案例:电商交易数据分析
一、导入要使用的模块
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import rcParams
二、读取数据
ds_trading_data = pd.read_csv("./order_info_2016.csv", index_col = "id")
pd.set_option("display.max_columns", None) # 显示所有列
ds_trading_data.index.name = None
rcParams["font.sans-serif"] = ["Kaiti"] # 设置绘图时显示的字体
rcParams['axes.unicode_minus'] = False # 正常显示负号
导入数据后,初步判断数据是否有缺失值
print(ds_trading_data.info())
Int64Index: 104557 entries, 1 to 104557
Data columns (total 10 columns):
orderId 104557 non-null int64
userId 104557 non-null int64
productId 104557 non-null int64
cityId 104557 non-null int64
price 104557 non-null int64
payMoney 104557 non-null int64
channelId 104549 non-null object
deviceType 104557 non-null int64
createTime 104557 non-null object
payTime 104557 non-null object
观察发现,原数据有10列(字段),共104557行,其中channelId列只有104549行,即有null值。接下来对各字段进行处理,即对重复值、缺失值、无效值等的处理。
三、清洗数据
1. 处理orderId列
print(ds_trading_data["orderId"].unique().size) # 查看orderId列是否有重复值
输出:104530
print(ds_trading_data.describe()) # 查看最大、最小值,判断该列的值是否在正常范围内
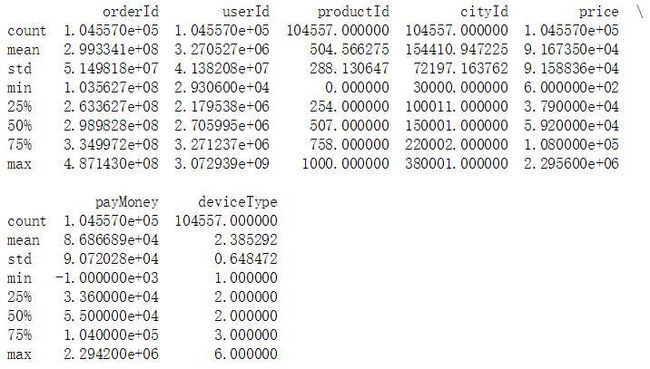
不难发现,这一列值均在正常范围内,但有重复值,因为订单号是唯一的,所以我们要去重,我们将这一步放到最后。
2. 处理userId列
print(ds_trading_data["userId"].unique().size)
输出:102672
userId列也有重复值,但是每个用户可以有多个订单,所以userId允许有重复值。
3. 处理productId列
由上图可知,productId列的最小值为0,不符合常理,因此要处理0值。
print(ds_trading_data[ds_trading_data["productId"] == 0])
输出:[177 rows x 10 columns]
可见productId为0的值共有177行,这些数据都是要清洗的,我们同样放到最后处理。
4. 处理cityId列
cityId列与productId列一样,是允许有重复值的,而且上图中看出这一列的值均在有效范围内,因此该列可不做处理。
5. 处理price列
由上图看出,price列的数值在正常范围内,无需处理,但是因为价格是以“分”为单位的,所以我们要把价格转化为以“元”为单位。
ds_trading_data["price"] = ds_trading_data["price"]/100
6. 处理payMoney列
ds_trading_data["payMoney"] = ds_trading_data["payMoney"]/100 # 与price列同理,将“分”转化为“元”
在上图中,payMoney列的最小值为负值,这是不合常理的,我们可以将这些数据删除。
ds_trading_data.drop(index = ds_trading_data[ds_trading_data["payMoney"] < 0].index, inplace = True)
7. 处理channelId列
前面讲过,channelId列是有null值得,我们将其删除
ds_trading_data.drop(index = ds_trading_data[pd.isnull(ds_trading_data["channelId"])].index, inplace = True)
8. 处理createTime列
# 将createTime转化为datetime类型
ds_trading_data["createTime"] = pd.to_datetime(ds_trading_data["createTime"])
9. 处理payTime列
# 将payTime转化为datetime类型
ds_trading_data["payTime"] = pd.to_datetime(ds_trading_data["payTime"])
10. 查看订单创建时的年份
print(pd.DatetimeIndex(ds_trading_data["createTime"]).year.unique())
输出:Int64Index([2016, 2015], dtype=‘int64’, name=‘createTime’)
print(ds_trading_data[pd.DatetimeIndex(ds_trading_data["createTime"]).year == 2015].index)
输出:Int64Index([53, 18669, 36650, 71638, 88692], dtype=‘int64’)
由此可见,有5个订单的创建时间在2015年,而剩余部分全在2016年,因此我们可以把2015年的数据删除,只分析订单创建时间在2016年的数据。
ds_trading_data.set_index("createTime", inplace = True)
# 删除2016年之前的数据
ds_trading_data.drop(index = ds_trading_data[:"2015-12-31 23:59:59"].index, inplace = True)
ds_trading_data = ds_trading_data.reset_index()
11. 将支付时间早于下单时间的记录删除
ds_trading_data.drop(index = ds_trading_data[ds_trading_data["payTime"]<ds_trading_data["createTime"]].index, inplace = True)
12. 处理productId列和orderId列
# 删除productId为0的记录
ds_trading_data.drop(index = ds_trading_data[ds_trading_data["productId"] == 0].index, inplace = True)
# 删除orderId列的重复值
ds_trading_data["orderId"].drop_duplicates(inplace = True)
13. 将deviceType列中的数字替换成相应字符串
ds_trading_data["deviceType"].replace({
1:"PC", 2:"Android", 3:"iPhone", 4:"Wap", 5:"Other", 6:"Other"}, inplace = True)
因为数据量较小,替换成的字符串来自另一份文件,这里没有导入,而是直接使用字典的方式替换。
四、分析及可视化
基础分析
1. 总体情况
print(ds_trading_data["orderId"].count()) # 所有订单数
print(ds_trading_data["userId"].unique().size) # 所有用户数 !!注意:因为unique()后是一个numpy.ndarray,此时不能使用count()
print(ds_trading_data["productId"].unique().size) # 被购买的商品种数
print(ds_trading_data["payMoney"].sum()) # 总销售额
输出:
104329
102447
1000
9066639970
经过前面一系列的数据清洗,最终得到了104329条有效信息。而在2016年全年中,一共有102447名顾客合计购买了1000种商品,总的成交额为9066639970元。
2. 从productId角度分析
# 不同商品销量
product_group_num = ds_trading_data.groupby(by = "productId").count()["orderId"].sort_values(ascending = False)
# 销量前10
product_group_num_top_10 = product_group_num.head(10)
# 销量后10
product_group_num_back_10 = product_group_num.tail(10)
# 不同商品的销售额
product_group_paymoney = ds_trading_data.groupby(by = "productId").sum()["payMoney"].sort_values(ascending = False)
# 销售额前10
product_group_paymoney_top_10 = product_group_paymoney.head(10)
# 销售额后10
product_group_paymoney_back_10 = product_group_paymoney.tail(10)
# ----- 绘图 -----
# 销量前10名
fig = plt.figure(figsize = (20, 15), dpi = 80)
f1 = fig.add_subplot(2, 2, 1)
f1.set_xlabel("商品ID", size = 22)
f1.set_ylabel("销量(件)", size = 22)
f1.set_title("2016年xxx公司不同商品销量前10名", size = 25)
f1.set_xticks(range(0, 10))
f1.set_xticklabels(product_group_num_top_10.index, size = 20)
f1.set_yticklabels(range(0, 351, 50), size = 20)
rects = f1.bar(range(0, len(product_group_num_top_10.index)), product_group_num_top_10.values, width = 0.5, color = "g")
for rect in rects:
height = rect.get_height()
f1.text(rect.get_x(), height+2, str(height), size = 18)
plt.grid(ls = "--", alpha = 0.5)
# 销量后10名
# 成交额前10名
# 成交额后10名
# 以上部分代码类似,这里省略
plt.show()
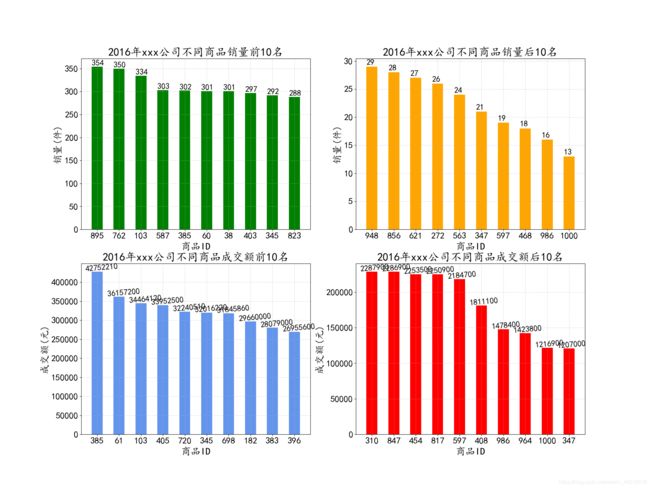
通过对销量与成交额的可视化,可以看出销量最多的商品是895号,成交额最高的商品是385号商品,因此895号商品的单价并不是最高的,而103号、385号与345号商品的销量与成交额均在前10名,所以对于这三种商品,应该加大推广力度。而销量与成交额均在后10名的商品中,有347号、597号、986号与1000号,对于这四种商品,应该优化其推广方式(比如打折出售或买多送一等,先打响商品知名度),如果是质量问题,甚至可以做下架处理。
3. 从商品price的角度分析
bins = np.arange(0, 26000, 2000) # 对价格进行分桶
price_cut = pd.cut(ds_trading_data["price"], bins = bins)
# ---- 绘图 ----
price_cut_counts = price_cut.value_counts()
price_cut_counts.index = [i.left for i in price_cut_counts.index]
price_cut_counts.sort_index(inplace = True)
plt.figure(figsize = (10, 8), dpi = 80)
_xticks = ["0-2000", "2000-4000", "4000-6000", "6000-8000", "8000-10000", "10000-12000", "12000-14000", "14000-16000", "16000-18000", "18000-20000", "20000-22000", "22000-24000"]
