知识抽取学习笔记:面向非结构化数据的抽取
1概念
知识抽取,即从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱。大体的任务分类与对应技术如下图所示: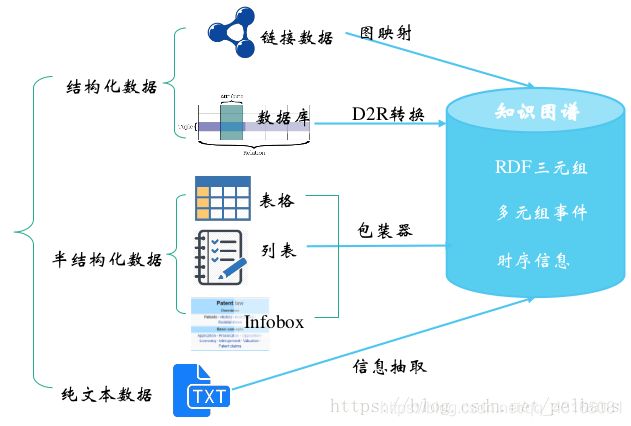
2知识抽取的技术与难点
从结构化数据库中获取知识:D2R
难点:复杂表数据的处理
从链接数据中获取知识:图映射
难点:数据对齐
从半结构化(网站)数据中获取知识:使用包装器
难点:方便的包装器定义方法,包装器自动生成、更新与维护
从文本中获取知识:信息抽取
难点:结果的准确率与覆盖率
3知识抽取的子任务
知识抽取:自动化从文本中发现和抽取相关信息。将非结构化转化为结构化数据。
命名实体识别(NER)
检测:西瓜书的作者是周志华。→[西瓜书]:实体
分类:西瓜书的作者是周志华。→[西瓜书]:书籍
术语抽取
从语料中发现多个单词组成的相关术语。
关系抽取:抽取出实体、属性等之间的关系。
eg:王思聪是万达集团董事长王健林的独子。→[王健林] <父子关系> [王思聪]
事件抽取:相当于多元关系抽取
eg:据路透社消息,英国当地时间9月15日早8时15分,位于伦敦西南地铁线District Line的Parsons Green地铁站发生爆炸,目前已确定有多人受伤,具体伤亡人数尚不明确。目前,英国警方已将此次爆炸与起火定性为恐怖袭击。

共指消解

4面向非结构化数据的知识抽取
4.1实体抽取
实体抽取抽取文本中的原子信息元素,通常包含任命、组织/机构名、地理位置、时间/日期、字符值等标签,具体的标签定义可根据任务不同而调整。如:

非结构化数据的实体抽取可以认为是一个序列标注问题,则可使用序列标注的方法,通过评价指标 F1值的比较如下:
人工特征:IOB标注体系——O(Others)/B-ORG(组织开始字)/I-ORG(组织中间词)….
词本身的特征:边界特征、词性、依存关系等
前后缀特征:姓氏、地名等
字本身的特征:是否是数字、是否是字符等
HMM
有向图模型、生成式模型(找到使 P(X,Y)P(X,Y) 最大的参数)、假设特征之间是独立的
CRF
无向图模型、判别式模型(找到使 P(Y∣X)P(Y∣X) 最大的参数)、没有关于特征之间是独立的
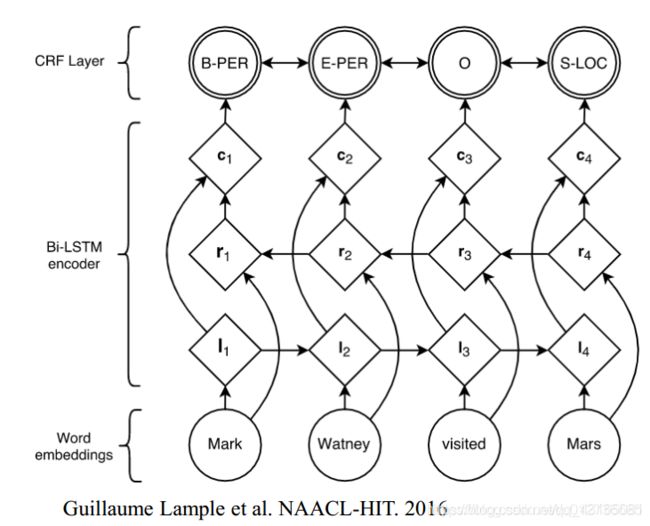
LSTM+CRF(主流)
判别式模型、端到端网络、自动提取特征
模型:word embeddings->Bi-LSTM encoder->CRF Layer
4.2实体识别与链接
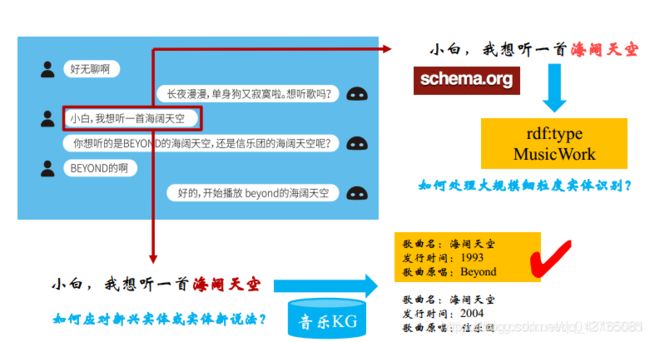
实体识别即识别出句子或文本中的实体,链接就是将该实体与知识库中的对应实体进行链接。其中涉及到了实体的识别与消岐技术。实体识别技术刚刚介绍过,下面把重点放在实体链接部分。
示例:聊天机器人
如何处理大规模细粒度实体识别?
如何应对新兴实体或实体新说法?
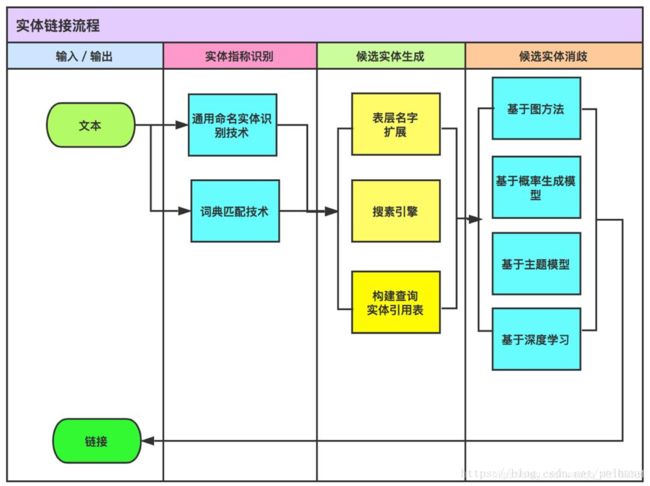
实体链接的流程:
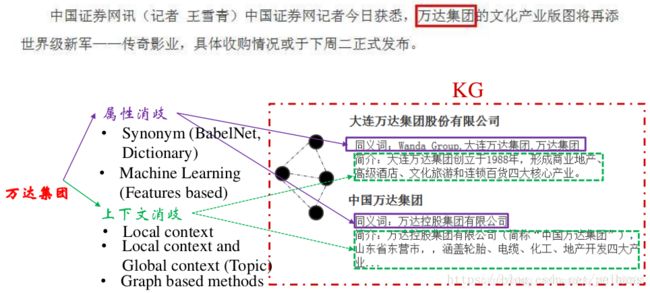
文本 =》实体指称识别 =》候选实体生成 =》候选实体消歧 =》链接
开源工具:Wikipedia Miner、DBpedia Spotligth、OpenCalais
文字表述为,首先输入的是非结构化的文本数据,经由命名实体识别或词典匹配技术进行实体的指称识别。由于刚刚识别出来的实体可能是实体的部分表示或另类表示,因此需要结束表层名字扩展、搜索引擎、构建查询实体引用表等技术来对候选实体进行生成。经过该步骤生成的实体可能有多个候选项,因此需要对候选实体进行消岐,此处可使用基于图的方法、基于概率生成模型、基于主题模型或基于深度学习的方法。经过实体消岐后得到的唯一实体候选后就可以与知识库中的实体进行连接了。
实体链接示例:
eg:中国证券网讯(记者 王雪青)中国证券记者今日获悉,万达集团的文明产业版图将再添世界级新军——传奇影业,具体收购情况或于下周二正式发布。
5关系抽取
关系抽取是从文本中抽取出两个或多个实体之间的语义关系。它是信息抽取研究领域的任务之一。如:
示例1:王健林谈儿子王思聪:我期望他稳重一点。==》父子(王健林, 王思聪)

方法分类:
基于模板的方法
基于触发词的Pattern
基于依存句法分析的Pattern
基于监督学习方法
机器学习方法
深度学习方法
基于弱监督学习方法
远程监督
Bootstrapping
(1)基于模板的方法
a、基于触发词的Pattern
首先确定触发词(trigger word),然后根据触发词做pattern的匹配及抽取,然后做一个映射。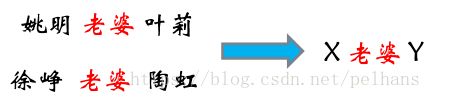
分析:上述示例中的触发词为老婆、妻子、配偶等。根据这些触发词找出夫妻关系这种关系,同时通过命名实体识别给出关系的参与方。
基于依存分析的Pattern
以动词为起点,构建规则,对节点上的词性和边上的依存关系进行限定。一般情况下是形容词+名字或动宾短语等情况,因此相当于以动词为中心结构做的Pattern。文本一般具有一些句法结构,如主谓结构、动宾结构、从句结构、这些结构可以是跨多个词所产生的。最常见的情况是动宾短语,所以通常以动词为起点,构建规则,对节点上的词性和边上的依存关系进行限定(可以理解为泛化的正则表达式)。具体的流程如下:
其执行流程为: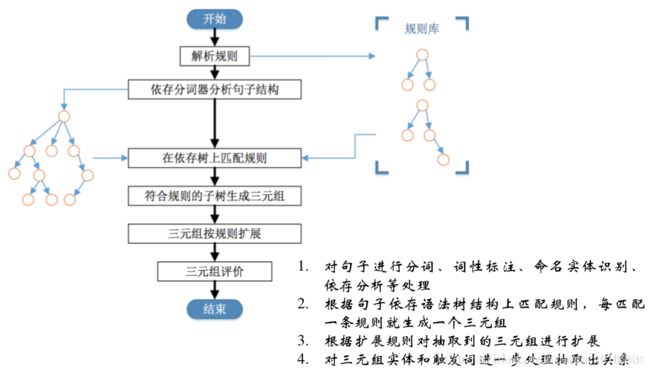
示例:董卿现身国家博物馆看展优雅端庄大方
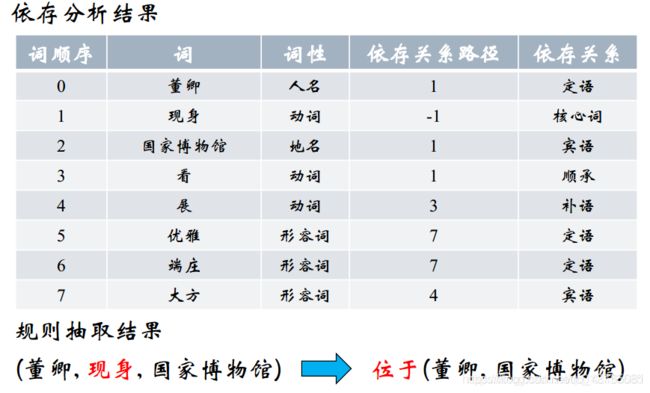
分析:上图中,我们可以看出这个例子中的依存关系路径中 -1 代表谓语,同时可以看出 董卿 这个词依存关系路径为 1,说明此处的董卿是和词顺序为 1 的现身关联,于是可以得到“董卿,现身”;接着看“国家博物馆”也是和“现身”所关联,所以可以得出一个动宾关系“现身,国家博物馆”。
(2)基于监督学习方法
a、基于机器学习的方法
在给定实体对的情况下,根据句子上下文对实体关系进行预测,执行流程为:
预先定义好关系的类别。
人工标注一些数据。
设计特征表示。
选择一个分类方法。(SVM、NN、朴素贝叶斯)
评估方法。
特征表示
轻量级特征——词
实体前后的词
实体的类型
实体之间的距离(也就是实体之间的相似度)
中等量级特征——词组
Chunk序列:如词组
重量级特征——句子
实体间的依存关系路径
实体间树结构的距离
特定的结构信息
2基于深度学习的方法
特征表示
Position embeddings
Word embeddings
Knowledge embedding
…
方法分类
Pipeline:识别实体和关系分类是完全分离的两个过程(即串联方式),不会相互影响,关系的识别依赖于实体识别的效果
Joint Model:实体识别和关系分类的过程是共同优化的
典型的Pipeline方法——存在错误传递的问题
CR-CNN模型
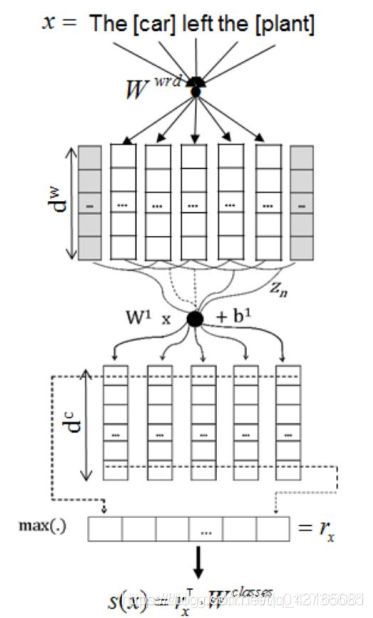
Att-CNN 模型
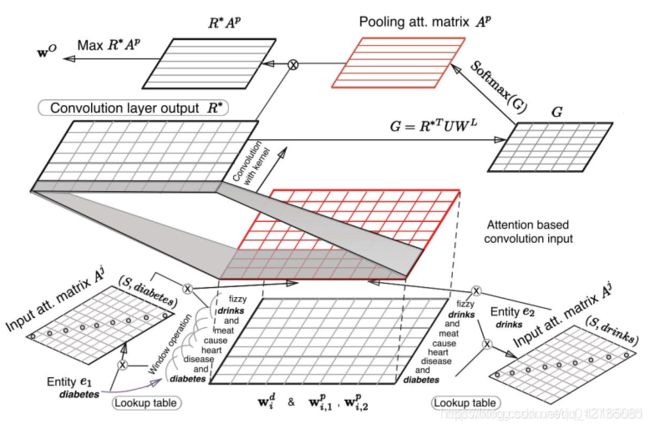
Att-BLSTM模型
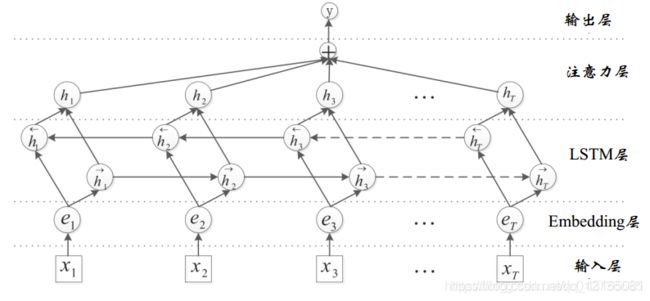
典型的Joint Model方法——效果一般情况下优于Pipeline,但是参数空间会提高。
LSTM-RNNs模型
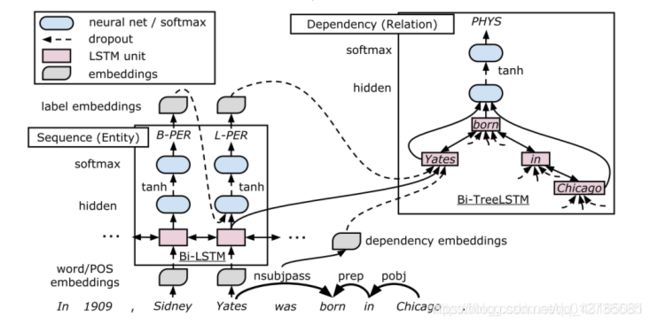
3基于半监督学习方法
标注数据不足 或 数据量又特别大的情况下 ==》半监督学习的方法
a、远程监督方法
远程监督:知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
基本假设:若两个实体在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
示例:
在某知识库中存在: 创始人 (乔布斯, 苹果公司)
则可构建训练正例:乔布斯是苹果公司的联合创始人和CEO
具体的步骤:
从知识库中抽取存在关系的实体对;
从非结构化文本中抽取含有实体对的句子作为训练样例。
小结:
优点:可以利用丰富的知识库信息,减少一定的人工标注,
缺点:假设过于肯定,引入大量的噪声,存在语义漂移现象;很难发现新的关系。
b、Bootstrapping
Bootstrapping:
通过在文本中匹配实体对和表达关系短语模式,寻找和发现新的潜在关系三元组。
具体来讲,主要是利用少量实例作为初始种子(seed tuples)的集合,然后利用 pattern 学习方法进行学习,通过不断迭代从非结构化数据中抽取实例,然后从新学到的实例中学习新的 pattern 并扩充 pattern 集合,寻找和发现新的潜在关系三元组。
整体步骤:
假设给定了一个种子集合,种子词一般都是实体对,如:<姚明,叶莉>
从文档中抽取出包含种子实体词的新闻,eg:
姚明 老婆 叶莉 简历身高曝光 ==》X 老婆 Y 简历身高曝光
姚明 与妻子 叶莉 外出赴约 ==》X 与妻子 Y 外出赴约
将抽取出的Pattern去文档集中匹配
小猪 与妻子 伊万 外出赴约
根据Pattern抽取出的新文档如种子库,迭代多轮直到不符合条件
小结
优点:构建成本低,适合大规模的构建;同时还可以发现新的(隐含的)关系。
缺点:对初始给定的种子集敏感;存在语义漂移现象;结果的准确率较低等。
4事件抽取
事件:指发生的事情,通常具有时间、地点、参与者等属性,事件的发生可能因为一个动作的产生或者系统状态的改变。
事件抽取:从自然语言中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与着等。
事件抽取的相关术语:
事件描述 (Event Mention):描述事件的词组或句子;
事件触发 (Event Trigger):表明事件出现的主要词汇;
事件元素 (Event Argument):事件的重要信息;
元素角色 (Argument Role):元素在句子中的语义角色。
示例:
事件嵌套:事件是可以嵌套的,可以做事件的检测与跟踪。
(2)事件抽取任务
事件抽取任务最基础的部分包括:
识别事件触发词及事件类型
抽取事件元素同时判断其角色
抽出描述事件的词组或句子
此外,事件抽取任务还包括:
事件属性标注
事件共指消解
(3)事件抽取的Pipeline方法
有监督的事件抽取方法的标准流程一种pipeline的方法,将事件抽取任务转化为多阶段的分类问题,

需要的分类器包括:
事件触发次分类器(Trigger Classifier)
用于判断词汇是否是是事件触发词,以及事件的类别
元素分类器(Argument Classifier)
判别词组是否是事件的元素
元素角色分类器(Role Classifier)
判定元素的角色类别
属性分类器(attribute classifier)
判定事件的属性
可报告性分类器(Reportable-Event Classifier)
判定是否存在值得报告的事件实例
分类器模型可以是机器学习方法中的各种分类器模型,比如MaxEnt、SVM等。
典型的分类特征:
存在问题:
误差累积:误差从前面的环节传播到后面的环节,使得性能急剧衰减
环节独立:各个环节的预测任务是独立的,之间没有互动
无法处理全局的依赖关系
(4)事件抽取的联合方法
a、Joint Inference(联合推理方法):
是一种集成学习的方法,构建 nn 个模型,最后对 nn 个模型的结果进行求和等方法来预测。
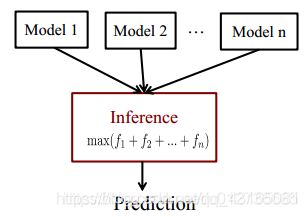
可以基于以下方法:
Constrained Conditional Models
ILP Re-ranking (整形规划重排序)
Dual decomposition
b、Joint Modeling
实际上是一种多任务学习,在不同任务中共享一些隐层特征,如word特征、embedding特征、句法特征等。
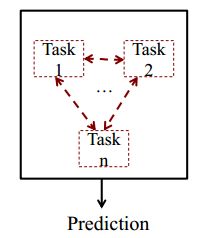
可以基于如下方法:
Probabilistic Graphical Models
Markov logic networks
(4)基于深度学习的事件抽取方法
优势:
减少了对外部NLP工具的依赖,甚至不依赖NLP工具,建模成端到端的系统。
使用词向量作为输入,词向量蕴含丰富的语言特征。
自动提取句子特征,避免人工设计特征的繁琐工作。
基于动态多池化卷积神经网络的事件抽取方法:
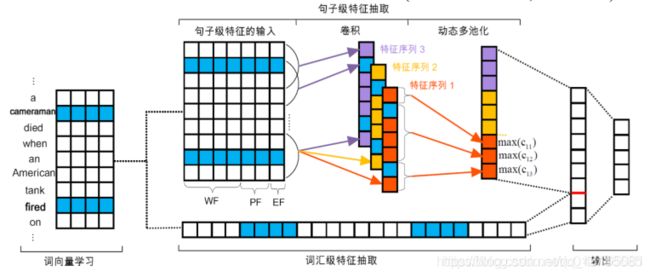
动态多池化层:
传统的神经网络利用最大池化层
事件抽取中,一个句子可能包含多个事件