前言
之前简单学习过python爬虫基础知识,并且用过scrapy框架爬取数据,都是直接能用xpath定位到目标区域然后爬取。可这次碰到的需求是爬取一个用asp.net编写的教育网站并且将教学ppt一次性爬取下来,由于该网站部分内容渲染采用了js,所以比较难用xpath直接定位,同时发起下载ppt的请求比较难找。
经过琢磨和尝试后爬取成功,记录整个爬取思路供自己和大家学习。文章比较详细,对于一些工具包和相关函数的使用会在源代码或正文中添加注释来介绍简单相关知识点,如果某些地方看不懂可以通过注释及时去查阅简单了解,然后继续阅读。(尾部有源代码,全文仅对一些敏感的个人信息数据进行了省略。)
一、主要思路
1、观察网站
研究从进入网站到成功下载资源需要几次url跳转。
先进入目标网站首页,依次点击教材->选择初中->选择教辅->选择学科->xxx->资源列表->点击下载ppt。
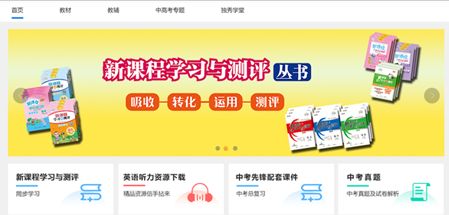
目标网站首页
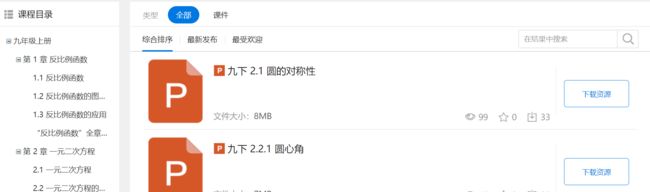
资源列表

资源详情页
分析url每步跳转以及资源下载是否需要cookie等header信息。
通过一步步跳转进入到最终的资源详情页,最终点击下载资源按钮时网站提示并且跳转到了登陆页面,说明发起下载的请求可能需要携带cookie等头部信息。
2、编写爬虫代码
- 登陆账户,获取到识别用户的cookies
- 请求资源列表页面,定位获得左侧目录每一章的跳转url。
- 请求每个跳转url,定位资源列表页面右侧下载资源按钮的url请求(注意2、3步是图资源列表)
- 发起url请求,进入资源详情页,定位获得下载资源按钮的url请求(第4步是图资源详情页)
- 发起请求,将下载的资源数据写入文件。
这是本次爬虫实战编写代码的大致思路,具体每次步骤碰到的难点以及如何解决在接下来的实战介绍中会进行详细分析。
二、爬虫实战
1、登陆获取cookie
首先网站登陆,获取到cookie和user-agent,作为之后请求的头部。设置全局变量HEADER,方便调用
HEADER = {
'User-Agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko)Chrome/93.0.4577.63 Safari/537.36", 'Cookie':"xxxxxxx",
}
2、请求资源列表页面,定位获得左侧目录每一章的跳转url(难点)
首先使用requests发起资源列表页面的请求
资源列表
BASE_URL = "http://www.guishiyun.com" #赋值网站根域名作为全局变量,方便调用
res = requests.get(BASE_URL +
"/res_list.aspx?rid=9&tags=1-21,12-96,2-24,3-70",
headers=HEADER).text #发起请求,获得资源列表页面的html
难点:定位获得左侧目录每一章的跳转url
正常思路:打开浏览器控制台,查看网页源代码,寻找页面左侧课程目录的章节在哪个元素内,用xpath定位。
![]()
使用xpath定位,发现无法定位到这个a标签,在确认xpath语法无错误后,尝试打印上个代码段中的res变量(也就是该html页面),发现返回的页面和控制台页面不同。
转换思路:可能该页面使用其他渲染方式渲染了html,导致浏览器控制台看到的html和请求返回的不一样(浏览器会将渲染后的页面呈现),打开控制台,查看页面源代码,搜素九年级上册(左侧目录标题),发现在js的script脚本中,得出该页面应该是通过JS渲染DOM得来的,该js对象中含有跳转的url。
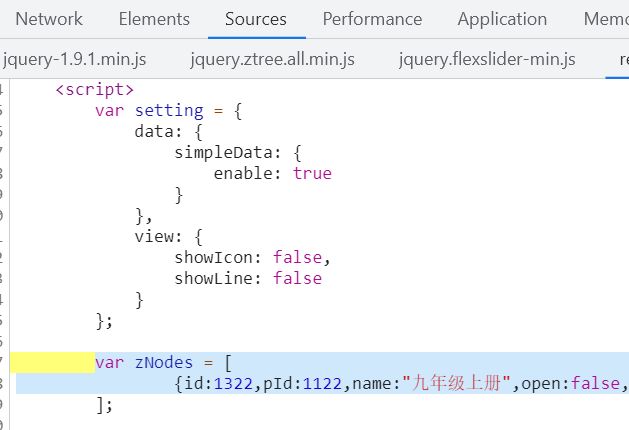
xpath行不通后,我选择采用正则表达式的方式直接筛选出该代码。
import re #导入re 正则表达式包 pattern = r'var zNodes = (\[\s*[\s\S]*\])' #定义正则表达式,规则:找出以"var zNodes = [ \n"开头,含有"[多个字符或空格]"的字符,并且以"]"结尾的文本 (相关知识不熟悉的可以简单看看菜鸟的正则表达式) result = re.findall(pattern, res, re.M | re.I) #python正则表达式,查找res中符合pattern规则的文本。re.M多行匹配,re.I忽略大小写。
将前两个代码块封装一下
def getRootText():
res = requests.get(BASE_URL +
"/res_list.aspx?rid=9&tags=1-21,12-96,2-24,3-70",
headers=HEADER).text #请求
pattern = r'var zNodes = (\[\s*[\s\S]*\])'
result = re.findall(pattern, res, re.M | re.I)
return result[0] #获得筛选结果 [{id: 1322, pI': 1122, name: '九年级上册', open: False, url: ?catId=1322&tags=1-21%2c12-96%2c2-24%2c3-70&rid=9#bottom_content', target: '_self'}, {...},{...}]
将结果转换成dict类型,方便遍历,获得每个章节的url。浏览上面得出的result发现,{id:1322,pId:xxx...}并不是标准的json格式(key没有引号),此时使用第三方包demjson,用于将不规则的json字符串变成python的dict对象。
import demjson
def textToDict(text):
data = demjson.decode(text)
#获得筛选结果[{'id': 1322, 'pId': 1122, 'name': '九年级上册', 'open': False, 'url': '?catId=1322&tags=1-21%2c12-96%2c2-24%2c3-70&rid=9#bottom_content', 'target': '_self'}, {...},{...}]
return data
遍历转换好的dict数据,获得左侧目录每一章的url。此处需要注意的是,本人目的是下载每一章的ppt课件,所以我只需要请求每一个总章节的url(即请求第 1 章,第 2 章,不需要请求 1.1反比例函数),右边就会显示该章节下的所有ppt课件。所以我在遍历的时候,可以通过正则表达式,筛选出符合名称要求的url,添加进list并且返回。
def getUrls(dictData):
list = []
pattern = r'第[\s\S]*?章' #正则规则:找出以"第"开头,中间包含多个空格和文字,以"章"结尾的文本
for data in dictData: #遍历上文转换得到的dict数组对象
if len(re.findall(pattern, data['name'])) != 0:
list.append(data['url']) #如果符合则将该url添加到列表中
return list
3、请求每个跳转url,定位右侧下载资源按钮,获得url请求
遍历从上面获得的url列表,通过拼接网站域名获得网站url,然后发起请求
def download(urlList): # urlList是上面获得的list
for url in urlList:
res = requests.get(BASE_URL + '/res_list.aspx/' + url, HEADER).text #完整url请求,获得页面html
查看源代码,发现可以用xpath定位(目标是获取到onclick里的url)

分析:该按钮元素 ( 遍历 4、跳转到资源详情下载页,获得真正的下载请求(难点) 上文代码段中获取到url之后依旧是拼接域名,然后通过完整url发起请求,获得资源详情下载页面的html数据。 跳转后的详情页面 查看源代码后按钮本身只是触发表单提交,而且是 使用 此时发起请求之后发现返回的仍然是网页html,如果打开控制台工具,查看点击按钮发起请求后的页面。 同时看到由于是更新页面,还产生了许多其他各种各样的请求,一时间很难找到真正下载文件的请求是哪一个。 此时笔者想到的是一个笨方法,通过抓包工具,对所有请求进行拦截,然后一个个请求陆续通过,最终就可以找到下载请求。这里笔者用到的是 不用多说,直接正则获取 发起请求,并且将数据读写进指定的目录中。 结果 5、添加额外功能,实现增量爬虫 爬取到一半发现程序终止了,原来该网站对每个账号每天下载数有限额,而我们的程序每次运行都会从头开始检索,如何对已经爬取过的url进行存储,同时下次程序运行时对已爬取过的url进行识别?这里笔者使用的是通过 6、总源代码 之前只是学习过最简单最基础的 到此这篇关于python动态网站爬虫实战(requests+xpath+demjson+redis)的文章就介绍到这了,更多相关python动态网站爬虫 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!)在
root = etree.HTML(res) # 构造一个xpath对象
liList = root.xpath('//div[@class="res_list"]//ul//li') #xpath语法,返回多个liList ,获得资源名字(为之后下载写入ppt的文件命名)以及跳转到资源详情下载页的url
for li in liList:
name = li.xpath('.//div[@class="info_area"]//div//h1//text()')
name = name[0] # xpath返回的是包含name的列表,从中提取字符串 print(name): 1.1 反比例函数
btnurl = li.xpath('.//div[@class="button_area"]//@onclick') # 获得onlick内的字符串 "window.open('res_view.aspx....')"
pattern = r'\(\'([\s\S]*?)\'\)'# 只需要window.open内的url,所以采用正则提取出来。
btnurl1 = re.findall(pattern, btnurl[0])
res1 = requests.get(BASE_URL + '/' + btnurl1[0], HEADER).text
post请求。点击下载资源按钮,使用浏览器控制台抓包查看post请求需要的参数。
ctrl+f在网页源代码中搜素这几个参数,发现存在于 标签中,只是被css 隐藏了,所以接下来就是简单的用xpath 和正则表达式将post请求中的url和这几个参数值获得,然后添加到header中发起请求就行了。
VIEWSTATE = '__VIEWSTATE' # 全局变量,定义属性名称
VIEWSTATEGENERATOR = '__VIEWSTATEGENERATOR'
EVENTVALIDATION = '__EVENTVALIDATION'
BUTTON = 'BUTTON'
BUTTON_value = '下 载 资 源'
root1 = etree.HTML(res1) # res1是之前代码段请求的html文本
form = root1.xpath('//form[@id="form1"]') # xpath定位到form
action = root1.xpath('//form[@id="form1"]/@action')
action = re.findall(r'(/[\S]*?&[\S]*?)&', action[0], re.I) #正则表达式获取form中action函数里的url
VIEWSTATE_value = form[0].xpath(
'.//input[@name="__VIEWSTATE"]//@value') #获取参数值
VIEWSTATEGENERATOR_value = form[0].xpath(
'.//input[@name="__VIEWSTATEGENERATOR"]//@value')#获取参数值
EVENTVALIDATION_value = form[0].xpath(
'.//input[@name="__EVENTVALIDATION"]/@value')#获取参数值
data = { # post提交所需要的data参数
VIEWSTATE: VIEWSTATE_value,
VIEWSTATEGENERATOR: VIEWSTATEGENERATOR_value,
EVENTVALIDATION: EVENTVALIDATION_value,
BUTTON: BUTTON_value
}
res2 = requests.post(BASE_URL + action[0],data=data,headers=HEADER).text #发起请求

BurpSuite 工具,陆续放行请求,观察页面是否有下载界面出现,找到了url:/code/down_res.ashx?id=xxx ,同时在浏览器控制台查找这一串字符串,最终在post请求返回的页面中找到了这个字符串的位置![]()
downUrl = re.search(r'\
downPPT = requests.get(BASE_URL+downUrl_text,headers=HEADER)
with open(f'./test/{name}.ppt','wb') as f: #将下载的数据以二进制的形式写入到当前项目下test文件夹中,并且做好命名。name参数在上文中已经获得。
f.write(downPPT.content)
redis进行存储,原理是对每次下载的url进行存储,在每次发起下载请求时先判断是否已经存储,如果已经存储则跳过本次循环。
if(r.sadd(BASE_URL + action[0],'1')==0): # sadd是redis添加键值的方法,如果==0说明已经存在,添加失败。
continue
import re
import requests
from lxml import etree
import demjson
import redis
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis('localhost',6379,decode_responses=True)
BASE_URL = "http://www.guishiyun.com"
