python爬虫百度图片之js解密,一起唠唠百度图片。
仅供学习,不得进行商业用途。谢谢呢!
个人博客:http://www.feastawlisao.com/
欢迎关注个人公众号:pythonORjs

一个朋友说要用蘑菇,做一些人工智能识别,没有素材,让我给他搞点图片。。。。
我当然是不答应的,我天,,,,
所以我就没写…
本篇文章完。。。
诶,诶,等会,,,,,回来,回来,,,,
还是算了吧,,请听下回分解。。。。

进入正题:
1.打开百度,搜索蘑菇图片,具体你们想搜啥搜啥,爱搜啥搜啥,好吧!新手注意以下内容,
看到这种网站,第一种想的应该是ajax动态加载,我们把滚动条往下拉。
拉…
接着拉…
拉到明年为止,ajax就破解了,就问你简单不简单???
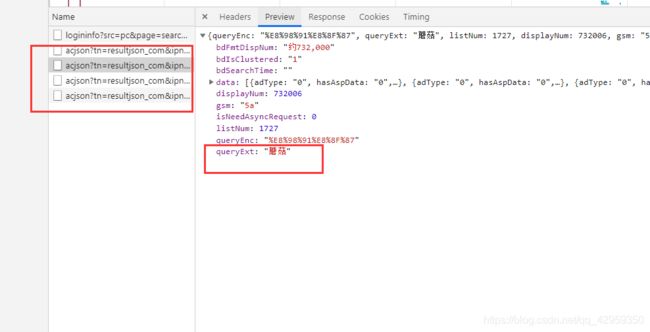
往下来,就会发现出现了新的请求,诶,是咱们搜的蘑菇哦!
我们来分析一波这个请求,
发现携带了这么多参数,那肯定好多参数都是没用的拉,哇,我真聪明!有木有??
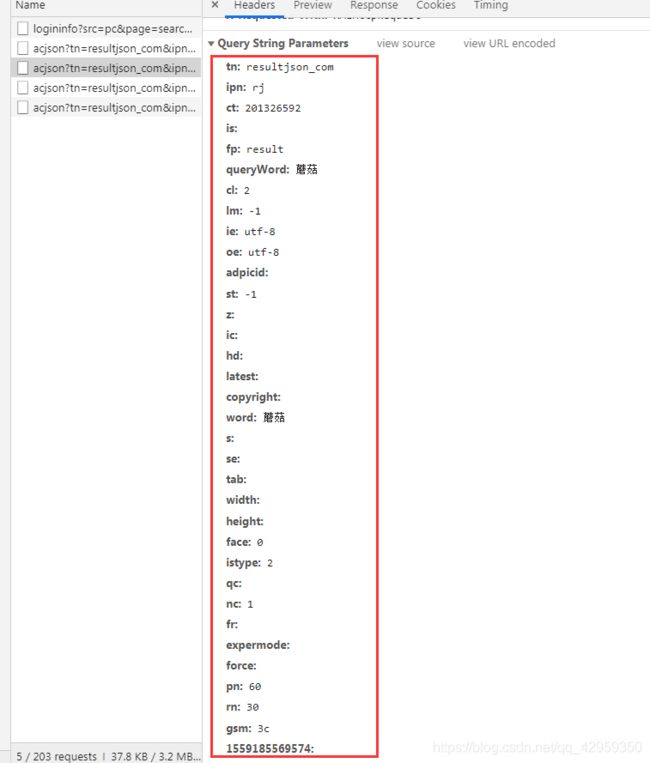
那我们就分析一波,好啦!
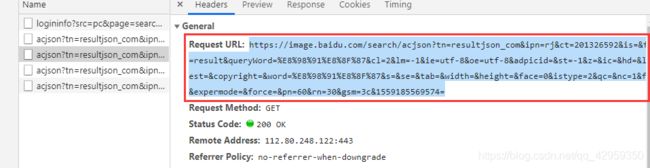
复制url到浏览器,进行分析,得到需要的参数就四个即可
http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&word=%E8%98%91%E8%8F%8&pn=30
tn=resultjson_com
ipn=rj
word=%E8%98%91%E8%8F%8 # 这个是浏览器经过编码得出来的,,就是我们搜的‘’蘑菇‘’
pn=30 # 这个经过分析是循环的页数
那么一切ok,我们开始行动!敲代码!!!
import requests
for x,i in enumerate(range(0,100000000000,30)):
url_img = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&word=花草&pn={}'.format(i)
response = requests.get(url_img).json()
print(response)
break
此处,我们不知道百度图片有多少页,,那就写上1千万吧,,哈哈啊哈哈哈,

诶,,出来了,,很神奇,有木有…
好吧,没啥神奇的
我们分析一下json数据,,
然后…

为啥么每一个都是403.。
我被骗了
气死我了
我这暴脾气
冷静,冷静
数据不可错的
那么数据就是被加密的,分析一波,发现个可疑得数据
![]()
这个是个objURL,怎么会长得这么四不像呢?
加密方式具体可以参考:
可以参考一个:https://blog.csdn.net/hbuxiaoshe/article/details/44780653
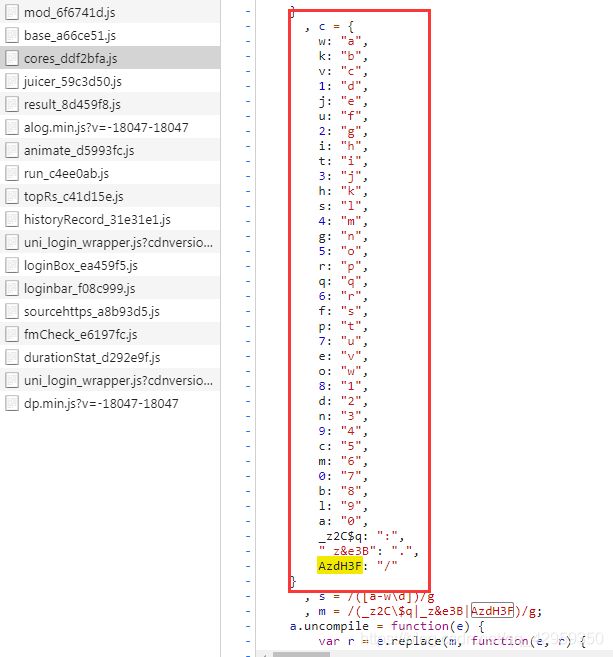
这种加密方式显得有点low了,,玩文字替换,,,
完整代码如下:
import requests,re
name = '蘑菇'
for x, i in enumerate(range(0, 100000000000, 30)):
url_img = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&word=花草&pn={}'.format(i)
response = requests.get(url_img).json()
for data in response['data']:
if data:
objURL = data['objURL']
table = {'w': "a", 'k': "b", 'v': "c", '1': "d", 'j': "e", 'u': "f", '2': "g", 'i': "h",
't': "i", '3': "j", 'h': "k", 's': "l", '4': "m", 'g': "n", '5': "o", 'r': "p",
'q': "q", '6': "r", 'f': "s", 'p': "t", '7': "u", 'e': "v", 'o': "w", '8': "1",
'd': "2", 'n': "3", '9': "4", 'c': "5", 'm': "6", '0': "7",
'b': "8", 'l': "9", 'a': "0", '_z2C$q': ":", "_z&e3B": ".", 'AzdH3F': "/"}
url = re.sub(r'(?P_z2C\$q|_z\&e3B|AzdH3F+)', lambda matched: table.get(matched.group('value')),
objURL)
new_img = re.sub(r'(?P[0-9a-w])', lambda matched: table.get(matched.group('value')), url)
print(new_img)
break
break
图片保存到本地:
# -*- coding:utf-8 -*-
# TODO 有阳光的地方就会有希望
import requests,re,os
from urllib.request import urlretrieve
for x,i in enumerate(range(0,100000000000,30)):
url_img = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&word=花草&pn={}'.format(i)
response = requests.get(url_img).json()
for data in response['data']:
if data:
objURL = data['objURL']
table = {'w': "a", 'k': "b", 'v': "c", '1': "d", 'j': "e", 'u': "f", '2': "g", 'i': "h",
't': "i", '3': "j", 'h': "k", 's': "l", '4': "m", 'g': "n", '5': "o", 'r': "p",
'q': "q", '6': "r", 'f': "s", 'p': "t", '7': "u", 'e': "v", 'o': "w", '8': "1",
'd': "2", 'n': "3", '9': "4", 'c': "5", 'm': "6", '0': "7",
'b': "8", 'l': "9", 'a': "0", '_z2C$q': ":", "_z&e3B": ".", 'AzdH3F': "/"}
url = re.sub(r'(?P_z2C\$q|_z\&e3B|AzdH3F+)', lambda matched: table.get(matched.group('value')),objURL)
new_img = re.sub(r'(?P[0-9a-w])', lambda matched: table.get(matched.group('value')), url)
name = data['di']
file = './img/'
# 第一种方式 保存图片
try:
urlretrieve(new_img,filename=file + f'{name}.jpg')
except:
print('图片下载失败')
# 第二种方式 保存图片
try:
if not os.path.exists("./img/"):
os.makedirs("./img/")
image_con = requests.get(url=new_img).content
with open(file + f'{name}.jpg','wb') as f:
f.write(image_con)
except:
print('图片链接失效或下载失败')
break
break
小伙伴们加油!努力奋斗!。。。。