csv逗号分隔符转换_pythonpandas读写csv数据

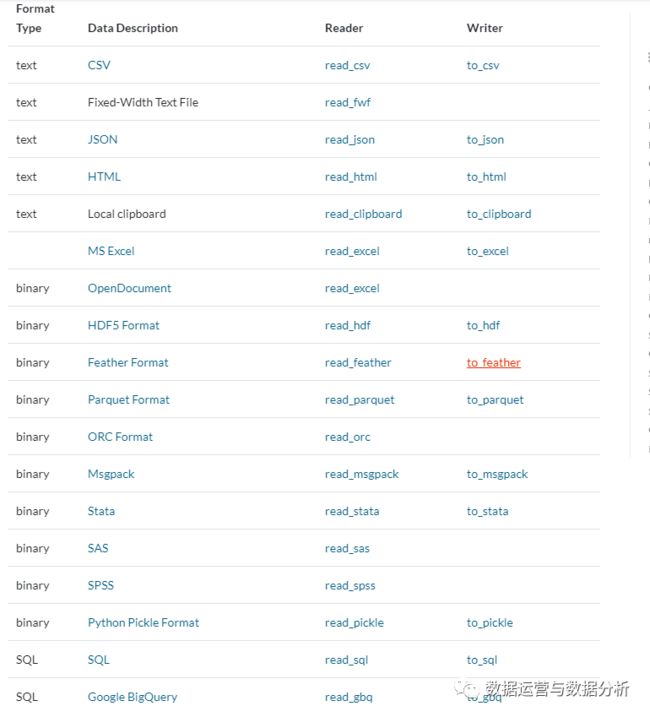
一、使用pandas读取和写入csv文件
pandas.read_csv()语法: 1、使用pandas读取csv文件的全部数据:- pd.read_csv("filepath",[encoding='编码'])
- pd.read_csv("filepath",usecols=[0,1,2,...],[encoding='编码'])
- pd.read_csv("filepath",[skiprows=n],nrows=m,[encoding='编码'])
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)常用参数解释:
- filepath_or_buffer #需要读取的文件及路径
- sep / delimiter 列分隔符,普通文本文件,应该都是使用结构化的方式来组织,才能使用dataframe
- header 文件中是否需要读取列名的一行,header=None(使用names自定义列名,否则默认0,1,2,...),header=0(将首行设为列名)
- names 如果header=None,那么names必须制定!否则就没有列的定义了。
- shkiprows= 10 # 跳过前十行
- nrows = 10 # 只去前10行
- usecols=[0,1,2,...] #需要读取的列,可以是列的位置编号,也可以是列的名称
- parse_dates = ['col_name'] # 指定某行读取为日期格式
- index_col = None /False /0,重新生成一列成为index值,0表示第一列,用作行索引的列编号或列名。可以是单个名称/数字或由多个名称/数字组成的列表(层次化索引)
- error_bad_lines = False # 当某行数据有问题时,不报错,直接跳过,处理脏数据时使用
- na_values = 'NULL' # 将NULL识别为空值
- encoding='utf-8' #指明读取文件的编码,默认utf-8
# 案例:
import numpy as npimport pandas as pdimport warningswarnings.filterwarnings("ignore")print(np.__version__)print(pd.__version__)df = pd.read_csv(r"student.csv", header = None, sep=",",encoding="utf-8") #header = None,默认列名=0,1,2,3,...df1 = pd.read_csv(r"student.csv", header = None,names=["id","name","sex","age","grade"], sep=",") #自定义列名df2 = pd.read_csv(r"student.csv",header = None,index_col=None, sep=",") #默认自行生成行索引0,1,...df3 = pd.read_csv(r"student.csv",header = None,index_col=[0], sep=",") #指定第1列作为行索引df4 = pd.read_csv(r"student.csv",header=None,names=["id","name","sex","age","grade"],index_col=["name"], sep=",") #指定name列作为行索引df5 = pd.read_csv(r"student.csv",header=None,usecols=[1,2,3],names=["name", "sex", "age"],index_col=0,sep=",") #指定列display(df.head(3), df1.head(3), df2.head(3), df3.head(3), df4.head(3), df5.head(3))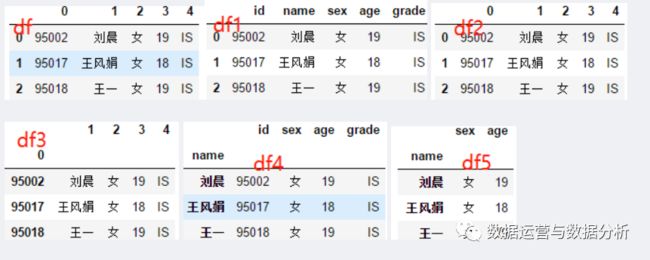
1、使用pandas读取csv文件的全部数据:
pd.read_csv("filepath",[encoding='编码'])
如果存在编码(乱码)问题: (1)用记事本打开csv文件,另存为,编码格式改为utf-8然后用utf-8读取文件。 (2)用 csv编码的 “GB18030” 解码方式读取文件。 另外,由于python不支持中文,故一般在所有python代码开头第一行加上#coding=utf-8In [1]: import numpy as npIn [2]: import pandas as pdIn [3]: df = pd.read_csv("E:\student.csv")In [4]: print(df) 95002 刘晨 女 19 IS0 95017 王风娟 女 18 IS1 95018 王一 女 19 IS...20 95016 钱国 男 21 MAIn [5]: df = pd.read_csv("E:\student.csv",encoding='utf-8')In [6]: print(df) 95002 刘晨 女 19 IS0 95017 王风娟 女 18 IS1 95018 王一 女 19 IS...20 95016 钱国 男 21 MAIn [1]: import numpy as npIn [2]: import pandas as pdIn [36]: df = pd.read_csv("e:\student.csv",encoding='utf-8')In [37]: print(df) 编码 姓名 性别 年龄 班级0 95002 刘晨 女 19 IS1 95017 王风娟 女 18 IS2 95018 王一 女 19 IS2、使用pandas读取csv文件的指定列方法:pd.read_csv("filepath",usecols=[0,1,2,...],[encoding='编码'])
In [1]: import numpy as npIn [2]: import pandas as pdIn [38]: df = pd.read_csv("e:\student.csv",usecols=[0,1,2,4],encoding='utf-8')In [39]: print(df) 编码 姓名 性别 班级0 95002 刘晨 女 IS1 95017 王风娟 女 ISIn [1]: import numpy as npIn [2]: import pandas as pdIn [40]: df = pd.read_csv("e:\student.csv",usecols=['姓名','班级'],encoding='utf-8')In [41]: print(df) 姓名 班级0 刘晨 IS1 王风娟 IS2 王一 IS...3、使用pandas读取csv文件的指定行方法:pd.read_csv("filepath",[skiprows=n],nrows=m,[encoding='编码'])
pd.read_csv(路径,skiprows=n,nrows=m),忽略前n行,往下读m行In [1]: import numpy as npIn [2]: import pandas as pdIn [47]: df = pd.read_csv("e:\student.csv",skiprows=5,nrows=2,encoding='utf-8')In [48]: print(df) 95014 王小丽 女 19 CS0 95019 邢小丽 女 19 IS1 95020 赵钱 男 21 IS
二、使用pandas写入CSV文件
df.to_csv(path_or_buf,[sep=',' , na_rep=' ', ....])
写入csv文件是最常用的,csv文件默认用’,’作为分隔符。df.to_csv(path_or_buf=None, sep=’,’, na_rep=”, float_format=None, columns=None, header=True, index=True, index_label=None, mode=’w’, encoding=None)参数说明:
- path_or_buf:文件名、文件具体、相对路径、文件流等
- sep:文件分割符号,to_csv()的sep默认为’,’,可指定任意字符作为分隔符
- na_rep:将NaN转换为特定值。写入时NaN会被表示为空字符串,我们可能希望用其他值代替,如:‘- ’、‘/’、'NULL' 等
- columns:选择部分列写入。保留部分列且按列排序,columns=['B列列名','A列列名']
- header:忽略列名,header=None 不写入列名
- index:index=False 表示选择不写入索引
In [1]: import numpy as npIn [2]: import pandas as pd In [3]: df = pd.read_csv("e:\student.csv")In [4]: print(df) 编码 姓名 性别 年龄 班级0 95002 刘晨 女 19 IS1 95017 王风娟 女 18 IS2 95018 王一 女 19 IS In [5]: df.to_csv("e:\student01.csv",sep=",",columns=['姓名','班级'],index=True)In [6]: df = pd.read_csv('e:\student01.csv')In [7]: print(df) Unnamed: 0 姓名 班级0 0 刘晨 IS1 1 王风娟 IS2 2 王一 IS