plt.xticks(range(0, len(price_cut_counts.index)), _xticks, size = 12, rotation = 14)
plt.yticks(range(0, 100000, 10000), size = 15)
plt.title("不同价格区间的物品销量分布", size = 20)
plt.xlabel("价格区间(单位:元)", size = 18)
plt.ylabel("销量(件)", size = 18)
pts = plt.plot(range(0, len(price_cut_counts.index)), price_cut_counts.values, marker = "o", mfc='r', mec = "r", color = "b")
for a, b in enumerate(zip(_xticks, price_cut_counts.values)):
plt.text(a+0.1, b[1]+1200, b[1], size = 15)
plt.grid(ls = "--", alpha = 0.4)
plt.show()

不难发现,部分价格区间并没有售出商品,因此可以对此做相应调整:调查这些物品是否为大件商品,如家具、电器等,这些商品的使用寿命较长,可能出现一年内没有顾客更换的情况;其次,人们普遍喜欢使用知名品牌的产品,因此可调查这些商品的品牌是否并不被大众所熟知,针对结果做品牌上的更换;另外,可以看竞品在该价格区间下有哪些物品,加以补充。
4. 从购买设备的角度分析
不同设备的总订单数
deviceType_count = ds_trading_data.groupby(by = "deviceType").count()["orderId"].sort_values(ascending = False)
# ---- 绘图 ----
plt.figure(figsize = (10, 8), dpi = 80)
_xticks = deviceType_count.index
plt.xticks(range(0, 5), _xticks, size = 15)
plt.yticks(range(0, 50001, 5000), size = 15)
plt.xlabel("设备类型", size = 16)
plt.ylabel("订单数(件)", size = 16)
plt.title("顾客通过不同设备购买商品的总订单数分布条形图", size = 20)
rects = plt.bar(range(0, 5), deviceType_count.values, width = 0.5)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x()+0.1, height+500, str(height), size = 15)
plt.grid(ls = "--", alpha = 0.4)
plt.show()
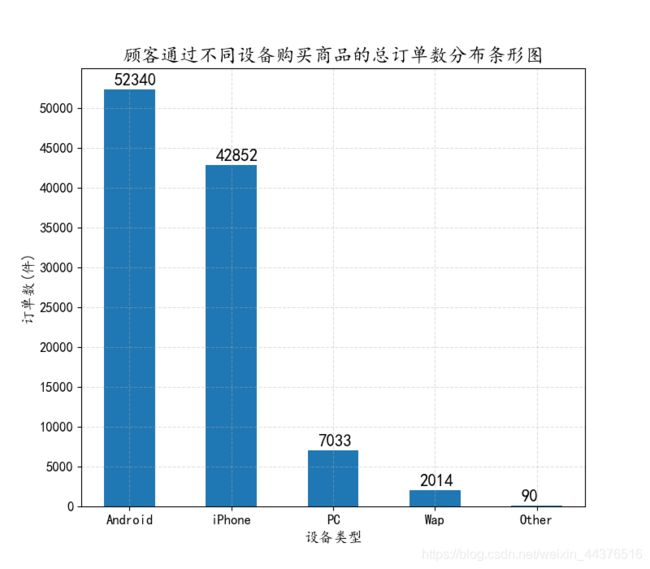
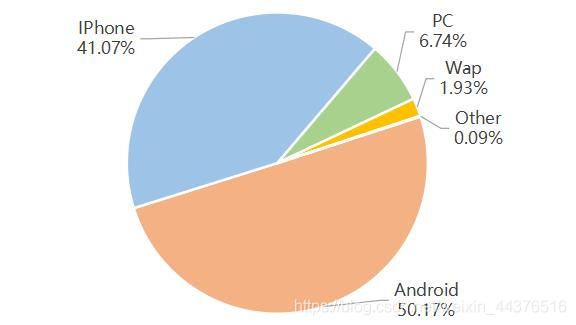
从条形图和饼图可看出,通过安卓设备下单的订单数最多,为52340件,IPhone紧随其后,两者总占比90%以上,其余设备占比则较少,这也基本符合现状,就是绝大多数人都拥有自己的手机,且可通过手机完成选购、下单、支付等整套购物流程。
不同设备的总成交额
deviceType_sum = ds_trading_data.groupby(by = "deviceType").sum()["payMoney"]
# ---- 绘图 ----
plt.figure(figsize = (10, 8), dpi = 80)
_xticks = deviceType_sum.index
plt.xticks(range(0, 5), _xticks, size = 15)
plt.yticks(size = 15)
plt.xlabel("设备类型", size = 16)
plt.ylabel("成交额(元)", size = 16)
plt.title("顾客通过不同设备购买商品的总成交额分布条形图", size = 20)
rects = plt.bar(range(0, 5), deviceType_sum.values, width = 0.5)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x(), height+60000000, str(round(height, 2)), size = 15)
plt.grid(ls = "--", alpha = 0.4)
plt.show()

显然,因为人们通过Android和IPhone下单较多,因此这两者的成交额也是名列前茅,分居一二名。
5. 从渠道的角度分析
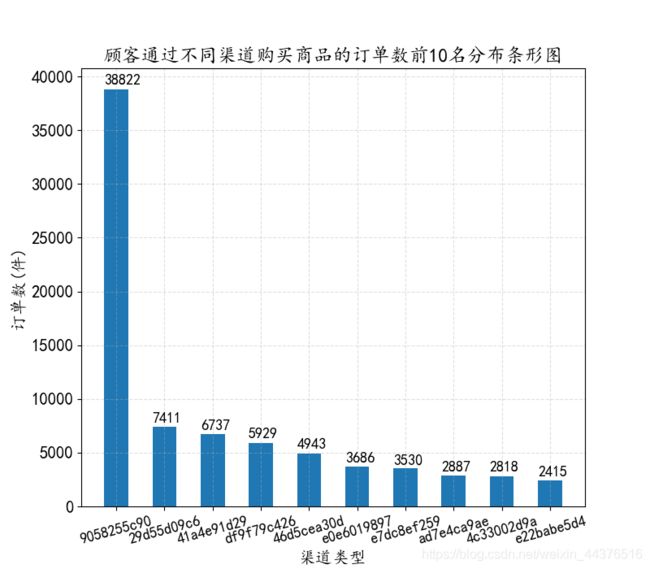
不同渠道的订单数
cannelId_group_ordernum = ds_trading_data.groupby(by = "channelId").count()["orderId"]
cannelId_group_ordernum_top_10 = cannelId_group_ordernum.sort_values(ascending = False)[:10]
# ---- 绘图 ----
不同渠道的成交额
cannelId_group_paymoney = ds_trading_data.groupby(by = "channelId").sum()["payMoney"]
cannelId_group_paymoney_top_10 = cannelId_group_paymoney.sort_values(ascending = False)[:10]
# ---- 绘图 ----
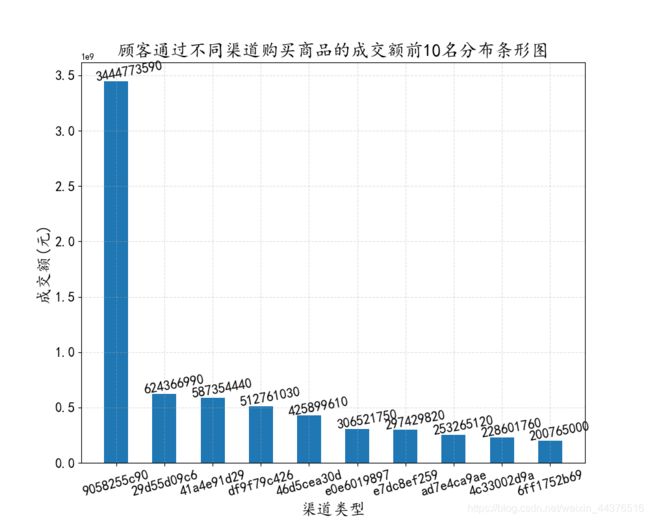
这两幅图反映了渠道9058255c90是2016年成交额的主要贡献者,它是第二名的5.5倍。针对它的高成交额,我们可以分析它的营销模式或推广手段,把它的优势继续发挥下去,同时让其他渠道借鉴它的“成功秘诀”。另外,渠道很多时候是需要花钱买流量的,所以这里还要根据渠道的盈利情况和投入成本进行综合分析,但数据有限,这里不再分析。
进阶分析
6. 从下单时间的角度分析
获取每个订单的下单时间(以小时为单位统计)
ds_trading_data["order_hour"] = ds_trading_data["createTime"].dt.hour
# 不同时间的订单数
order_hour_count = ds_trading_data["order_hour"].value_counts().sort_index()
# ---- 绘图 ----
plt.figure(figsize = (12, 8), dpi = 80)
_xticks = list(order_hour_count.index)
_xticks.append(24)
_x = [i-0.5 for i in range(0, 25)]
plt.xticks(_x, _xticks, size = 15)
plt.yticks(range(0, 14001, 2000), [i for i in range(0, 14001, 2000)], size = 15)
plt.xlabel("时间段", size = 18)
plt.ylabel("订单数(件)", size = 18)
plt.title("2016年xxx公司在每日不同时间段的总订单数", size = 20)
colors = ["#1C86EE"] * 24
colors[13] = "r"
colors[20] = "r"
rects = plt.bar(range(0, 24), order_hour_count.values, width = 1, edgecolor = "#B8B8B8", color = colors)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x(), height+80, str(height), size = 15)
plt.grid(ls = "--", alpha = 0.4)
plt.savefig("./hh.png", dpi = 100)
plt.show()

由直方图可以看出,一天中人们购物有两个高峰期,分别为中午的13~14点及晚上的20~21点,这两个时间点均为饭点后的作息时间,因此可以在这两个时间段加大商品的推广力度,或者进行优惠活动,促进人们的购物欲望。同时要注意维护这两个时间段系统或购物APP的稳定性,避免出现卡顿等糟糕的购物体验。