HEADER = {
'User-Agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36",
'Cookie':
"xxx",
}
VIEWSTATE = '__VIEWSTATE'
VIEWSTATEGENERATOR = '__VIEWSTATEGENERATOR'
EVENTVALIDATION = '__EVENTVALIDATION'
BUTTON = 'BUTTON'
BUTTON_value = '下 载 资 源'
def getRootText():
res = requests.get(BASE_URL +
"/res_list.aspx?rid=9&tags=1-21,12-96,2-24,3-70",
headers=HEADER).text
pattern = r'var zNodes = (\[\s*[\s\S]*\])'
result = re.findall(pattern, res, re.M | re.I)
return result[0]
def textToDict(text):
data = demjson.decode(text)
print(data)
return data
def getUrls(dictData):
list = []
pattern = r'第[\s\S]*?章'
for data in dictData:
if len(re.findall(pattern, data['name'])) != 0:
list.append(data['url'])
return list
def download(urlList):
global r
for url in urlList:
res = requests.get(BASE_URL + '/res_list.aspx/' + url, HEADER).text
root = etree.HTML(res)
liList = root.xpath('//div[@class="res_list"]//ul//li')
for li in liList:
name = li.xpath('.//div[@class="info_area"]//div//h1//text()')
name = name[0]
btnurl = li.xpath('.//div[@class="button_area"]//@onclick')
pattern = r'\(\'([\s\S]*?)\'\)'
btnurl1 = re.findall(pattern, btnurl[0])
res1 = requests.get(BASE_URL + '/' + btnurl1[0], HEADER).text
root1 = etree.HTML(res1)
form = root1.xpath('//form[@id="form1"]')
action = root1.xpath('//form[@id="form1"]/@action')
action = re.findall(r'(/[\S]*?&[\S]*?)&', action[0], re.I)
VIEWSTATE_value = form[0].xpath(
'.//input[@name="__VIEWSTATE"]//@value')
VIEWSTATEGENERATOR_value = form[0].xpath(
'.//input[@name="__VIEWSTATEGENERATOR"]//@value')
EVENTVALIDATION_value = form[0].xpath(
'.//input[@name="__EVENTVALIDATION"]/@value')
data = {
VIEWSTATE: VIEWSTATE_value,
VIEWSTATEGENERATOR: VIEWSTATEGENERATOR_value,
EVENTVALIDATION: EVENTVALIDATION_value,
BUTTON: BUTTON_value
}
if(r.sadd(BASE_URL + action[0],'1')==0):
continue
res2 = requests.post(BASE_URL + action[0],data=data,headers=HEADER).text
downUrl = re.search(r'\
三、总结
requests请求+xpath 定位的爬虫方式,这次碰巧遇到了较为麻烦的爬虫实战,所以写下爬虫思路和实战笔记,加深自己印象的同时也希望能对大家有所帮助。当然这次爬虫总的来说还是比较简单,还没有考虑代理+多线程等情况,同时还可以使用selenium等浏览器渲染工具,就可以不用正则定位了,当然笔者是为了顺便学习一下正则。