YOLOv4 目标检测详解【论文笔记 + pytorch实现 附.pth权重文件】
Contents
-
- 1 YOLOv4目标检测网络
-
- 1.1 主干特征提取网络BackBone
- 1.2 SPP部分
- 1.3 PANet
- 1.4 Yolo Head
- 2 检测一张图片
-
- 2.1 解码操作
- 2.2 非极大抑制剔除多余的框框
- 3 训练YOLOv4目标检测网络
-
- 3.1 YOLOv4的改进训练技巧
-
- a)、Mosaic数据增强
- b)、Label Smoothing平滑
- c)、边界框回归损失改为CIOU
- d)、学习率余弦退火衰减
- 3.2 损失函数解析
-
- a)、计算loss所需参数
- b)、y_pre是什么
- c)、y_true是什么
- d)、loss的计算过程
- 4 把需要的论文、代码和权重文件带走
YOLOv4相对于YOLOv3在各方面的细节上均做了完善,通过多方面对网络结构、训练tircks的实验对比,使得在精度即速度上又再次突破新高,堪称目标检测tricks万花筒,先给出论文中提到的YOLOv4到底干了个啥。

稍微总结一下YOLOv4改进的部分:
1、主干特征提取网络:DarkNet53 => CSPDarkNet53
2、特征金字塔:SPP,PAN
3、分类回归层:YOLOv3(未改变)
4、训练用到的小技巧:Mosaic数据增强、Label Smoothing平滑、CIOU、学习率余弦退火衰减
5、激活函数:使用Mish激活函数
以上并未列出全部的改进部分,还存在一些其它的改进。。。。
1 YOLOv4目标检测网络
对于YOLOv4的整个检测网络,当输入是416x416时,特征结构如下:
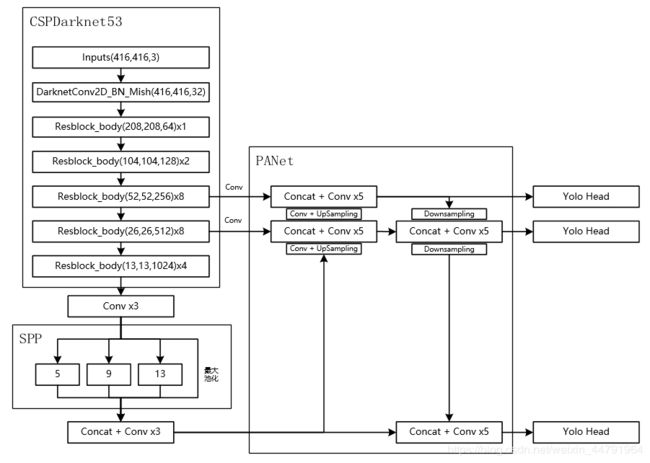
可以看到整个网络由四个部分组成,分别为CSPDarknet53、SPP、PANet和Yolo Head组成。接下来将对这四个部分进行详细介绍并附pytorch代码实现。
1.1 主干特征提取网络BackBone
YOLOv4中的主干特征提取网络相对于YOLOv3中的Darknet53主要做了两点改进。
- 将
Leaky_Relu()激活函数改为Mish()激活函数,Mish()激活函数的公式及图像如下。可以看到Mish()激活函数的正半轴与Leaky_Relu()激活函数的梯度相同;而Mish()激活函数的负半轴曲线梯度从(0, -∞)呈现由大到小的趋势。
Mish=x×tanh(ln(1+ex ))

class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x)) # F.softplus = ln(1+e^x)
- 结合了CSPNet结构,将Darknet53中进行堆叠的Res_Block做了修改,如下图所示。
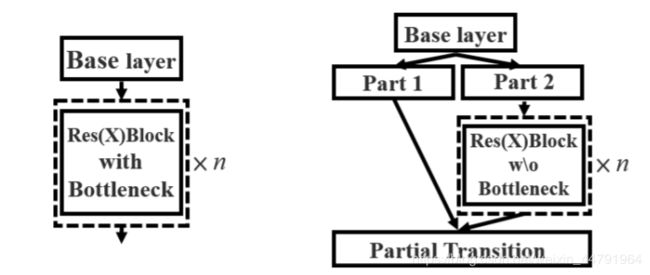
其中Part1 / Part2操作为对Base Layer进行一个1×1卷积,从Base Layer到Partial Transition的整个过程在代码中定义为Resblock_body类,其代码如下。
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = Mish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
#---------------------------------------------------#
# CSPdarknet的结构块的组成部分
# 内部堆叠的残差块
#---------------------------------------------------#
class Resblock(nn.Module):
def __init__(self, channels, hidden_channels=None, residual_activation=nn.Identity()):
super(Resblock, self).__init__()
if hidden_channels is None:
hidden_channels = channels
self.block = nn.Sequential(
BasicConv(channels, hidden_channels, 1),
BasicConv(hidden_channels, channels, 3)
)
def forward(self, x):
return x + self.block(x)
#---------------------------------------------------#
# CSPdarknet的结构块
# 存在一个大残差边
# 这个大残差边绕过了很多的残差结构
#---------------------------------------------------#
class Resblock_body(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, first):
super(Resblock_body, self).__init__()
# 首先降低特征图尺寸大小
self.downsample_conv = BasicConv(in_channels, out_channels, 3, stride=2)
if first:
self.split_conv0 = BasicConv(out_channels, out_channels, 1) # 对应CSPNet的part1 第一个Resnet_block, part1通道数保持不变
self.split_conv1 = BasicConv(out_channels, out_channels, 1) # 对应CSPNet的part2
# 1×1->3×3->1×1
self.blocks_conv = nn.Sequential(
Resblock(channels=out_channels, hidden_channels=out_channels//2),
BasicConv(out_channels, out_channels, 1)
)
# 简单堆叠后通道数翻倍, 通过1×1卷积保持原来的out_channels
self.concat_conv = BasicConv(out_channels*2, out_channels, 1)
else:
self.split_conv0 = BasicConv(out_channels, out_channels//2, 1) # 不是第一个Resnet_block, part1通过1×1卷积并将通道数减半
self.split_conv1 = BasicConv(out_channels, out_channels//2, 1)
self.blocks_conv = nn.Sequential(
*[Resblock(out_channels//2) for _ in range(num_blocks)],
BasicConv(out_channels//2, out_channels//2, 1)
)
self.concat_conv = BasicConv(out_channels, out_channels, 1)
def forward(self, x):
x = self.downsample_conv(x)
x0 = self.split_conv0(x)
x1 = self.split_conv1(x)
x1 = self.blocks_conv(x1)
x = torch.cat([x1, x0], dim=1)
x = self.concat_conv(x)
return x
1.2 SPP部分
SPP结构掺杂在对CSPdarknet53的最后一个特征层的卷积里,在对CSPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。

#---------------------------------------------------#
# SPP结构,利用不同大小的池化核进行池化
# 池化后堆叠
#---------------------------------------------------#
class SpatialPyramidPooling(nn.Module):
def __init__(self, pool_sizes=[5, 9, 13]):
super(SpatialPyramidPooling, self).__init__()
self.maxpools = nn.ModuleList([nn.MaxPool2d(pool_size, 1, pool_size//2) for pool_size in pool_sizes])
def forward(self, x):
features = [maxpool(x) for maxpool in self.maxpools[::-1]] # 13 9 5
features = torch.cat(features + [x], dim=1) # 13 9 5 1
return features
1.3 PANet
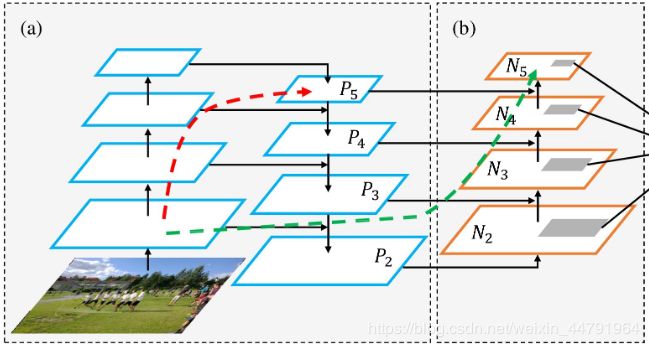
上图为原始的PANet的结构,可以看出来其具有一个非常重要的特点是对特征进行反复提取。在(a)中是传统的特征金字塔结构,在完成特征金字塔从下到上的特征提取后,还需要实现(b)中从上到下的特征提取。红色虚线表示原始图片通过传统金字塔结构得到的最小的特征图,绿色虚线表示原始图片通过PANet后得到的最小的特征图。
而在YOLOV4当中,其主要是在最后三个有效特征层上使用了PANet结构。
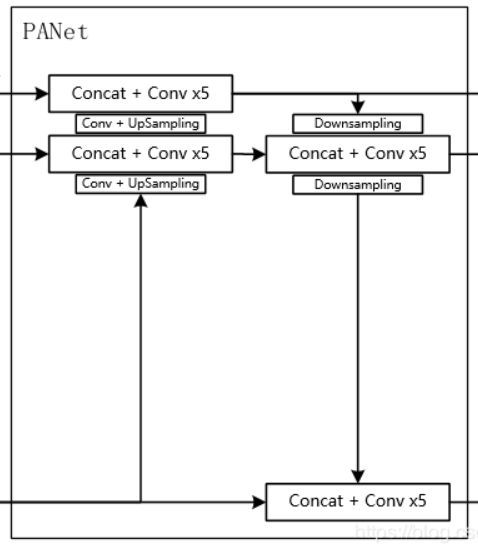
图中的Conv + UpSampling、DownSampling、Conv ×5等函数实现代码如下:
#---------------------------------------------------#
# 卷积 + 上采样
#---------------------------------------------------#
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upsample = nn.Sequential(
conv2d(in_channels, out_channels, 1),
nn.Upsample(scale_factor=2, mode='nearest')
)
def forward(self, x,):
x = self.upsample(x)
return x
#---------------------------------------------------#
# 三次卷积块
#---------------------------------------------------#
def make_three_conv(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
)
return m
#---------------------------------------------------#
# 五次卷积块
#---------------------------------------------------#
def make_five_conv(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
)
return m
1.4 Yolo Head
同YOLOv3中的网络结构中的Head一样,Head用于输出网络预测结果,Head提取多特征层进行目标检测,分别提取主干特征提取网络的最后三层特征,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024)。
输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,该数据集共有20个类别。YoloV4针对每一个特征层上的每个点存在3个先验框,所以最后维度为3x25;如果使用的是coco训练集,该数据集共有80个类别,最后的维度应该为3 x 85 = 255,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)。
Yolo Head及将以上四个模块组合起来的整个YOLOv4目标检测网络实现代码如下:
#---------------------------------------------------#
# 最后获得yolov4的输出
#---------------------------------------------------#
def yolo_head(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 3),
nn.Conv2d(filters_list[0], filters_list[1], 1),
)
return m
#---------------------------------------------------#
# yolo_body
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, num_anchors, num_classes):
super(YoloBody, self).__init__()
# backbone
self.backbone = darknet53(None)
self.conv1 = make_three_conv([512,1024],1024)
self.SPP = SpatialPyramidPooling()
self.conv2 = make_three_conv([512,1024],2048)
self.upsample1 = Upsample(512,256)
self.conv_for_P4 = conv2d(512,256,1)
self.make_five_conv1 = make_five_conv([256, 512],512)
self.upsample2 = Upsample(256,128)
self.conv_for_P3 = conv2d(256,128,1)
self.make_five_conv2 = make_five_conv([128, 256],256)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
# 4+1+num_classes
final_out_filter2 = num_anchors * (5 + num_classes)
self.yolo_head3 = yolo_head([256, final_out_filter2],128)
self.down_sample1 = conv2d(128,256,3,stride=2)
self.make_five_conv3 = make_five_conv([256, 512],512)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter1 = num_anchors * (5 + num_classes)
self.yolo_head2 = yolo_head([512, final_out_filter1],256)
self.down_sample2 = conv2d(256,512,3,stride=2)
self.make_five_conv4 = make_five_conv([512, 1024],1024)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter0 = num_anchors * (5 + num_classes)
self.yolo_head1 = yolo_head([1024, final_out_filter0],512)
def forward(self, x):
# backbone
x2, x1, x0 = self.backbone(x)
P5 = self.conv1(x0)
P5 = self.SPP(P5)
P5 = self.conv2(P5)
P5_upsample = self.upsample1(P5)
P4 = self.conv_for_P4(x1)
P4 = torch.cat([P4,P5_upsample],axis=1)
P4 = self.make_five_conv1(P4)
P4_upsample = self.upsample2(P4)
P3 = self.conv_for_P3(x2)
P3 = torch.cat([P3,P4_upsample],axis=1)
P3 = self.make_five_conv2(P3)
P3_downsample = self.down_sample1(P3)
P4 = torch.cat([P3_downsample,P4],axis=1)
P4 = self.make_five_conv3(P4)
P4_downsample = self.down_sample2(P4)
P5 = torch.cat([P4_downsample,P5],axis=1)
P5 = self.make_five_conv4(P5)
out2 = self.yolo_head3(P3)
out1 = self.yolo_head2(P4)
out0 = self.yolo_head1(P5)
return out0, out1, out2
2 检测一张图片
上一部分详细阐述了YOLOv4网络的搭建,这一部分总结对一张输入图片的预测过程:即对一张输入图片经过哪些操作最终可变为在原图上标注出预测框、预测类别及置信度。整个预测过程可分为9个步骤:
- 将输入图片Resize成416×416大小的图片(加灰条不失真Resize);
- 将图片形式转换为numpy数据形式,并将图片归一化(每个值除以255);
- 将numpy数据形式转换为torch的tensor形式(images = torch.from_numpy(images));
- 将Resize后的图片的tensor数据形式传入网络得到网络预测结果;
- 对预测结果进行解码;
- 对解码后的框进行非极大抑制操作;
- 过滤掉预测框中
有物体置信度 × 类型预测概率最大值 < 初始设置置信度的框; - 以上剩余的预测框及图片均是在图片Resize后且保留灰条的情况下存在的,需要将416×416的图片及预测框坐标尺寸均还原到原图像尺寸上;
- 在原图上画框,over!
下面对解码操作、非极大抑制操作附代码详细总结一下。
2.1 解码操作
前面提到,对于YOLOv4目标检测网络输入一张图片,网络输出三种大小的向量作为预测结果,对于输入416×416大小的图片(VOC数据集),网络预测输出为 13×13×75、26×26×75、52×52×75。已经非常熟悉,75 = 3 × 25 = 3 × (4 + 1 +20)。网络预测的结果并不对应着最终的预测框在图片上的位置,而是对应着对于每个先验框anchor中心坐标x, y、宽高w, h的调整参数以及anchor包含物体的置信度和对于每个类别的预测概率。需要把调整参数作用于先验框后的结果输出,这才会得到最终预测框在图片上的具体位置。
把网络输出的预测结果作用于先验框上的操作称为解码操作。实现代码如下。
class DecodeBox(nn.Module):
def __init__(self, anchors, num_classes, img_size): # img_size为主干特征提取网络图片大小,如 416
super(DecodeBox, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.img_size = img_size
def forward(self, input):
# input为bs,3*(1+4+num_classes),13,13
# 一共多少张图片
batch_size = input.size(0)
# 13,13
input_height = input.size(2)
input_width = input.size(3)
# 计算步长
# 每一个特征点对应原来的图片上多少个像素点
# 如果特征层为13x13的话,一个特征点就对应原来的图片上的32个像素点
# 416/13 = 32
stride_h = self.img_size[1] / input_height