获取每个订单的下单时间(以星期为单位统计)
ds_trading_data["order_week"] = ds_trading_data["createTime"].dt.dayofweek
# 不同星期的订单数
order_week_groupby = ds_trading_data.groupby(by = "order_week").count()["orderId"]
order_week_groupby.index = [i for i in range(1, 8)]
# ---- 绘图 ----
plt.figure(figsize = (8, 8), dpi = 80)
_xticks = ["星期一", "星期二", "星期三", "星期四", "星期五", "星期六", "星期日", ]
plt.xticks(order_week_groupby.index, _xticks, size = 15)
plt.yticks(size = 15)
plt.xlabel("时间", size = 18)
plt.ylabel("订单数(件)", size = 18)
plt.title("2016年xxx公司在每周不同时间的总订单数", size = 20)
rects = plt.bar(order_week_groupby.index, order_week_groupby.values, width = 0.4)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x()-0.1, height+200, str(height), size = 15)
plt.grid(ls = "--", alpha = 0.4)
plt.savefig("./hh.png", dpi = 100)
plt.show()
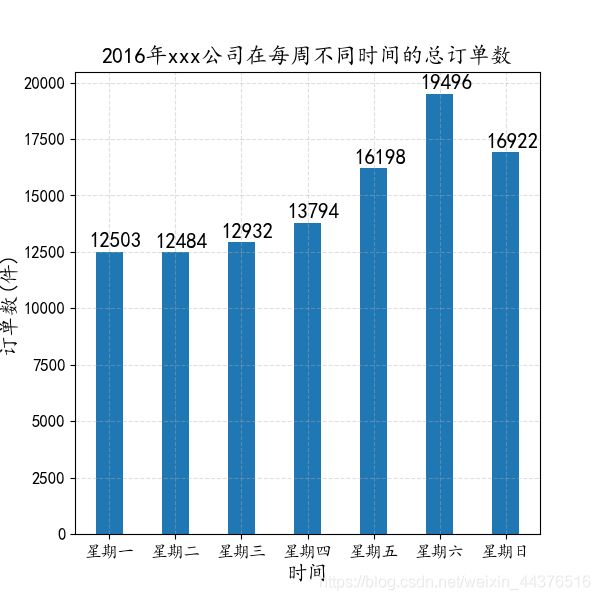
按星期来看,周末两天的下单数位居前两名,其中周六达到一周的高峰,有19496单。
7. 从下单到成交的时间间隔角度分析
# 将时间间隔转化为以“秒”为单位的数据
ds_trading_data["dealTime"] = (ds_trading_data["payTime"] - ds_trading_data["createTime"]).map(lambda x:x.total_seconds())
bins = [0, 60, 120, 180, 240, 300, 600, 1200, 1800, 6000, 19865401]
dealTime_cut = pd.cut(ds_trading_data["dealTime"], bins = bins, right = False).value_counts()
dealTime_cut.index = [i.left for i in dealTime_cut.index]
dealTime_cut.sort_index(inplace = True)
# ---- 绘图 ----
plt.figure(figsize = (12, 8), dpi = 80)
_xticks = ["1min以内", "1-2min", "2-3min", "3-4min", "4-5min", "5-10min", "10-20min", "20-30min", "30-60min", "60min以上"]
plt.xticks(range(0, 10), _xticks, size = 15)
plt.yticks(size = 15)
plt.xlabel("时间间隔", size = 18)
plt.ylabel("订单数(件)", size = 18)
plt.title("顾客从下单到支付成功的不同时间间隔内的总订单数", size = 20)
plt.plot(range(0, 10), dealTime_cut.values, marker = "o", mfc = "r")
for a, b in enumerate(zip(_xticks, dealTime_cut.values)):
plt.text(a, b[1]+800, b[1], size = 15)
plt.grid(ls = "--", alpha = 0.4)
plt.show()
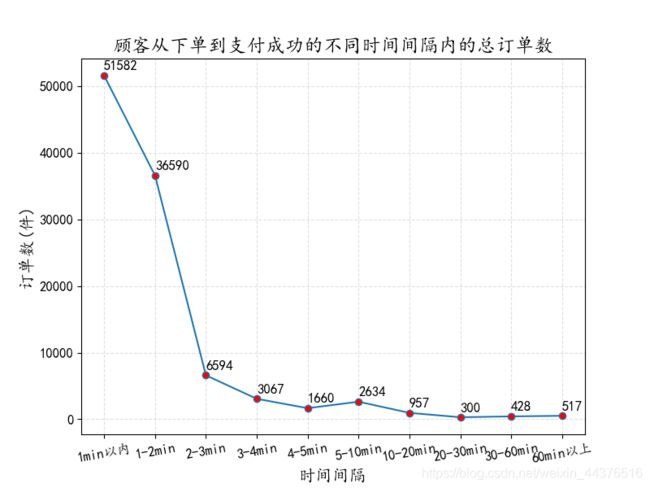
