原文链接:http://tecdat.cn/?p=23934
引言
在本文中,我们将尝试为苹果公司的日收益率寻找一个合适的 GARCH 模型。波动率建模需要两个主要步骤。
- 指定一个均值方程(例如 ARMA,AR,MA,ARIMA 等)。
- 建立一个波动率方程(例如 GARCH, ARCH,这些方程是由 Robert Engle 首先开发的)。
要做(1),你需要利用著名的Box-Jenkins方法,它包括三个主要步骤。
- 识别
- 估算
- 诊断检查
这三个步骤有时会有不同的名称,这取决于你读的是谁的书。在本文中,我将更多地关注(2)。
我将使用一个名为quantmod的软件包,它代表量化金融建模框架。这允许你在R中直接从各种在线资源中抓取金融数据。
#install.packages("quantmod") -需要先安装该软件包
getSymbols(Symbols = "AAPL",
src="yahoo", #其他来源包括:谷歌、FRED等。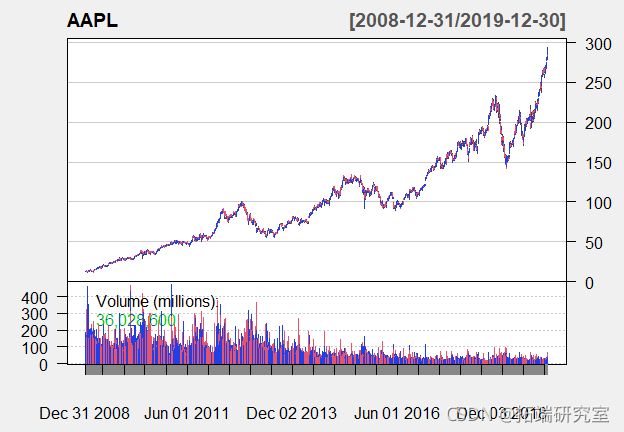
收益通常有一个非常简单的平均数方程,这导致了简单的残差。
![]()
我们首先要测试序列依赖性,这是条件异方差的一个指标(序列依赖性与序列相关不同)。这是通过对原始序列的平方/绝对值进行测试,并使用Ljung和Box(1978)的Ljung-Box测试等联合假设进行测试,这是一个Portmentau检验,正式检验连续自相关,直到预定的滞后数,如下所示。

其中T是总的周期数,m是你要测试的序列相关的滞后期数,ρ2k是滞后期k的相关性,Q∗(m)∼χ2α有m个自由度。
检查
下面是AAPL对数收益时间序列及其ACF,这里我们要寻找显著的滞后期(也可以运行pacf)或存在序列自相关。
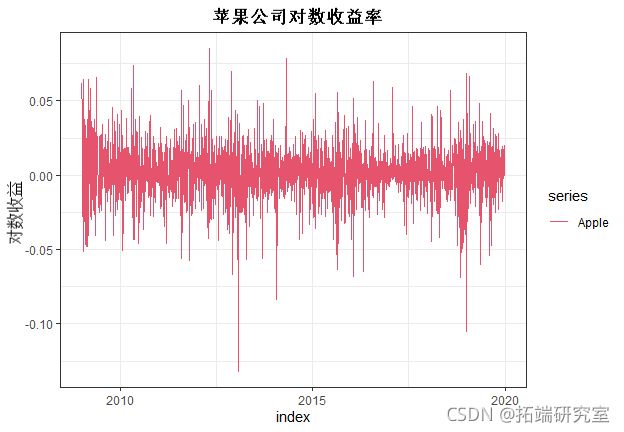
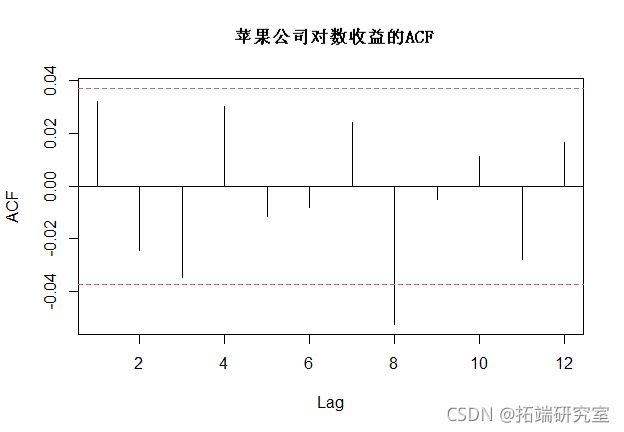
通过观察ACF,水平序列(对数收益)并不是真正的自相关,但现在让我们看一下平方序列来检查序列依赖性。
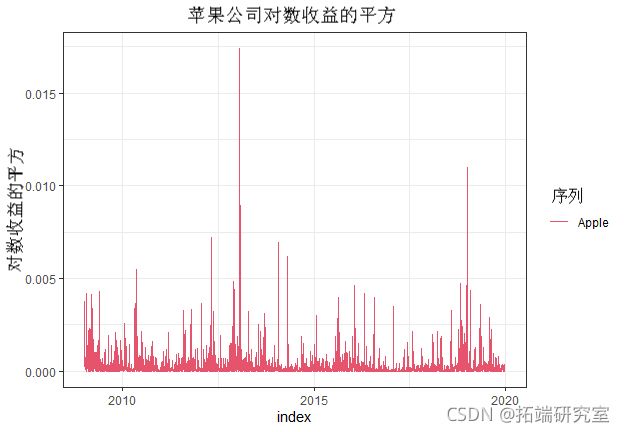
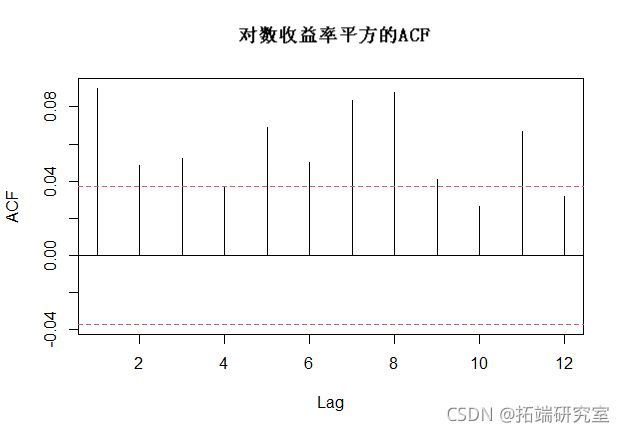
我们可以看到,平方序列的ACF显示出显著的滞后。这是一个信号,说明我们应该在某个时候测试ARCH效应。
平稳性
我们可以看到,AAPL的对数回报在某种程度上是一个平稳的过程,所以我们将使用Augmented Dicky-Fuller检验(ADF)来正式检验平稳性。ADF是一个广泛使用的单位根检验,即平稳性。我们将使用12个滞后期,因为根据文献的建议,我们有每日数据。 何:存在单位根(系列是非平稳的