stride_w = self.img_size[0] / input_width
# 把先验框的尺寸调整成特征层大小的形式
# 计算出先验框在特征层上对应的宽高
scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in self.anchors]
# bs,3*(5+num_classes),13,13 -> bs,3,13,13,(5+num_classes) 将先验框的参数信息放到最后一维度
prediction = input.view(batch_size, self.num_anchors,
self.bbox_attrs, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous()
# 先验框的中心位置的调整参数
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
# 先验框的宽高调整参数
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
# 获得置信度,是否有物体
conf = torch.sigmoid(prediction[..., 4])
# 种类置信度(e.g 20)
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
# 生成网格,先验框中心,网格左上角 batch_size,3,13,13
grid_x = torch.linspace(0, input_width - 1, input_width).repeat(input_width, 1).repeat(
batch_size * self.num_anchors, 1, 1).view(x.shape).type(FloatTensor)
grid_y = torch.linspace(0, input_height - 1, input_height).repeat(input_height, 1).t().repeat(
batch_size * self.num_anchors, 1, 1).view(y.shape).type(FloatTensor)
# 生成先验框的宽高
anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0])) # 1表示按列进行索引
anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1]))
anchor_w = anchor_w.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(w.shape)
anchor_h = anchor_h.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(h.shape)
_scale = torch.Tensor([stride_w, stride_h] * 2).type(FloatTensor)
output = torch.cat((pred_boxes.view(batch_size, -1, 4) * _scale,
conf.view(batch_size, -1, 1), pred_cls.view(batch_size, -1, self.num_classes)), -1)
return output.data
2.2 非极大抑制剔除多余的框框
当然得到解码后的预测结果后还要进行得分排序与非极大抑制筛选。这一部分基本上是所有目标检测通用的部分。不过YOLOv4的处理方式与其它网络不同:其对于每一个类进行判别,而其他网络大都是直接对框进行非极大抑制,并不考虑类别:
1、取出每一类得分大于self.obj_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
3 训练YOLOv4目标检测网络
3.1 YOLOv4的改进训练技巧
a)、Mosaic数据增强
Mosaic数据增强是在YOLOv4中提出来的,该方法参考了CutMix数据增强方式,CutMix数据增强方式利用两张图片进行拼接,而Mosaic数据增强利用了四张图片进行拼接。YOLOv4论文中提到Mosaic使得网络可以正常检测环境外部的物体,并且在BN计算的时候一下子会计算四张图片的数据,极大地减少了对于论文中提到的large mini-batch size的需求。
Mosaic数据增强具体解释传送门
b)、Label Smoothing平滑
#---------------------------------------------------#
# 平滑标签
#---------------------------------------------------#
def smooth_labels(y_true, label_smoothing, num_classes):
return y_true * (1.0 - label_smoothing) + label_smoothing / num_classes
其实Label Smoothing平滑就是将标签进行一个平滑,原始的标签是0、1(如果是二分类),当label_smoothing的值取0.01时,经过平滑后变成0.005、0.995,目的是让模型不可以分类的太准确,太准确容易导致过拟合。
c)、边界框回归损失改为CIOU
传统的目标检测使用的边界框回归损失采用均方差(Mean Square Error,MSE)的计算方法来得到,L1 和 L2 loss是将bbox四对坐标点分别求loss然后相加,但是这样仅考虑了四对坐标点的匹配程度,而并没有考虑先验框坐标之间的相关性,而实际评价指标IOU是具备相关性的。
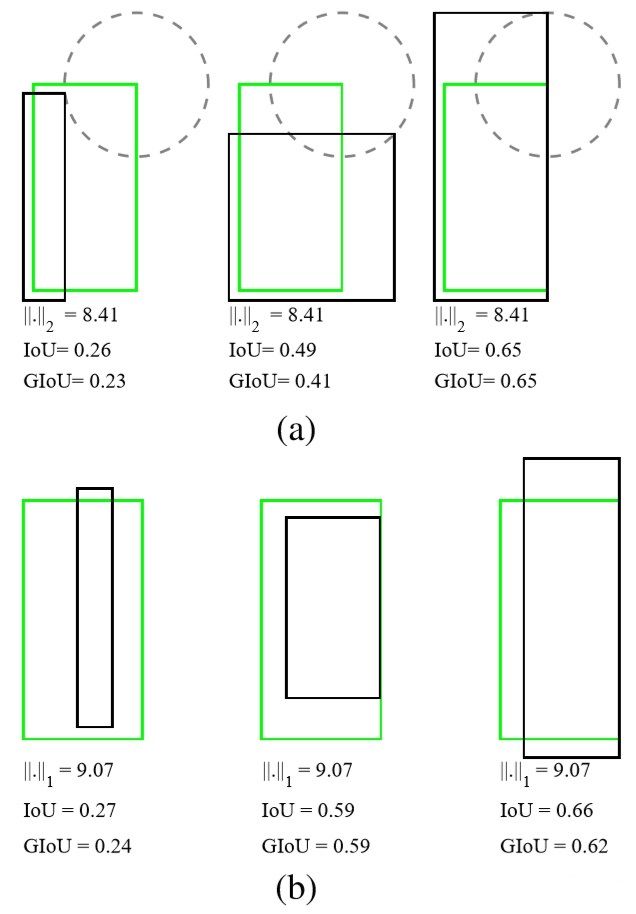
上图中,绿色框为真实框,黑色框为预测框。图(a)所有目标的L2 Loss都一样,但是第三个的IoU显然是要大于第一个,并且第3个的检测结果似乎也是优于第一个的。第二行类似,所有目标的L1 Loss都一样,但IoU却存在差异。因此使用预测框和真实框的L1、L2范数来计算边界框回归Loss以及在评测的时候却使用IoU去判断是否检测到目标,这两者并不等价。
此外,采用L1、L2 loss还有一个缺点是随着特征图的大小发生改变,计算出的loss也相应发生改变,也就是所说的scale variant representation;而IoU是比值的概念,具有尺度不变形。
于是有人提出直接使用IOU作为边界框优化回归损失,基于这种思想的方法有IOU、GIOU、DIOU、CIOU,这里简单介绍每一种的计算方法。
a)、经典IOU loss:
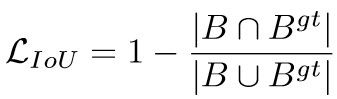
b)、GIOU:Generalized IOU
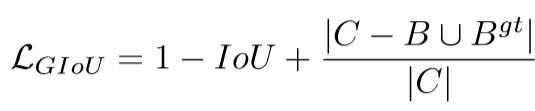
上式的C是指能包含predict box和Ground Truth box的最小box。
不过IOU和GIOU loss均不能对下面这三种情况能够区分开来,只有DIOU 和CIOU loss才能区分开来。
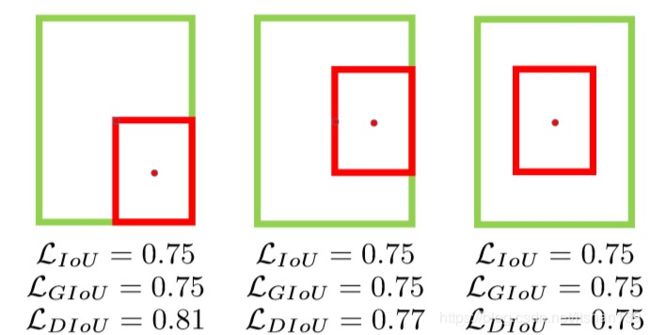
c)、DIOU loss:Distance IOU loss

这里的ρ2是指predict box和GT box中心点的距离的平方,c2而是指刚好能包含predict box和GT box的最小box的对角线长度平方。
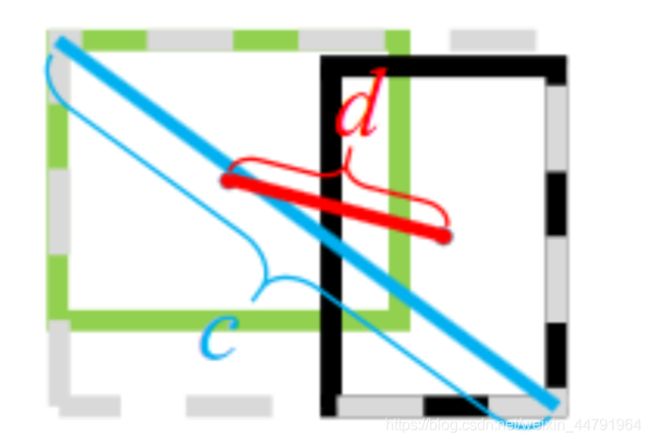
d)、CIOU Loss:Complete IOU loss:

公式中新增的αv项的计算公式如下:
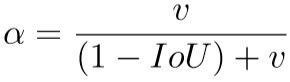

CIOU实现代码如下:
def box_ciou(b1, b2):
"""
输入为:
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
-------
ciou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
# 求出预测框左上角右下角
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# 求出真实框左上角右下角
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
# 求真实框和预测框所有的iou
intersect_mins = torch.max(b1_mins, b2_mins)
intersect_maxes = torch.min(b1_maxes, b2_maxes)
intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes))
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / torch.clamp(union_area, min=1e-6)
# 计算中心的差距
center_distance = torch.sum(torch.pow((b1_xy - b2_xy), 2), axis=-1)
# 找到包裹两个框的最小框的左上角和右下角
enclose_mins = torch.min(b1_mins, b2_mins)
enclose_maxes = torch.max(b1_maxes, b2_maxes)
enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes))
# 计算对角线距离
enclose_diagonal = torch.sum(torch.pow(enclose_wh, 2), axis=-1)
ciou = iou - 1.0 * (center_distance) / torch.clamp(enclose_diagonal, min=1e-6)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(b1_wh[..., 0]/torch.clamp(b1_wh[..., 1],min = 1e-6)) - torch.atan(b2_wh[..., 0]/torch.clamp(b2_wh[..., 1],min = 1e-6))), 2)
alpha = v / torch.clamp((1.0 - iou + v), min=1e-6)
ciou = ciou - alpha * v
return ciou
d)、学习率余弦退火衰减
之前遇到的绝大多数是手动调整学习率,而在这里使用到了学习率余弦退火衰减。pytorch库有直接实现的函数,可直接调用。
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
optimizer:需要进行学习率衰减的优化器变量
T_max:Cosine是个周期函数嘛,这里的T_max就是这个周期的一半,它表示学习率下降到最小值时的epoch数。如果你将T_max设置为10,则学习率衰减的周期是20个epoch,其中前10个epoch从学习率的初值(也是最大值)下降到最低值,后10个epoch从学习率的最低值上升到最大值
eta_min:学习率衰减时的最小值,默认值为0
last_epoch:(上次训练)最后一个epoch的索引值,默认值为-1
# optimizer学习率初值为0.0005,100个epoch,从第1个epoch(索引为0)开始训练
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=5e-6)
# 下图为对应的学习率变化曲线图

3.2 损失函数解析
a)、计算loss所需参数
在计算loss的时候,实际上是y_pre和y_true之间的对比:
y_pre就是一幅图像经过网络之后的输出,内部含有三个特征层的内容;其需要解码才能够在图上画出对应预测框;
y_true就是一个真实图像中,它的每个真实框对应的(19,19)、(38,38)、(76,76)网格上的偏移位置、长宽与种类。其仍需要编码才能与y_pred的结构一致。
b)、y_pre是什么
网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置调整参数、置信度及其种类。
对于输出的y1、y2、y3而言,[…, : 2]指的是相对于每个网格点的偏移量,[…, 2: 4]指的是宽和高,[…, 4: 5]指的是该框的置信度,[…, 5: ]指的是每个种类的预测概率。
注意!!!
网络直接输出的的y_pre还是没有解码的,解码之后才是显示在真实图像上的预测框。
c)、y_true是什么
y_true就是一个真实图像中,它的每个真实框对应在(19,19)、(38,38)、(76,76)的网格上的偏移距离、长宽与种类,其仍需要经过编码后才能与y_pred的结构一致。
d)、loss的计算过程
训练的目的是让预测框无限逼近真实框,在得到了y_pre和y_true后怎么对比处理呢?不是简单的减一下!学习过YOLOv3后,知道损失函数Loss由三个部分组成,分别为
(1)bounding box regression损失
(2)置信度损失
(3)分类损失
YOLOv4在YOLOv3的基础上,将YOLOv3中的bounding box regression损失用CIOU代替了MSE,其他两个部分没有做实质改变。
loss值需要对三个特征层进行处理;
a)、bounding box regression损失通过CIOU的方式计算,且只计算正样本的边界框回归loss;
b)、置信度loss由两部分构成,第一部分是实际上存在目标的,预测结果中置信度的值与1对比;第二部分是实际上不存在目标的,其与真实框的最大IOU的值与0对比;
c)、预测分类的loss,其计算的是预测结果中预测类型的值与1的对比,且只计算正样本的预测分类loss。
最终将3个loss进行求和,计算loss求和代码如下:
ciou = (1 - box_ciou(pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()])) * box_loss_scale[mask.bool()]
loss_loc = torch.sum(ciou / bs)
loss_conf = torch.sum(BCELoss(conf, mask) * mask / bs) + torch.sum(BCELoss(conf, mask) * noobj_mask / bs)
loss_cls = torch.sum(BCELoss(pred_cls[mask == 1], smooth_labels(tcls[mask == 1], self.label_smooth, self.num_classes))/bs)
loss = loss_conf * self.lambda_conf + loss_cls * self.lambda_cls + loss_loc * self.lambda_loc
4 把需要的论文、代码和权重文件带走
YOLOv4论文传送门
pytorch源码传送门
还是老样子,本文使用的网络 .pth权重文件 ,大小为244M,下载该权重文件放入对应文件夹model_data,即可直接对图片进行预测。
权重文件获取方式:关注【OAOA】回复【yolo4】即可获取。
参考博客
欢迎关注【OAOA】