从折线图可以看出,整体是一个下降趋势,即时间间隔越长,下单的成功率越低,其中1分钟以内支付成功的订单最多,为51582单,这体现了人们的购买意愿较强。
8. 不同商品的投入产出比
print(ds_trading_data.head())
输出:

通过比较price列与payMoney列可知,部分商品的实际支付额低于它的售价,换言之,这些商品在支付时要么会有打折优惠,要么是有满减优惠,即商家为了吸引更多的用户下单购买而付出的补贴额。为了研究不同商品的投入产出比,我们将进行以下操作:
ds_trading_data["discount_money"] = ds_trading_data["price"] - ds_trading_data["payMoney"]
d_m_groupby = ds_trading_data.groupby("productId").sum()[["payMoney","discount_money"]]
d_m_groupby["invest_produce_rate"] = round(d_m_groupby["payMoney"]/d_m_groupby["discount_money"], 2)
d_m_groupby.sort_values("invest_produce_rate", ascending = False, inplace = True)
# ----- 绘图 -----
# 绘图代码略

通过条形图可看出,492号商品的投入产出比为86.36,处于所有商品之最,即每投入1元,492号商品能带来86.36元的成交额。因此,在492号商品的宣传上,应加大力度,可以在移动端与PC端的购买页面中,将其置于显眼的广告位,同时做ABtest,如果不影响其他商品的投入产出比,那么这将是很好的盈利方式。对于其他前14名商品,亦可做类似处理。
9. 2016年每个月的总成交额的变化趋势
ds_trading_data.set_index("payTime", inplace = True)
M_paymoney = ds_trading_data.resample("M").sum()["payMoney"]
# ----- 绘图 -----
# 绘图代码略
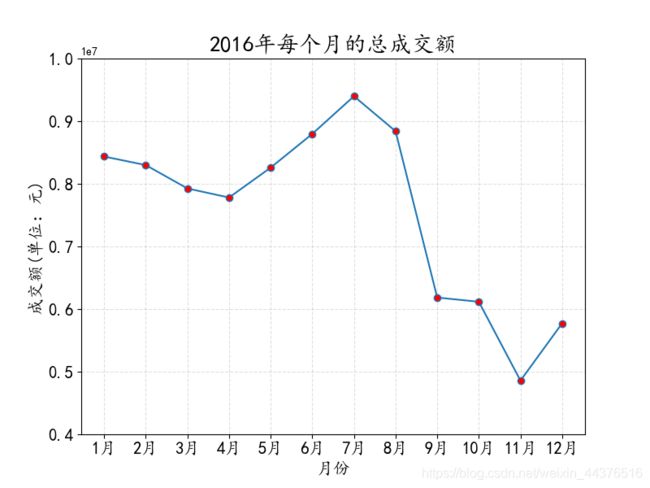
通过折线图可看出,7月的总成交额最多,11月的总成交额最少,但需要注意的是,8月到9月的跌幅最大,为了分析原因,我们做以下分析:
(1) 查看不同设备每个月的总成交额分布情况
ds_trading_data["M"] = ds_trading_data["payTime"].dt.month
d_M_groupby = ds_trading_data.groupby(by = ["deviceType","M"]).sum()["payMoney"]
# ----- 绘图 -----
# 绘图代码略
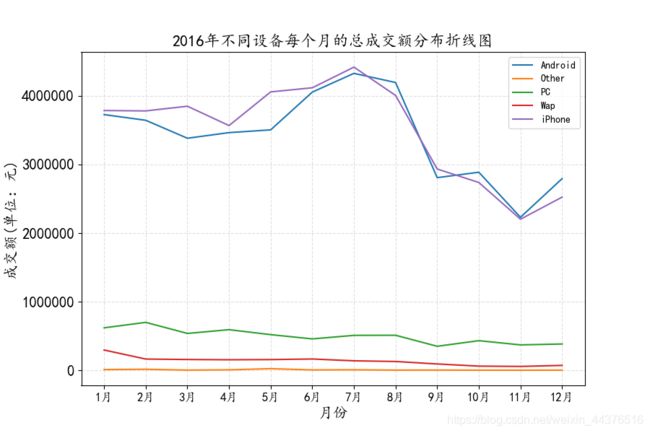
除了Android和iPhone设备,通过其余设备下单的总成交额每月的变化比较稳定,这与前面分析的顾客主要通过Android和iPhone下单的关系较大。但也能明显看出,无论是Android还是iPhone,8月到9月的成交额都呈现下降趋势,这也导致了9月份总成交额的下跌。不过,这也意味着成交额的下跌并不是因为某一种设备的
成交额下跌引起的,为了进一步分析原因,我们从城市的维度分析。
(2) 查看不同城市每个月的总成交额分布情况
ds_trading_data["M"] = ds_trading_data["payTime"].dt.month
M_c_groupby = ds_trading_data.groupby(by = ["M","cityId"]).sum()[["payMoney"]]
M_c_groupby_8 = M_c_groupby.loc[8] # 8月份不同城市的成交额
M_c_groupby_9 = M_c_groupby.loc[9] # 9月份不同城市的成交额
因为部分城市并不是在8、9月份都有成交额,所以将两表外连接,并用0填充Nan值
M_c_groupby_8_9 = M_c_groupby_8.merge(M_c_groupby_9, on = "cityId", how = "outer")