##
## Title:
## Augmented Dickey-Fuller Test
##
## Test Results:
## PARAMETER:
## Lag Order: 12
## STATISTIC:
## Dickey-Fuller: -14.6203
## P VALUE:
## 0.01
##
## Description:
## Mon May 25 16:45:37 2020 by user: Florian上面的P值为0.01,表明我们应该拒绝Ho,因此,该系列是平稳的。
结构突变_检验_
请注意,我从2008年底开始研究APPL序列。以避免08年大衰退,通常会在数据中产生结构性突变(即趋势的严重下降/跳跃)。我们将对结构性突变/变化进行Chow测试。 AAPL的日收益率没有结构性突变

该图显示,用于估计断点(BP)数量的BIC(黑线)是BIC线的最小值,所以我们可以确认没有结构性断点,因为最小值是零,即零断点。在预测时间序列时,断点非常重要。
估计
在这一节中,我们试图用auto.arima命令来拟合最佳arima模型,允许一个季节性差异和一个水平差异。
正如我们所知,{Yt}的一般ARIMA(p,d,q)。
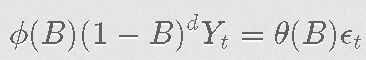
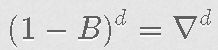
根据auto.arima,最佳模型是ARIMA(3,0,2),平均数为非零,AIC为-14781.55。我们的平均方程如下(括号内为SE)。

Auto.arima函数挑选出具有最低AIC的ARIMA(p,d,q),其中。
![]()
其中Λθ是观察到的数据在参数的mle的概率。因此,如果Auto.arima函数运行N模型,其决策规则为AIC∗=min{AICi}Ni=1
诊断检查
我们可以看到,我们的ARIMA(3,0,2)的残差是良好的表现。它们似乎也有一定的正态分布
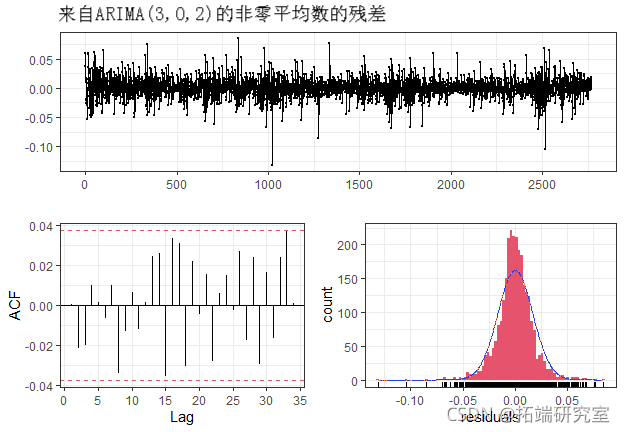
##
## Ljung-Box test
##
## data: Residuals from ARIMA(3,0,2) with non-zero mean
## Q* = 6.7928, df = 4, p-value = 0.1473
##
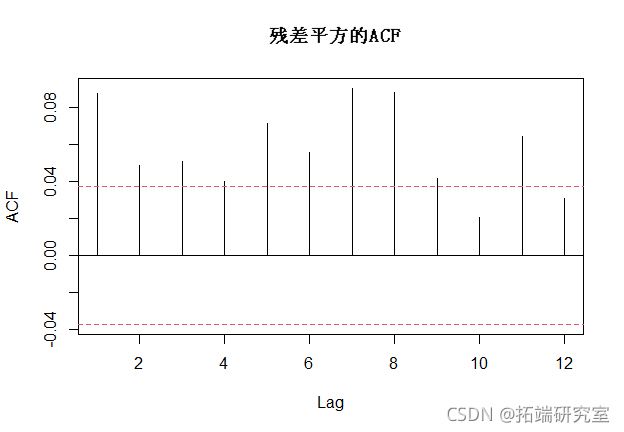
## Model df: 6. Total lags used: 10现在我们将通过对我们的ARIMA(3,0,2)模型的平方残差应用Ljung-Box测试来检验ARCH效应。
##
## Box-Ljung test
##
## data: resid^2
## X-squared = 126.6, df = 12, p-value < 2.2e-16我们可以看到,残差平方的 ACF 显示出许多显著的滞后期,因此我们得出结论,确实存在 ARCH 效应,我们应该对波动率进行建模。
使用 GARCH 建立波动率模型
上面将我们的平均数方程中的残差进行了平方,看看大的冲击是否紧随在其他大的冲击之后(无论哪个方向,即负的或正的),如果是这样,那么我们就有条件异方差,意味着我们有需要建模的非恒定方差。下面是一个GARCH(m,s)的样子。
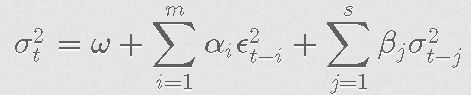
其中{ϵ2t}mt=1是我们通常的特异性冲击,iid随机变量,即ϵ2t∼WN(0,σ2ϵ)。我们可以更紧凑地写成:
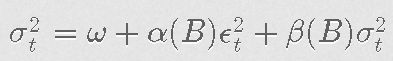
其中B是标准的后移算子Biϵ2t=ϵ2t-i,Biσ2t=σ2t-i。对于任何整数ii,以及α和β分别是度数为m和s的多项式
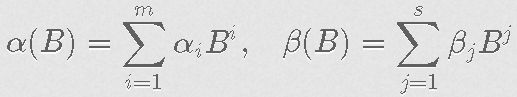
请注意,一个特殊情况是当s=0时,GARCH(m,0)被称为ARCH(m)。
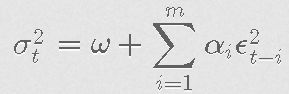
当我说GARCH家族时,它表明模型有变化。
- SGARCH。普通GARCH
- EGARCH。指数GARCH,允许波动率不为负值(这迫使模型只输出正方差
- FGARCH。这是为长记忆模型准备的。它使用了被称为 ARFIMA 的 Fractionaly integrated ARIMA(即非整数整合)。
- GARCH-M:这是GARCH的均值,适合你的均值方程中有波动率例如CAPM的方程中有σ。
- GJR-GARCH。假设负面冲击和正面冲击之间存在不对称性(金融数据几乎都是这样)。
为收益率序列建立波动率模型包括四个步骤:
- 通过测试数据中的序列依赖性来指定一个均值方程,如果有必要,为收益序列建立一个 计量经济学模型(例如,ARIMA 模型)来消除任何线性依赖。
- 使用平均值方程的残差来测试ARCH效应。
- 如果ARCH效应在统计上是显著的,就指定一个波动率模型,并对均值和波动率方程进行联合估计。
- 仔细检查拟合的模型,必要时对其进行改进。
一个简单的 GARCH 模型有以下成分。
均值: ![]()
波动率方程: 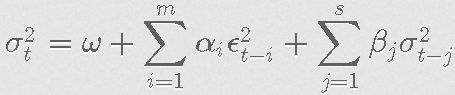
误差假设: ![]()
#以下命令将计算GARCH(m,s)。请记住,对于某些m和s的组合,它可能不会收敛。
garchlist(model="sGARCH", #其他选项有egarch, fgarch等。
garchOrder=c(1,2)), #你可以在这里修改GARCH(m,s)的阶数
