案有Jaeger、Zipkin、Apache SkyWalking、CAT、Pinpoint、Elastic APM等,这些项目源代码现在都托管在Github上。
我们按照下面的维度进行了对比:
在现有系统引入时需要考虑以下因素:
- 低性能损耗
- 应用级的透明,尽量减少业务的侵入,目标是尽量少改或者不用修改代码
- 扩展性
基于以上调研,可以总结如下:
- 如果是偏向于
Java栈的应用,对跨语言和定制化需求低,可以优先考虑侵入性低的Apache SkyWalking,该项目是国人主导,有较多的公司在使用; - 考虑多语言支持、定制化和高扩展,优先选用
Jaeger(Jaeger与Zipkin比较类似,且兼容Zipkin原始协议,相比之下Jaeger有一定的后发优势),Jaeger和Zipkin相对于其它方案,更专注与Tracing本身,监控功能比较弱; - 偏向于纯Web应用,无需定制化且已经有搭建好的ELK日志系统可以考虑低成本的接入
Elastic APM; CAT基于日志全量采集指标数据,对于大规模的采集有一定优势,且集成了完善的监控报警机制,国内使用的公司多,但其不支持OpenTracing;Pinpoint最主要的特点是侵入性低,拥有完整的APM和调用链跟踪功能,但是当前仅支持Java和PHP,也不支持OpenTracing标准。