M_c_groupby_8_9 = M_c_groupby_8_9.fillna(0) # 用0填充Nan值
M_c_groupby_8_9.rename(columns = {
"payMoney_x" : "8月", "payMoney_y" : "9月"}, inplace = True)
M_c_groupby_8_9["8_Minus_9"] = M_c_groupby_8_9["8月"] - M_c_groupby_8_9["9月"]
M_c_groupby_8_9.sort_values("8_Minus_9", inplace = True)
# ----- 绘图 -----
# 绘图代码略
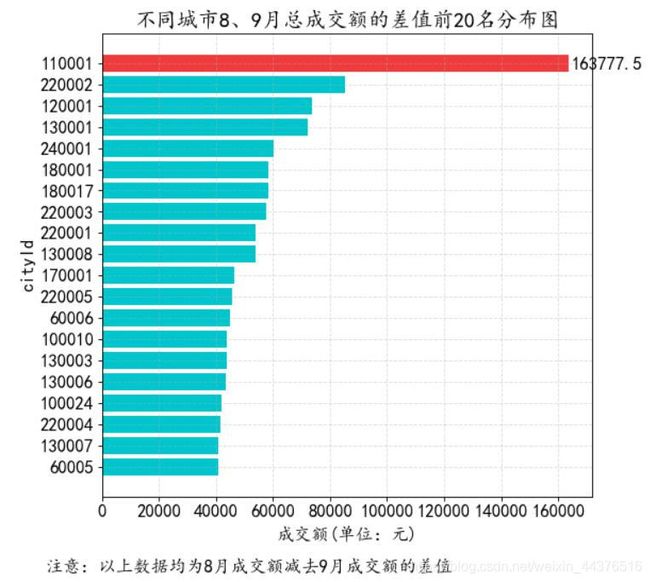
可以看出,排在前20名的城市中,每一个城市9月份的成交额都比8月份下降了40000元以上,其中城市Id为110001的城市下降最大,达到16万以上,因此可以观察这些城市是不是在推广环节出现问题、或是没有优惠活动,导致顾客购买欲望下降等。
除了上述两个维度,还可以从商品出发,看是不是某一品类的商品销量出现下滑等,因为数据不充分,这里不再做进一步分析。
10. 2016年不同顾客的购买频次分析
userId_groupby = ds_trading_data.groupby("userId").count()["orderId"]
buy_once = userId_groupby[userId_groupby.values == 1].count()
buy_twice = userId_groupby[userId_groupby.values == 2].count()
buy_over_three_times = userId_groupby[userId_groupby.values == 3].count()
y1 = round(buy_once/userId_groupby.size, 4)
y2 = round(buy_twice/userId_groupby.size, 4)
y3 = round(buy_over_three_times/userId_groupby.size, 4)
print(y1, y2, y3)
# ----- 绘图 -----
plt.figure(figsize = (7, 7), dpi = 80)
x = ["1次", "2次", "3次及以上"]
y = [y1, y2, y3]
plt.xticks(range(len(x)), x, size = 15)
plt.yticks(size = 15)
plt.xlabel("购买次数", size = 16)
plt.ylabel("占比", size = 16)
plt.title("2016年不同顾客的购买频次分布图", size = 18)
rects = plt.bar(x, y, width = 0.3)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x(), height+0.01, str(height*100)+"%", size = 15)
# 将y轴设置成百分比的形式
from matplotlib.ticker import FuncFormatter
def to_percent(temp, position):
return '%1.2f'%(100*temp) + '%'
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
plt.grid(ls = "--", alpha = 0.4)
plt.show()
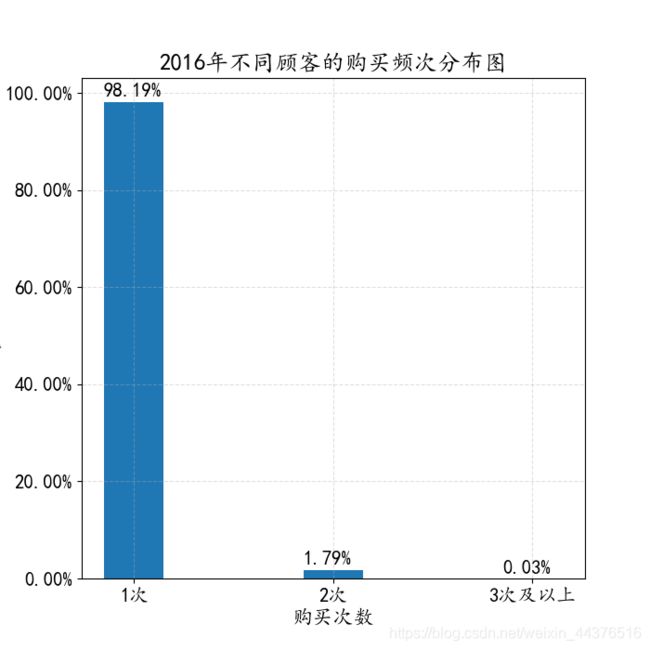
通过柱形图可知,这一年只购买1次的客户占绝大多数,而3次及以上的人数只有0.03%,但这还未能说明太多问题,此时应该同比分析,分析去年、前年的数据,来查看购买次数的变化趋势。而原数据只有2016年的数据,所以这里不能做进一步分析。
五、总结
本案例主要对电商交易数据进行了一些常见的分析,包括了商品ID、商品价格、设备类型、下单时间等多个维度。因为不是多年的数据,因此无法做同比分析,而且数据不是企业内部的全部数据,所以原数据并没有出现像加购转化漏斗、网站流量等电商数据分析中常见的指标。不过,从仅有的数据来看,分析的结果基本符合我们的生活习惯,例如手机购物占多数、午休和晚饭后的休闲时间达到购物高峰期等等。