mean.model , #指定你的ARMA模型,暗示你的模型应该是平稳的。
distribution.model #其他分布是 "std "代表t分布,"ged "代表一般误差分布我们的波动率方程由GARCH(1,2)给出,AIC:-5.5277(注意GARCH可能无法收敛)。

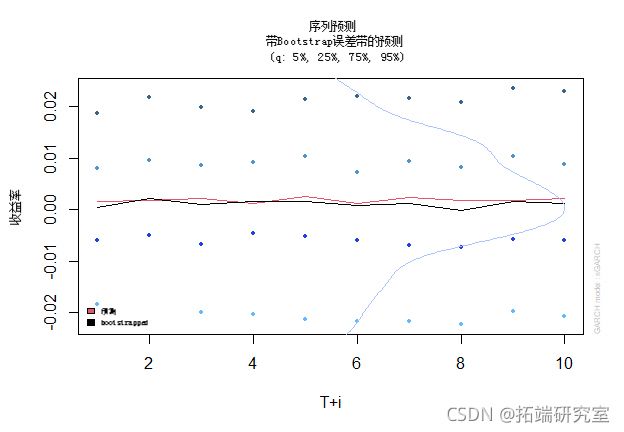
下面是使用我们的波动率模型对波动率进行的预测。这看起来是一个合理的波动率预测,但是你想改进你的模型。
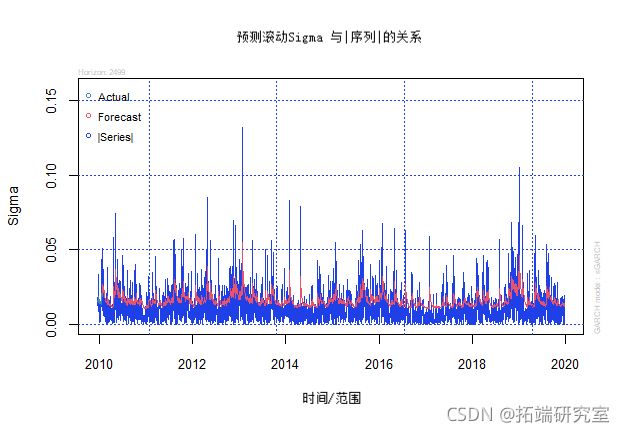
现在让我们使用rugarch的标准功能,使用估计的GARCH(1,2)模型来产生σt的滚动预测,并将它们与|rt|作对比。
最后,我们可以手动编写代码来查看随时间变化的波动率和对数收益率rt,如下图。
# 这将有助于在对数收益率上绘制sigma随时间变化的图。
sigma.t #这是你的波动率序列
ggplot()
geom_line(aes(x=as.numeric(
theme_bw()+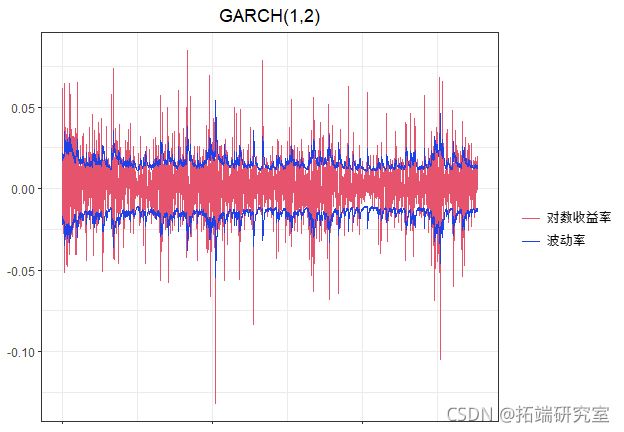
结论
事实证明,GARCH系列是所谓确定性波动率模型的一部分。还有一个家族叫做随机波动率模型,它允许模型中存在随机性,而GARCH假设我们对波动率进行了完美的建模(如果你对你所分析的序列非常熟悉,这可能是一个好的假设,但实际情况并不总是这样)。随机波动率模型通常是用马尔科夫链蒙特卡洛(MCMC)和准蒙特卡洛方法来估计的,如果你学过随机过程的相关内容,你会知道这是什么。
参考文献
- Tsay, R. (2010). Analysis of Financial Time Series. (3rd ed., Wiley Series in Probability and Statistics).
- Brockwell, P., & Davis, Richard A. (2016). Introduction to time series and forecasting (3rd ed., Springer texts in statistics). New York: Springer.
- Racine, Jeffrey S. (2019) Reproducible Econometrics Using R (Oxford)

最受欢迎的见解
1.HAR-RV-J与递归神经网络(RNN)混合模型预测和交易大型股票指数的高频波动率
2.R语言中基于混合数据抽样(MIDAS)回归的HAR-RV模型预测GDP增长回归的HAR-RV模型预测GDP增长")
4.R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测