(计算机视觉实战)图片风格迁移
本文梳理图像迁移代码细节以及遇到的错误和处理方法:
首先和往常一样先导入辅助包:
import torch
from torch.autograd import Variable
from torchvision import transforms,datasets,models
import copy
import cv2
接下来选择两张图片作为风格图像和内容图像。
transform = transforms.Compose([transforms.Resize([224,224]),
transforms.ToTensor(),
])
image_sets = datasets.ImageFolder(root='pic_subject/content_',
transform = transform)
image_list = []
for i,image_ in enumerate(image_sets,1):
image_list.append(image_)
style_image = image_list[0][0].unsqueeze(0).clone()
content_image = image_list[1][0].unsqueeze(0).clone()
print('style_image.shape:',style_image.shape)
print('content_image.shape:',content_image.shape)
style_image = Variable(style_image).cuda()
content_image = Variable(content_image).cuda()
因为网络的创建基于VGG16,所以输入格式要满足VGG16的要求。在这里必须将图片的大改为[224,224],我使用的是imageloader的办法导入的图片,这个方法显然更适合导入大量的图片。虽然这里只有两张图片,但是在使用这个方法的时候遇到了以下问题:明明文件夹中有符合格式的图片,但是会得到以下报错:
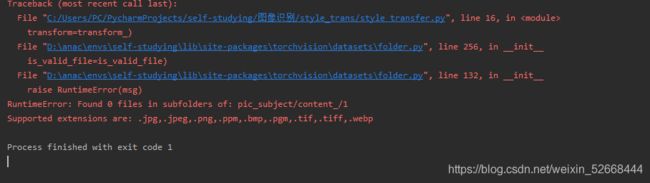
图片存储的路径结构如下图所示:
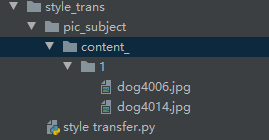
最初怀疑是自己的路径出现了问题,但是我使用一下代码确定,我所输入的路径是准确无误的:
print(os.listdir('pic_subject/content_/1'))
在查阅资料之后,解决办法是保持路径的结构不变,但是在ImageFolder函数中写入的路径是:
'pic_subject/content_'
问题得到完美解决:
transform_ = transforms.Compose([transforms.Resize([224,224]),
transforms.ToTensor()])
#load two pictures from disk
images = datasets.ImageFolder(root='pic_subject/content_',
transform=transform_)
print(images)
#输出:
'''
Dataset ImageFolder
Number of datapoints: 2
Root location: pic_subject/content_
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear)
ToTensor()
)
'''
导出图片之后,先将图片迁移至GPU上。
图像导入的时候还需要注意一点:两张图片的形状问题。直接使用上述方式将图片导入之后,图片的形状是由一个三维向量表示,但是后面的网络输入要求是个四维的向量(数量,通道数,宽,高)。
所以再图片导入完成之后,使用unsqueeze方法将可将图片形状更变成要求的形式。
风格迁移时的损失函数和以前直接使用随时函数有些许不同。不管是内容提取还是风格提取在这里都是使用的MSE误差函数,但是这里算的是原始输入图像乘以权重之后的值与网络输出乘以权重之后的误差。
因为涉及到不止一个损失函数,我们需要自己定义内容损失和风格损失。损失函数的定义逻辑如下如所示:

可以发现,内容损失,就是将提取出来的图片特征乘以内容权重与乘以内容权重的原图做MSEloss。
不同于的是,风格损失则先将提取的图片特征与原图变成格莱姆矩阵 G = A ∗ A T G=A *A^{T} G=A∗AT,格莱姆矩阵展示出了每一个特征之间的关系,可以用于表示图片的风格。
三个类的代码实现:
class Gram_matrix(torch.nn.Module):
def forward(self,input):
num,channel,width,height = input.size()
input = input.view(num*channel,width*height)
gram = torch.mm(input,input.t()).div(num*channel*width*height)
return gram
class Content_loss(torch.nn.Module):
def __init__(self,weight,extraction):
super(Content_loss, self).__init__()
self.weight = weight
self.extraction = self.weight * extraction.detach()
self.loss_funciton = torch.nn.MSELoss()
def forward(self,orig_img):
self.loss = self.loss_funciton(self.weight*orig_img.clone(),self.extraction)
return orig_img
def backward(self):
self.loss.backward(retain_graph =True)
return self.loss
class Style_loss(torch.nn.Module):
def __init__(self,weight,extraction):
super(Style_loss, self).__init__()
self.weight = weight
self.extraction = extraction.detach() * self.weight
self.loss_function = torch.nn.MSELoss()
self.gram = Gram_matrix()
def forward(self,input):
Gram_style_img = self.gram(input.clone()) * self.weight
self.loss = self.loss_function(Gram_style_img,self.extraction)
return input
def backward(self):
self.loss.backward(retain_graph =True)
return self.loss
上述代码使用detach的目的,是为了将提取到的图片特征从计算图中移除,也就是说它们不参与反向传播。定义完成之后,就可以搭建风格迁移网络了。
#tranfer VGG16net
VGG16 = models.vgg16(pretrained=True).features.cuda()
#define which layer is responsible for extracting content and which is for style
style_extractor = ['Conv_1','Conv_2','Conv_3','Conv_4'] #在这几个卷积层做风格提取
content_extractor = ['Conv_3'] #在这一层做内容提取
VGG16 = copy.deepcopy(VGG16)
My_model = torch.nn.Sequential().cuda() #创建自己的model,并将其移动到GPU上
My_model = copy.deepcopy(My_model)
index_ = 1
content_weight = 1
style_weight = 1000
content_loss_list = [] #用于记录内容损失
style_loss_list = [] #用于记录风格损失
gram = Gram_matrix()
创建网络的过程比较容易,只需按层添加,并收集损失。
for layer in list(VGG16)[:8]:
print(My_model)
print('-----'*10)
if isinstance(layer,torch.nn.Conv2d):
name = 'Conv_'+str(index_)
My_model.add_module(name,layer)
if name in content_extractor:
content_extraction = My_model(content_image.clone())
content_loss_ = Content_loss(content_weight,content_extraction)
My_model.add_module('content_loss_'+str(index_),content_loss_)
content_loss_list.append(content_loss_)
if name in style_extractor:
style_extraction = My_model(style_image.clone())
style_extraction = gram(style_extraction)
style_loss_ = Style_loss(style_weight,style_extraction)
My_model.add_module('style_loss_' + str(index_), style_loss_)
style_loss_list.append(style_loss_)
if isinstance(layer,torch.nn.ReLU):
My_model.add_module('Relu_'+str(index_),layer)
index_ += 1
if isinstance(layer,torch.nn.MaxPool2d):
My_model.add_module('Max_pooling_'+str(index_),layer)
在创建网络是我所遇到的问题:
因为图像风格迁移会涉及到多个损失函数,在做反向传播的时候会用到之前的结果,所以必须在调用backward()的时候声明,regain_graph = True, 不然会出现以下报错:

如果想要将模型迁移至GPU,一定要注意两点,首先,在迁移VGG16的时候就要先将它迁移至GPU中,其二,要在使用optimizer之前调用cuda,因为调用cuda之后的模型参数会出现改变。如果迁移的VGG16没有迁移至GPU,而新的模型迁移了,就用出现以下的报错:

训练过程与单一损失函数有所差异:
epoch = [0]
n_epoch = 300
while epoch[0] < n_epoch:
def closure():
optimizer.zero_grad()
content_score = 0
style_score = 0
My_model(parameter)
for style_loss in style_loss_list:
style_score+=style_loss.backward()
for content_loss in content_loss_list:
content_score+=content_loss.backward()
epoch[0]+=1
print(f'epoch:{epoch[0]},content_score:{content_score},style_score:{style_score}')
return style_score + content_score
optimizer.step(closure)
遇到类似的多个损失函数的情况,优化器的使用不再是直接调用,而是要写一个closure函数,来帮助优化器多次的计算梯度。
只需将收集到的损失进行反向传播,最后在一起更新梯度,其余和一般的训练过程大同小异。
在展示结果的时时候,如果使用了GPU,应首先将图片从GPU中移动至CPU中才可以正常绘图。
content_image = content_image.cpu().squeeze(0)
style_image = style_image.cpu().squeeze(0)
parameter = parameter.cpu().squeeze(0)
print(style_image.shape)
imshow_content_img = content_image.numpy().transpose([1,2,0])
imshow_style_img = style_image.numpy().transpose([1,2,0])
parameter = parameter.detach().numpy().transpose([1,2,0])
cv2.imshow('content_img',imshow_content_img)
cv2.imshow('style_img',imshow_style_img)-
cv2.imshow('result',parameter)
cv2.waitKey()
网络输出:
