python爬虫代码实例源码_python各类爬虫案例,爬到你手软!
原标题:python各类爬虫案例,爬到你手软!
小编整理了一些爬虫的案例,代码都整理出来了~

先来看看有哪些项目呢:
python爬虫小工具(文件下载助手)
爬虫实战(笔趣看小说下载)
爬虫实战(VIP视频下载)
爬虫实战(百度文库文章下载)
爬虫实战(《帅啊》网帅哥图片下载)
爬虫实战(构建代理IP池)
爬虫实战(《火影忍者》漫画下载)
爬虫实战(财务报表下载小助手)
爬虫实战(抖音App视频下载)
爬虫实战(GEETEST验证码破解)
爬虫实战(12306抢票小助手)
爬虫实战(百万英雄答题辅助系统)
爬虫实战(网易云音乐批量下载)
爬虫实战(B站视频和弹幕批量下载)
爬虫实战(京东商品晒单图下载)
爬虫实战(正方教务管理系统爬虫)
怎么样?是不是迫不及待的想自己动手试试了呢?
在学习中有迷茫不知如何学习的朋友小编推荐一个学Python的学习q u n 227 -435- 450可以来了解一起进步一起学习!免费分享视频资料
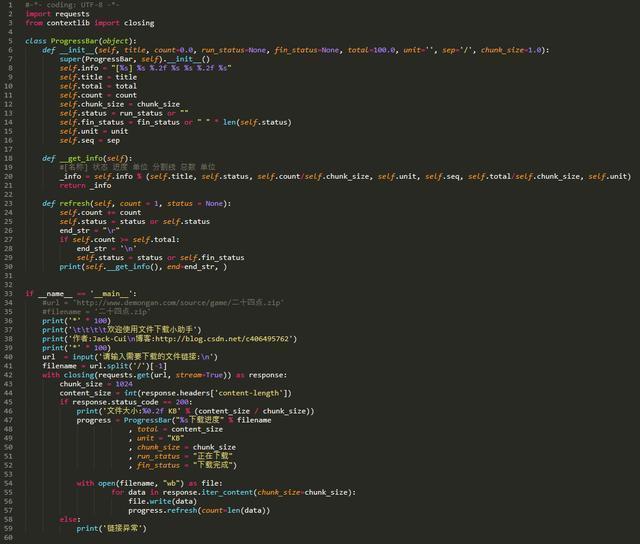
爬虫小工具
文件下载小助手
一个可以用于下载图片、视频、文件的小工具,有下载进度显示功能。稍加修改即可添加到自己的爬虫中。
代码展示:
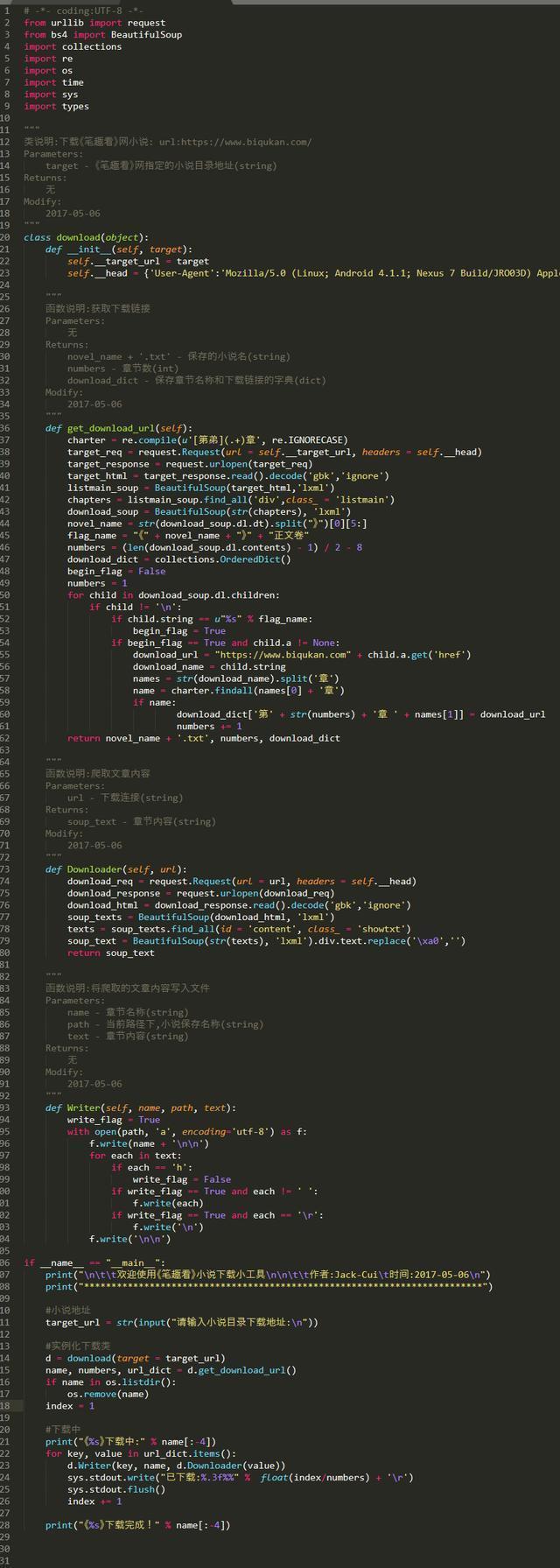
爬虫实战
《笔趣看》盗版小说网站,爬取小说工具
第三方依赖库安装:
pip3 install beautifulsoup4
使用方法:
python biqukan.py
代码展示:
爱奇艺等主流视频网站的VIP视频破解助手(暂只支持PC和手机在线观看VIP视频!)
运行源码需要搭建Python3环境,并安装相应第三方依赖库:
pip3 install -r requirements.txt
使用方法:
python movie_downloader.py
运行环境:
Windows, Python3
Linux, Python3
Mac, Python3
代码展示:

百度文库word文章爬取
代码不完善,没有进行打包,不具通用性,纯属娱乐,以后有时间会完善。
代码展示:

爬取《帅啊》网,帅哥图片
运行平台: Windows
Python版本: Python3.x
IDE: Sublime text3
为了也能够学习到新知识,本次爬虫教程使用requests第三方库,这个库可不是Python3内置的urllib.request库,而是一个强大的基于urllib3的第三方库。
代码展示:

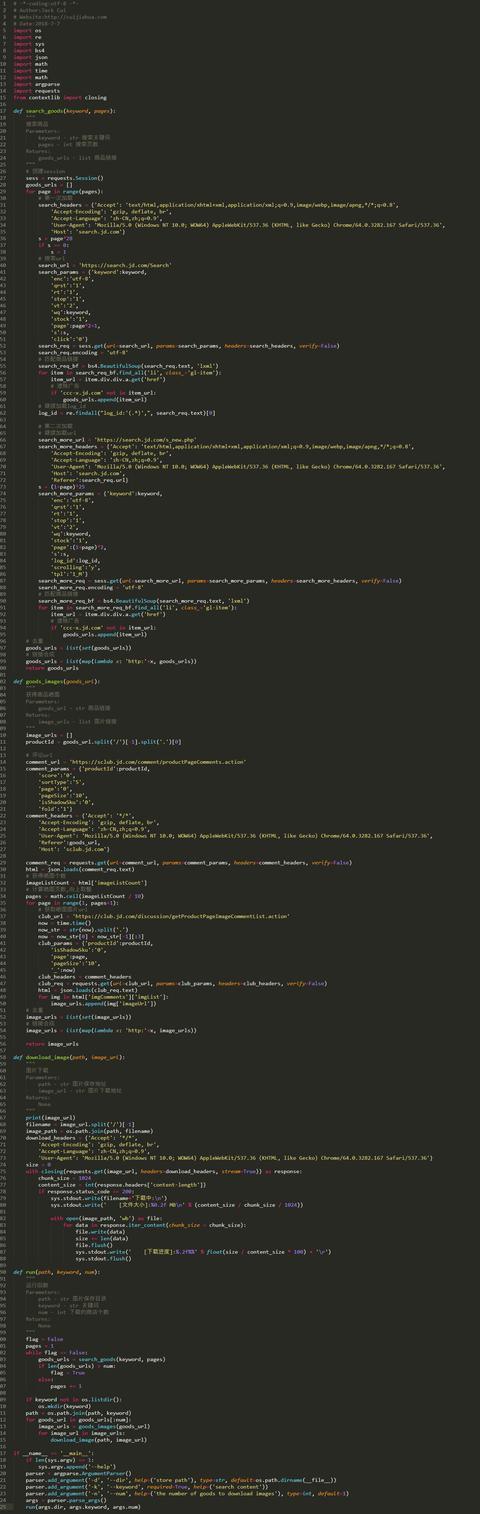
构建代理IP池
代码展示:

使用Scrapy爬取《火影忍者》漫画
代码可以爬取整个《火影忍者》漫画所有章节的内容,保存到本地。更改地址,可以爬取其他漫画。保存地址可以在代码中修改。
代码展示:

《王者荣耀》推荐出装查询小助手
网页爬取已经会了,想过爬取手机APP里的内容吗?
代码展示:

财务报表下载小助手
爬取的数据存入数据库会吗?《跟股神巴菲特学习炒股之财务报表入库(MySQL)》也许能给你一些思路。
代码展示:

抖音App视频下载
抖音App的视频下载,就是普通的App爬取。
代码展示:

GEETEST验证码破解
爬虫最大的敌人之一是什么?没错,验证码!Geetest作为提供验证码服务的行家,市场占有率还是蛮高的。遇到Geetest提供的滑动验证码怎么破?授人予鱼不如授人予渔,接下来就为大家呈现本教程的精彩内容。
代码展示:

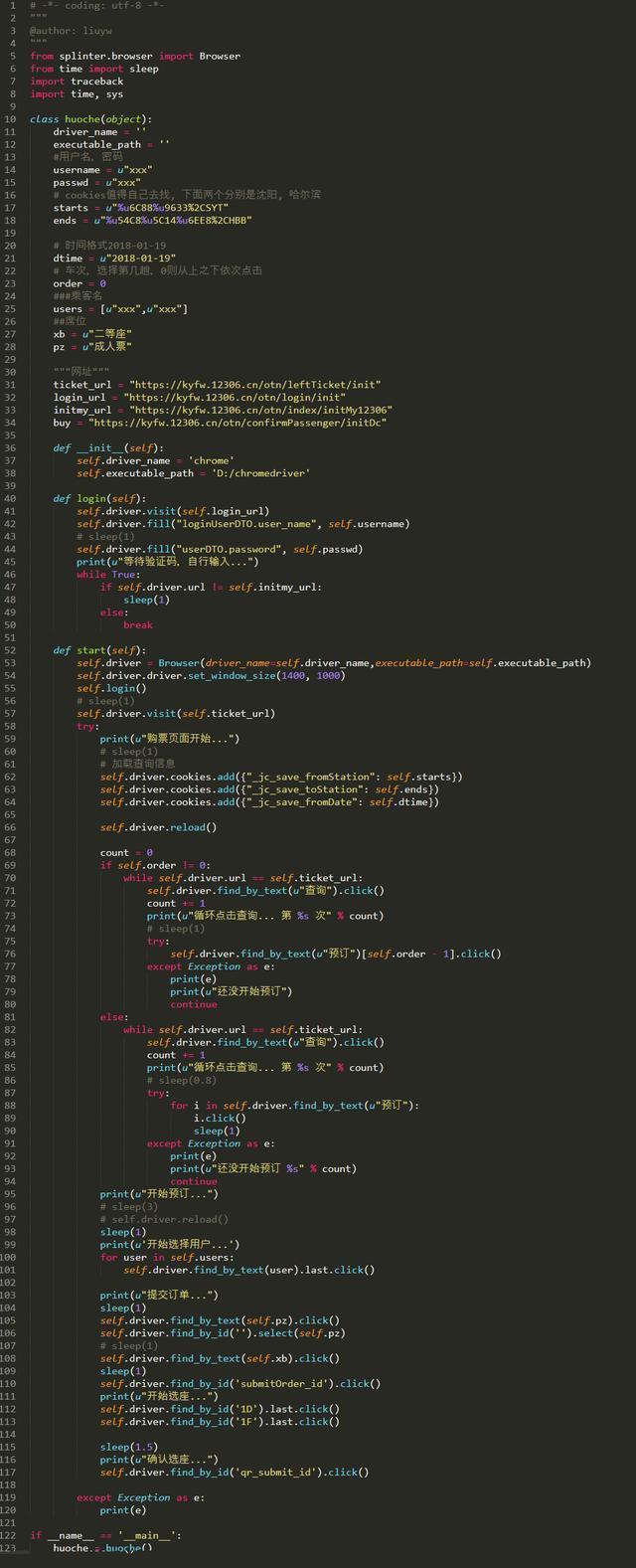
用Python抢火车票简单代码
可以自己慢慢丰富,蛮简单,有爬虫基础很好操作。
代码展示:

baiwan:百万英雄辅助答题
看了网上很多的教程都是通过OCR识别的,这种方法的优点在于通用性强。不同的答题活动都可以参加,但是缺点也明显,速度有限,并且如果通过调用第三方OCR,有次数限制。但是使用本教程提到的数据接口。我们能很容易的获取数据,速度快,但是接口是变化的,需要及时更新。
代码展示:
功能介绍:
服务器端,使用Python(baiwan.py)通过抓包获得的接口获取答题数据,解析之后通过百度知道搜索接口匹配答案,将最终匹配的结果写入文件(file.txt)。
Node.js(app.js)每隔1s读取一次file.txt文件,并将读取结果通过socket.io推送给客户端(index.html)。
亲测答题延时在3s左右。
声明:没做过后端和前端,花了一天时间,现学现卖弄好的,java也是现看现用,百度的程序,调试调试而已。可能有很多用法比较low的地方,用法不对,请勿见怪,有大牛感兴趣,可以自行完善。
Netease:根据歌单下载网易云音乐
功能介绍:
根据music_list.txt文件里的歌单的信息下载网易云音乐,将自己喜欢的音乐进行批量下载。
代码展示:

bilibili:B站视频和弹幕批量下载
下载B站视频和弹幕,将xml原生弹幕转换为ass弹幕文件,支持plotplayer等播放器的弹幕播放。
代码展示:

使用说明:
python bilibili.py -d 猫 -k 猫 -p 10
三个参数:
-d保存视频的文件夹名
-kB站搜索的关键字
-p下载搜索结果前多少页
京东商品晒单图下载
使用说明:
python jd.py -k 芒果
三个参数:
-d保存图片的路径,默认为fd.py文件所在文件夹
-k搜索关键词
-n 下载商品的晒单图个数,即n个商店的晒单图
代码展示:
对正方教务管理系统个人课表,学生成绩,绩点等简单爬取
依赖环境
python 3.6
python库
http请求:requests,urllib
数据提取:re,lxml,bs4
存储相关:os,sys
验证码处理:PIL
下载安装
在终端输入如下命令:
git clone [email protected]:Jack-Cherish/python-spider.git
使用方法
安装依赖包
pip install -r requirements.txt
运行
在当前目录下输入:
cd zhengfang_system_spider
python spider.py
运行爬虫,按提示输入学校教务网,学号,密码,输入验证码

稍等几秒钟,当前ZhengFang_System_Spider文件夹下就会生成zhengfang.txt
个人课表,成绩绩点均已保存到该文本文件中

代码展示:
责任编辑: