python数据分析案例-利用生存分析Kaplan-Meier法与COX比例风险回归模型进行客户流失分析与剩余价值预测
目录
-
- 1. 概述
-
- 1.1 背景
- 1.2 目的
- 1.3 数据说明
- 2. 相关概念
-
- 2.1 事件
- 2.2 生存时间
- 2.3 删失
- 2.4 生存概率
- 2.5 中位生存时间
- 2.6 风险概率
- 3. 数据处理
- 4. 生存概率
-
- 4.1 Kaplan-Meier法
- 4.2 log rank检验
- 4.3 代码
- 4.4 分层检验
- 4.5 成对比较
- 5 风险概率
-
- 5.1 COX比例风险回归
- 5.2 变量选择
- 5.3 建模
- 5.4 PH假定
- 5.5 特征重要性分析
- 5.6 校准
- 5.7 剩余价值预测
- 5.8 剩余价值提升
- 6. 结论
1. 概述
1.1 背景
什么是生存分析?
生存分析,是指根据试验或调查得到的数据对生物或人的生存时间进行分析和推断,研究生存时间和结局与众多影响因素间关系及其程度
大小的方法。
生存分析与回归、分类模型的区别?
一般的分类模型处理的是截面数据,模型输出结果是特定时间截面下的事件发生概率,给定观察时间窗(如一周、一个月等),在观察时间窗结束时,用户的行为可以划分为流失与未流失两类,但是这样的做法只关心结果,无法精细反映客户流失概率与时间线的关系,也难以预测特征前后变化对于流失的影响。关于如何预测客户是否流失,可以参考本人使用本文相同数据集的博客- Python机器学习案例-使用集成学习进行客户流失预测
与只关注结果的模型不同,生存分析既关注事件结果又关注结果发生时间。既研究结果影响因素,又研究影响因素与结果出现时间长短之间的关系,是研究生存现象(事件结果)和发生时间关系及统计规律的一门学科。
生存分析可以干什么?
我们可以利用生存分析中的Kaplan-Meier法来分析用户的生存概率,一般用来比较不同组间的生存情况,比如研究电信客户流失时,根据客户是否订阅了流媒体电视分为两类,分析哪类客户拥有更好的留存率;使用Cox比例风险回归模型来探讨影响生存的风险因子,比如客户的性别、月费、合伙人和电话服务等协变量对于生存影响。
1.2 目的
本文使用Python lifelines库分析影响电信客户流失的特征,客户流失概率预测,以及预测客户的生命周期价值。
1.3 数据说明
数据来源kaggle公开数据集(链接点击),共21个特征,7043行数据。
不便注册下载的朋友可点击网盘下载
链接:https://pan.baidu.com/s/1rzt0WPYVaPZkWxKqyhM2oQ
提取码:vc9r
2. 相关概念
2.1 事件
事件分为起始事件和终点事件。起始事件即生存分析的起点事件,所有研究对象的起始事件均相同;终点事件指研究关注的具体事件,生存分析中部分研究对象可以观察到关注事件发生,能够获取准确的发生时间,为分析提供完全信息。
2.2 生存时间
生存时间不关注事件发生的客观时间,只关注从起始事件开始到终点事件发生之间的时间间隔。例如,病人治愈所花费的时间;首婚人群的婚姻持续时间;某个系统在故障前良好运转的时间等。
生存时间不呈正态分布,因此不能用生态分布假设对生存时间分布参数进行估计。
2.3 删失
某些研究对象在观察时间窗内无法获取事件发生时间,我们将这种情况称为删失,其中以右删失最为常见,右删失是指已知研究对象的观察起始时间,但无法获取终点事件发生的具体时间。
产生删失的可能原因
(1) 到达研究截止日期时,终点事件仍然没有发生,研究对象依然存活
(2) 研究对象因为搬迁、更换电话号码等原因失去联系造成失访,无法明确观察到研究对象是否发生了终点事件,以及具体的发生时间
(3) 研究对象不配合、或医生改变治疗方案等其他原因,造成研究对象中途退出研究,无法继续进行随访观察
(4) 研究对象死于其他事件,例如死于交通事故,或者因其他疾病造成死亡
删失分类:
-
右删失(Right censored):起点已知,终点不确定(最常见)
-
左删失(Left censored):起点无法确定
-
区间删失(Interval censored):连续的观察随访中,已知发生终点事件,但起点未知
2.4 生存概率
生存概率指的是研究对象从试验开始直到某个特定时间点仍然存活的概率,可见它是一个对时间t的函数,我们定义之为 S(t); 表示观察对象生存时间越过时间点t的概率,t=0时生存函数取值为1,随时间延长生存函数逐渐减小。
生存函数:生存函数是每个时刻生存概率的乘积,故也称为累积生存概率函数。
常见分析方法:Kaplan-Meier法、Nelson-Aalen法
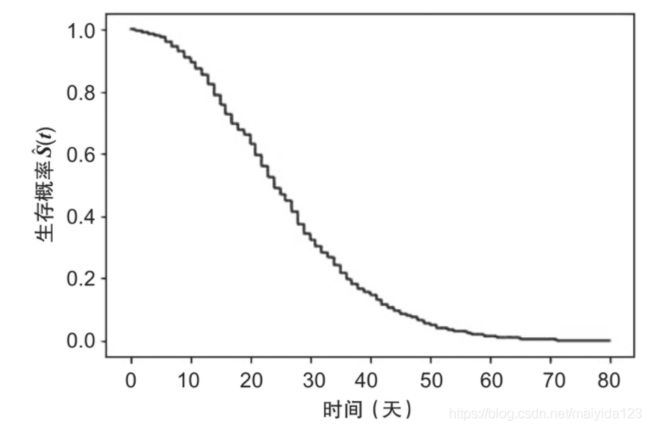
生存曲线:以生存时间为横轴、生存函数为纵轴连成的曲线。
生存曲线示意图:
2.5 中位生存时间
中位生存时间也可以称为半衰期,指恰好一半个体未发生终点事件的时间。由于删失的存在,无法直接以平均时间反应事件发生的时间水平,因此生存分析在描述生存时间时一般以半衰期,也就是存活概率50%时对应消耗的时间来表述。同理,也可以基于需要计算存活概率到其他百分位数量的消耗时间。

2.6 风险概率
风险概率也可以称为条件死亡率,指的是研究对象从试验开始到某个特定时间 t 之前存活,但在 t 时间点发生观测事件如死亡的概率,它也是对时间 t 的函数,定义为 H(t)。
F(t)为积累分布函数(Cumulative Distribution Function),F(t)=1-S(t),表示生存时间未超过时间点t的概率。累积风险函数H(t)=-logS(t)。
常见分析方法:Cox 风险比例回归模型
在大致了解了生存分析的相关概念之后,下面开始进入正文。
3. 数据处理
加载库与数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from lifelines import KaplanMeierFitter, CoxPHFitter
from lifelines.statistics import logrank_test, multivariate_logrank_test
from sklearn.model_selection import train_test_split, GridSearchCV
from lifelines.utils.sklearn_adapter import sklearn_adapter
from sklearn import metrics
import time
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings("ignore")
data = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
各特征的说明如下:

事件为Churn流失,生存时间为tenure使用月数
数据处理
# 删除ID列
data.drop("customerID", axis=1, inplace=True)
# 转换成连续型变量
data['TotalCharges'] = pd.to_numeric(data.TotalCharges, errors='coerce')
# 去掉TotalCharges的缺失值,一共11条数据
data.dropna(subset=['TotalCharges'], inplace=True)
# 重置索引
data = data.reset_index().drop('index',axis=1)
# 转换成类别变量
data.SeniorCitizen = data.SeniorCitizen.astype("str")
# 将是否流失转换为01分布
data.Churn = data.Churn.map({
'No':0,'Yes':1})
# 生成哑变量
df = pd.get_dummies(data)
处理完毕!
4. 生存概率
4.1 Kaplan-Meier法
目前,对生存函数及风险函数的刻画方法分为非参数和参数两类。其中,最常用的是非参数方法中对生存函数进行刻画的Kaplan-Meier曲线法和对累积风险函数进行刻画的Nelson-Aalen曲线法。KM曲线法作为一种非参数方法,不对数据分布做任何假设,而是直接用概率乘法定理估计生存率。这一方法的优势在于能够直观地观察生存曲线,便于不同生存曲线之间进行简单对比,但无法建立数学模型对多个影响因素进行分析。
Kaplan–Meier 方法的主要思路,一共有 m 个时间点,每个时间点用下标 i 来表示, i 为从 1 到 m 的整数, 生存概率 S(ti) 可以表示为:

其中,ti 表示第 i 个时间点,ni 表示在 ti 之前的有效人数,di 表示在 ti 死亡的人数,S(ti-1) 表示在上一个时间点 i-1 的生存概率。
4.2 log rank检验
我们可以通过对研究对象进行分组,绘制多条生存曲线,但只通过直接观察无法确定曲线之间是否具有显著性差异,还需要引入严谨的统计检验方法。其中,对数秩检验log rank test在生存曲线的比较中应用最为广泛。
对数秩检验是一种非参数检验方法,检验的原假设是不同分组之间的生存率没有显著差异。在原假设为真的条件下,对数秩检验以整体的风险概率作为理论风险概率计算理论事件数,通过将真实事件数与理论事件数进行对比,判断生存曲线之间是否存在显著差异。
用对数秩检验比较时,要求各组生存曲线不能交叉,如果有交叉则提示可能存在混杂因素,此时应进行样本分层或多因素的方法校正混杂因素。
4.3 代码
查看总体数据的生存曲线
fig, ax = plt.subplots(figsize=(10,8))
kmf = KaplanMeierFitter()
kmf.fit(data.tenure, # 代表生存时长
event_observed=data.Churn, # 代表事件的终点
)
kmf.plot_survival_function(at_risk_counts=True,ax=ax)
plt.show()

从图上可以看到,经过了72个月(我们数据中的最大期限) ,电信公司仍然可以保留60% 或更多的客户。
图底部的数据:
- At-risk: 被观察到的使用时长超过时间点的客户数量。例如,2757名客户的使用时长超过40个月。
- Censored: 使用时长小于等于时间点的未流失顾客数量。例如,2709名客户的使用时长小于等于40个月,仍未流失。
- Events: 使用时长小于等于时间点的流失客户数量。例如,1566名客户没有使用到40个月时就已流失。
被审查的: 任期等于或小于时间点的未流失的顾客数量。例如,3860名顾客的任期不超过60个月,但他们当时并没有流失
三个指标之和等于总数量,简单的代码即可计算出这三个数字,以时间点为40个月为例:
print('At risk:', data.query("tenure>40").tenure.count())
print('Censored:', data.query("tenure<=40 & Churn == 0").tenure.count())
print('Events:', data.query("tenure<=40 & Churn == 1").tenure.count())

结果与上图一致。
查看各个协变量对于客户流失的影响
首先,因为Kaplan-Meier法无法对连续型变量处理,我们将连续型变量按照中位数分层,进行对比
data['MonthlyCharges_median'] = data['MonthlyCharges'].apply(lambda x : '1' if x>=data['MonthlyCharges'].median() else '0')
data['TotalCharges_median'] = data['TotalCharges'].apply(lambda x : '1' if x>=data['TotalCharges'].median() else '0')
其次,将所有需要比较的协变量绘制生存曲线,并进行对数秩检验
obj_list = data.select_dtypes(include="object").columns
fig, ax = plt.subplots(nrows=9, ncols=2, figsize=(24,72))
for nrow in range(9):
for ncol in range(2):
feature = obj_list[ncol*9 + nrow]
for i in data[feature].unique():
# KaplanMeier检验
kmf=KaplanMeierFitter()
df_tmp = data.loc[data[feature] == i]
kmf.fit(df_tmp.tenure, # 代表生存时长
event_observed=df_tmp.Churn, # 代表检验的组别
label=i)
# 绘制生存曲线
kmf.plot_survival_function(ci_show=False,
ax = ax[nrow][ncol]) # at_risk_counts=True,为显示各时间节点的预测流失人数
# 对数秩检验,得到p值
p_value = multivariate_logrank_test(event_durations = data.tenure, # 代表生存时长
groups=data[feature], # 代表检验的组别
event_observed=data.Churn # 代表事件的终点
).p_value
p_value_text = ['p-value < 0.001' if p_value < 0.001 else 'p-value = %.4F'%p_value][0]
ax[nrow][ncol].set_title("survival curves of {}\n logrank test {}".format(feature, p_value_text))
结果:

由上我们可以看到:
- gender性别与PhoneService电话服务组间均没有显著性差异,其余的变量均有显著性差异
- 对于没有显著性差异的变量,可以尝试加入分层变量,看看在不同的分层下是否存在差异
- 对于有显著性差异且组间变量超过两个的,可以通过成对比较,找出哪些组建变量有差异
每个变量的单独解读这里就不占篇幅了。
4.4 分层检验
以性别为例
for feature in obj_list.drop('gender'):
for i in data[feature].unique():
df_tmp = data.loc[data[feature] == i]
p_value = multivariate_logrank_test(event_durations = df_tmp.tenure,
groups=df_tmp.gender,
event_observed=df_tmp.Churn
).p_value
if p_value <= 0.05:
p_value_text = ['p-value < 0.001' if p_value < 0.001 else 'p-value = %.4F'%p_value][0]
print('gender : {}={}, logrank test {}'.format(feature, i, p_value_text))
结果:
![]()
在所有的变量中,只有在支付方式为信用卡自动转账时,不同性别的生存概率差异显著,使用KaplanMeier绘制生存曲线查看
fig,ax = plt.subplots(figsize=(12,8))
data_male = data.loc[(data.gender=='Male') & (data.PaymentMethod == 'Credit card (automatic)')]
kmf_male = KaplanMeierFitter().fit(data_male.tenure,
data_male.Churn,
label='Male : PaymentMethod=Credit card (automatic)')
ax = kmf_male.plot_survival_function(ax=ax)
data_female = data.loc[(data.gender=='Female') & (data.PaymentMethod == 'Credit card (automatic)')]
kmf_female = KaplanMeierFitter().fit(data_female.tenure,
data_female.Churn,
label='Female : PaymentMethod=Credit card (automatic)')
ax = kmf_female.plot_survival_function(ax=ax)
from lifelines.plotting import add_at_risk_counts
add_at_risk_counts(kmf_female, kmf_male, ax=ax)
plt.tight_layout()
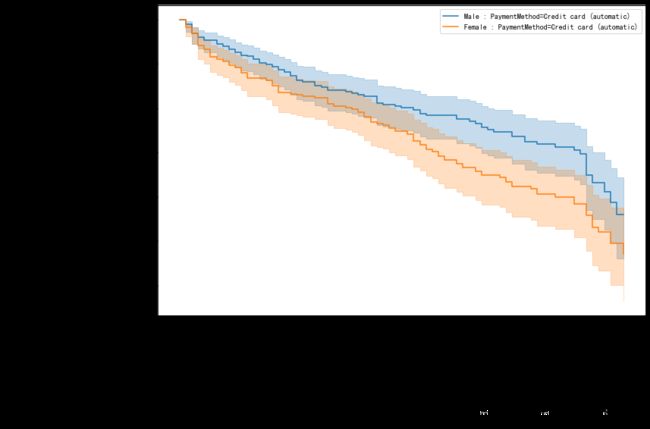
由上图可看到
- 在信用卡自动转账的客户中,女性比男性更容易流失
- 女性用户在第3个月与男性用户在第66个月时的流失客户较多,需要重点关注。
4.5 成对比较
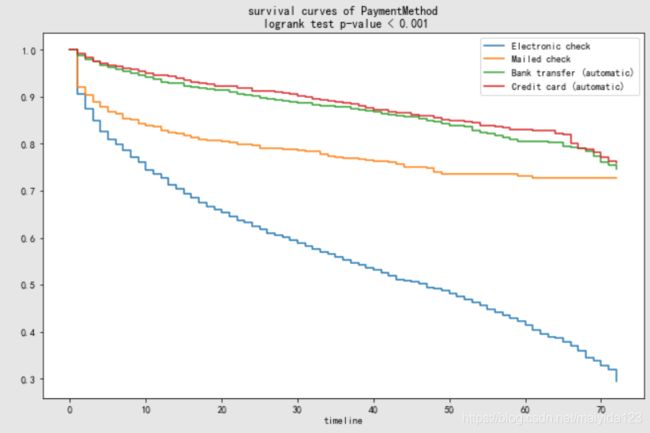
面对如上图的变量,其组间变量在两个以上,虽然multivariate_logrank_test判断其至少一组变量存在显著性差异,但是想要找出哪些变量间有差异,哪些变量间没有差异,这时我们可以使用pairwise_logrank_test做成对比较。
pairwise_logrank_test(
event_durations = data.tenure,
groups=data.PaymentMethod,
event_observed=data.Churn
)
结果:
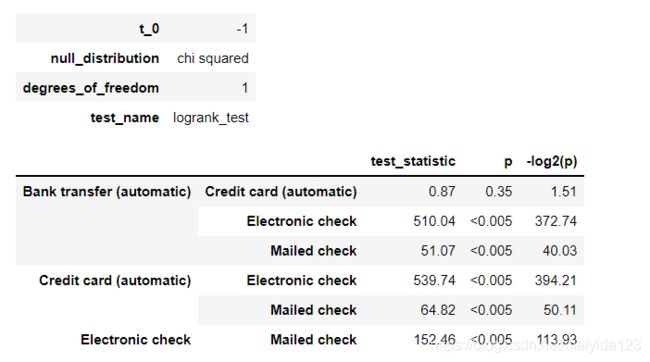
从输出结果可得,Credit card (automatic)与Bank transfer (automatic)的生存曲线没有显著性差异,其与Electronic check、Mailed check均有差异,且后两者之间也存在差异。
5 风险概率
5.1 COX比例风险回归
前文提到的KM曲线之间的对比只能在单一分类变量之间进行,并且KM曲线只描述了该单变量和生存时间之间的关系而忽略了其他变量的影响。为了解决这个问题,Cox比例风险回归模型诞生了。Cox比例风险回归模型通过对风险率进行估计,实现了对包含分类变量及连续变量的多变量回归,并控制了其他变量下,单个变量对生存概率的影响。此外,基于回归的结果可以实现在给定条件下个体生存概率的预测。
Cox比例风险模型公式为:

其中 t 是生存时间,x1, x2 到 xp 指的是具有预测效应的多个变量, b1, b2 到 bp 则是每个变量对应的 effect size 即效应量,可以理解为结果的影响程度。 h(t) 就是不同时间 t 的 hazard,即风险值。
而 h0(t) 是基准风险函数,也就是说在其他协变量 x1, x2, …, xp 都为 0 时,即不起作用时,衡量风险值的函数。 根据公式我们可以看到指数部分是参数模型,因为其参数个数有限,即b1, b2 到 bp,而基准风险函数 h0(t) 由于其未确定性,可根据不同数据来使用不同的分布模型,因此是非参数模型。 所以说, Cox 模型是一种半参数模型。
我们对模型进行解读:当xp为连续型变量时,bp可表示为,在除xp之外其他变量均不变的情况下,xp每增加一个单位,风险率变化exp(bp)倍;当xp为离散型变量时,假设xp有0和1两个分类,则bp可表示为,在除xp之外其他变量均不变的情况下,类别1相对于类别0的风险率是exp(bp)倍。
总体来说,对于影响因子的解读可以分为以下3类。
- 当b> 0时,风险率随着x的增加而增加,我们称之为危险因素。
- 当b< 0时,风险率随着x的增加而减少,我们称之为保护因素。
- 当b= 0时,风险率不随x的变化而变化,我们称之为无关因素。
5.2 变量选择
划分训练集、测试集
train, test = train_test_split(df, test_size=0.2)
定义一个利用AIC进行变量筛选的向前法。
def forward_select(df, E, T):
variate=list(df.columns) # 初始的变量
variate.remove(E)
variate.remove(T)
selected = [] # 用于存放选择的变量
best_score = float('inf') # 初始值,AIC越小越好,所以初始值设置为无限大
n = 1
while True:
scores_with_candidates = []
for candidate in variate:
data = df[selected + [candidate, E, T]].copy()
cph = CoxPHFitter(penalizer=0.01)
score = CoxPHFitter(penalizer=0.01).fit(data, duration_col=T, event_col=E).AIC_partial_
scores_with_candidates.append((abs(score), candidate))
scores_with_candidates.sort() # 从小到大排序
current_best_score, current_best_candidate = scores_with_candidates[0] # 选出最小值
print('round {}\nbest score is {:.4f}, selected candidantes '\
'are {} \n '.format(n, current_best_score, selected + [current_best_candidate]))
n += 1
if current_best_score < best_score :
variate.remove(current_best_candidate)
selected.append(current_best_candidate)
best_score = current_best_score
else:
break
data = df[selected + [E, T]].copy()
return data
cph_train = forward_select(train, 'Churn', 'tenure' )
注:变量选择非必须步骤,此过程仅供参考。我们这次的目的探究哪些协变量影响客户流失,所以选择指定的变量进入模型。
划分数据集
selected_vars = ['tenure', 'MonthlyCharges', 'TotalCharges', 'Churn', 'gender_Female', 'SeniorCitizen_1', 'Partner_Yes',
'Dependents_Yes', 'PhoneService_Yes', 'MultipleLines_Yes','InternetService_DSL','InternetService_Fiber optic',
'OnlineSecurity_Yes', 'OnlineBackup_Yes', 'DeviceProtection_Yes','TechSupport_Yes','StreamingTV_Yes',
'StreamingMovies_Yes','Contract_One year','Contract_Two year', 'PaperlessBilling_Yes', 'PaymentMethod_Credit card (automatic)',
'PaymentMethod_Electronic check', 'PaymentMethod_Mailed check']
cph_train = train[selected_vars]
cph_test = test[selected_vars]
5.3 建模
lifelines中的模型支持网格搜索调参,由于经过简单的调参之后模型效果并没有提升,所以这里就不进行了。有兴趣的朋友可注释代码进行调参。
# %%time
# X = train.drop('tenure', axis=1)
# y = train.tenure
# base_class = sklearn_adapter(CoxPHFitter, event_col='Churn')
# cph = base_class()
# params = {
# "penalizer": 10.0 ** np.arange(-2, 3),
# "l1_ratio": np.linspace(0,1,6),
# }
# clf = GridSearchCV(cph, param_grid=params, cv=5)
# clf.fit(X, y)
# cph = CoxPHFitter(**clf.best_params_)
cph = CoxPHFitter(penalizer = 0.01)
cph.fit(cph_train, duration_col='tenure', event_col='Churn')
cph.print_summary()
输出结果:

关于结果:
- 可以看到模型的拟合效果较为不错,其Concordance Index达到0.92。Concordance Index是AUC的推广,取值范围在[0, 1]之间,0.5为随机预测的结果,越靠近1,预测效果越好。
- 从系数coef可知每个特征是如何“增加”风险的。如果系数是一个正数,那么该特征使客户更有可能流失,如果是负数,那么拥有该特征的客户就不太可能流失。
- exp(coef)即为相对危险度HR 。以合同时长为例,合同共分为月签合同、一年合同(Contract_One year)、两年合同(Contract_Two year)。一年合同的exp(coef)=0.30,即其流失风险为月签合同的0.3倍,95%置信区间为[0.25, 0.37],具有显著性差异(p<0.05);两年合同的exp(coef)=0.07,即其流失风险为月签合同的0.07倍,95%置信区间为[0.05, 0.09],具有显著性差异(p<0.05)。
5.4 PH假定
COX比例风险回归模型的使用具有前提,即其假定Hazard Ratio(HR)不随时间变化,即满足比例风险假定(Proportional Hazards Assumption, PH假定)。
关于需不需要考虑PH假定,通常是不需要考虑的,lifelines的官方文档中给出了一些理由: Do I need to care about the proportional hazard assumption?
- If your goal is survival prediction, then you don’t need to care about proportional hazards. Your goal is to maximize some score, irrelevant of how predictions are generated.
- Given a large enough sample size, even very small violations of proportional hazards will show up.
- There are legitimate reasons to assume that all datasets will violate the proportional hazards assumption. This is detailed well in Stensrud & Hernán’s “Why Test for Proportional Hazards?” [1].
- “Even if the hazards were not proportional, altering the model to fit a set of assumptions fundamentally changes the scientific question. As Tukey said,”Better an approximate answer to the exact question, rather than an exact answer to the approximate question.” If you were to fit the Cox model in the presence of non-proportional hazards, what is the net effect? Slightly less power. In fact, you can recover most of that power with robust standard errors (specify robust=True). In this case the interpretation of the (exponentiated) model coefficient is a time-weighted average of the hazard ratio–I do this every single time.” from AdamO, slightly modified to fit lifelines [2]
考虑到我们的目标是生存预测,具有较好的效果,就不考虑PH假定是否满足。
lifelines中可以使用check_assumptions方法进行ph既定检验,参考代码如下:
cph.check_assumptions(cph_train, p_value_threshold=0.05) # show_plots=True
若考虑ph假定,不满足时可以采用:
-
分层变量,可将不呈比例关系的协变量作为分层变量,然后再将剩余变量进行Cox回归分析;
-
时变协变量,第二种方法是采用时依协变量进行分段Cox回归;
原理及操作详见 Testing the proportional hazard assumptions
5.5 特征重要性分析
我们可以绘制特征coef图来判断特征重要性
fig,ax = plt.subplots(figsize=(12,9))
cph.plot(ax=ax)
plt.show()

从上图可得,能减少客户流失的协变量:
- Contract_Two year 两年合同
- Contract_One year 一年合同
- OnlineSecurity_Yes 在线安全服务
- TechSupport_Yes 技术支持服务
- Partner_Yes 拥有伴侣
- …
加速客户流失的协变量:
- InternetService_Fiber optic 光纤互联网
- InternetService_DSL DSL互联网
- PaymentMethod_Mailed check 邮寄支票
- PaymentMethod_Electronic check 电子支票
- …
那么我们该如何判断连续型协变量对于客户流失的影响呢?
通过plot_partial_effects_on_outcome可查看协变量是如何影响客户生存的。plot_partial_effects_on_outcome生成一个曲线图,将模型的基线曲线与组中的协变量随值变化时发生的情况进行比较,改变协变量时保持所有其他变量不变。基线曲线等于原始数据集中所有平均值的预测y曲线。
以月费为例,探究不同月费与不同合同的关系,及对于客户流失的影响。
单独绘制不同月费的流失情况
fig,ax = plt.subplots(figsize=(12,9))
cph.plot_partial_effects_on_outcome('MonthlyCharges', values=[20, 100], cmap='coolwarm', ax=ax)
plt.show()

上图可得,月费接近100的客户比月费接近20的客户更容易流失,由之前的系数图可得,月签合同的客户比两年合同的客户更容易流失,那么月费100两年合同的客户与月费20月签合同的客户的流失率如何比较呢?
绘制不同月费与不同合同时长的客户流失对比图
fig,ax = plt.subplots(figsize=(12,9))
cph.plot_partial_effects_on_outcome(['MonthlyCharges', 'Contract_One year', 'Contract_Two year'],
values=[[20, 0, 0],
[20, 1, 0],
[20, 0, 1],
[100, 0, 0],
[100, 1, 0],
[100, 0, 1]],
cmap='coolwarm', ax=ax)
plt.show()

由上图可得生存概率从高到低依次为:月费20两年合同、月费20一年合同、月费100两年合同、月费20月签合同、月费100一年合同、月费100月签合同。
5.6 校准
我们的Cox模型拥有92%的一致性,但这在实际中意味着什么呢?它有多精确?
当你从概率的角度看待像流失(或欺诈或盗窃)这样的事件时,检查校准性比检查准确性更重要。校准性是模型获得概率随时间变化的倾向。
就像这样,一个天气预报服务是经过校准的话,如果在所有的时间里它说有40%的可能性下雨,实际上就有40%的可能性下雨。
from lifelines.calibration import survival_probability_calibration
fig,ax = plt.subplots(figsize=(12,9))
survival_probability_calibration(cph, cph_test, t0=40, ax=ax)
ax.grid()

以使用时长t<=40为例,其校准曲线如上图所示,我们的模型你可以看到它非常接近对角线,近似完美的校准。然而,我们的模型似乎在低端低估了风险,中端高估了风险,在高端轻微低估了风险。
为了从数字上了解距离完美校准有多远,我们可以使用brier score来衡量。
brier score公式为:

ft是预测的概率,ot是事件t的实际概率(如果不发生则为0),而N是预测事件数量。
引用维基百科的一个例子说明 Brier分数的计算方式:
假设一个人预测在某一天会下雨的概率P,则Brier分数计算如下:
- 如果预测为100%(P = 1),并且下雨,则Brier Score为0,可达到最佳分数。
- 如果预测为100%(P = 1),但是不下雨,则Brier Score为1,可达到最差分数。
- 如果预测为70%(P = 0.70),并且下雨,则Brier评分为(0.70-1)^2 = 0.09。
- 如果预测为30%(P = 0.30),并且下雨,则Brier评分为(0.30-1)^2 = 0.49。
- 如果预测为50%(P = 0.50),则Brier分数为(0.50-1)^ 2 =(0.50-0)^2 = 0.25,无论是否下雨。
Brier分数对于一组预测值越低,预测校准越好。
代码:
from sklearn.metrics import brier_score_loss
loss_dict = {
}
for i in range(1,73):
score = brier_score_loss(
cph_test.Churn,
1 - np.array(cph.predict_survival_function(cph_test).loc[i]),
pos_label=1 )
loss_dict[i] = [score]
loss_df = pd.DataFrame(loss_dict).T
fig, ax = plt.subplots(figsize=(12,9))
ax.plot(loss_df.index, loss_df)
ax.set(xlabel='Prediction Time', ylabel='Calibration Loss', title='Cox PH Model Calibration Loss / Time')
ax.grid()

可以看到,模型在5-30个月内的预测结果较好。
5.7 剩余价值预测
从数据集中选择未流失的客户
censored_subjects = df.query("Churn == 0")
预测其中位数生存时间,然后计算剩余价值 = 月消费 x(预计生存时长 - 已生存的月数)
predictions_50 = cph.predict_median(censored_subjects)
values = pd.concat([predictions_50, censored_subjects[['MonthlyCharges','tenure']]], axis=1)
values['RemainTenure'] = values[0.5] - values['tenure']
values['RemainingValue'] = values['MonthlyCharges'] * values['RemainTenure']
values.head()

通过计算,我们得到了未流失客户的剩余生存时间与剩余价值,但这样计算会有麻烦的地方:
- MonthlyCharges并不是一成不变的,利用tenure x MonthlyCharges之积与TotalCharges相减,可发现结果有正有负,代表某些客户的月费有变更过,有的增加,有的减少。所以以此获得的剩余价值存在误差。
- 一些客户会在流失之前被预测为流失,所以剩余生存时长与剩余价值带有非正数,参考博客的做法是将其校准,接下来我将使用同样的方法。
- 通常使用中位生存时间来代表客户的预测生存时长,但当客户的生存曲线不超过0.5时,预测的生存时长为无穷大。这部分的客户的剩余价值难以定量。一种做法是将其的剩余生存时长赋值为n个月,24或者48等视情况而定,本文暂不做处理。
- 通过上一小结的校准可知,模型仅在40个月以后的预测效果一般。
关于以上的问题,如有见解,欢迎留言指教,谢谢!
校准
# 预测未流失客户的生存曲线
unconditioned_sf = cph.predict_survival_function(censored_subjects)
# 校准
conditioned_sf = unconditioned_sf.apply(lambda c: (c / c.loc[df.loc[c.name, 'tenure']]).clip(upper=1))
挑选一位客户,将其校准过的生存曲线与未校准的对比
fig, ax = plt.subplots(figsize=(12,9))
subject = 12
unconditioned_sf[subject].plot(ls="--", color="#A60628", label="unconditioned")
conditioned_sf[subject].plot(color="#A60628", label="conditioned on $T>{:.0f}$".format(df.iloc[subject,].tenure))
ax.legend()
ax.grid()

如上图所示,校准过后的12号客户,其生存曲线下降的速度慢于与他相似情况的客户的基线,人为地增加了中位生存时间。
计算剩余生存时长及价值
from lifelines.utils import median_survival_times
predictions_50 = median_survival_times(conditioned_sf)
values = pd.concat([censored_subjects[['tenure','MonthlyCharges']], predictions_50.T], axis=1)
values.rename(columns={
0.5:'baseline'}, inplace=True)
values['RemainTenure'] = values['baseline'] - values['tenure']
values['RemainingValue'] = values['MonthlyCharges'] * values['RemainTenure']
5.8 剩余价值提升
由4.5小结可知哪些协变量对于减缓客户流失有帮助:1-2年合同, 在线安全服务,技术支持服务等。
接下来,如果我们能够说服客户延长合同至1-2年或安装在线安全服务或技术支持服务,探索估算其带来的价值。
# 将之前的校准写成函数
def predict_median_func(censored_subjects):
unconditioned_sf = cph.predict_survival_function(censored_subjects)
conditioned_sf = unconditioned_sf.apply(lambda c: (c / c.loc[df.loc[c.name, 'tenure']]).clip(upper=1))
predictions_50 = median_survival_times(conditioned_sf).T
return predictions_50
# 将月签合同提升至一年合同,若原先是两年合同则维持不变
tmp =df.loc[values.index,].copy()
tmp['Contract_One year'] = tmp.apply(lambda x: 1 if x['Contract_Two year'] == 0 else 0, axis=1)
values['contract_1y_tenure_pred'] = predict_median_func(tmp)
# 将月签合同或者一年合同提升至两年合同
tmp =df.loc[values.index,].copy()
tmp['Contract_Two year'] = 1
tmp['Contract_One year'] = 0
values['contract_2y_tenure_pred'] = predict_median_func(tmp)
# 提升在线安全服务
tmp =df.loc[values.index,].copy()
tmp['OnlineSecurity_Yes'] = 1
values['OnlineSecurity_tenure_pred'] = predict_median_func(tmp)
# 提升技术支持服务
tmp =df.loc[values.index,].copy()
tmp['TechSupport_Yes'] = 1
values['TechSupport_tenure_pred'] = predict_median_func(tmp)
# 计算剩余价值
values['Contract_1y Diff'] = (values['contract_1y_tenure_pred'] - values['baseline']) * values['MonthlyCharges']
values['Contract_2y Diff'] = (values['contract_2y_tenure_pred'] - values['baseline']) * values['MonthlyCharges']
values['OnlineSecurity Diff'] = (values['OnlineSecurity_tenure_pred'] - values['baseline']) * values['MonthlyCharges']
values['TechSupport Diff'] = (values['TechSupport_tenure_pred'] - values['baseline']) * values['MonthlyCharges']
# 预览结果
values.head().T
结果:

以index=0的客户为例,首先查看其基本信息
data.loc[0,]
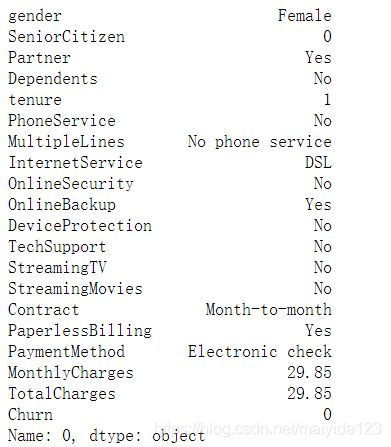
0号客户基本信息:使用了电信服务时长1个月,没有在线安全服务与技术支持服务、月签合同,月费29.85。
预测信息:预测生存时长24个月,剩余生存时长23个月,剩余价值686.55。
提升服务:
- 若使其改签一年合同,预测的生存时长38个月,剩余价值相较于月签合同时增加417.9;
- 若使其改签两年合同,预测的生存时长55个月,剩余价值相较于月签合同时增加925.35;
- 若使其添加在线安全服务,预测的生存时长29个月,剩余价值相较没有该服务时增加149.25;
- 若使其添加在线技术支持服务,预测的生存时长27个月,剩余价值相较没有该服务时增加89.55。
6. 结论
我们分别利用Kaplan-Meier法与COX比例风险回归模型比较了不同特征对于客户流失的影响,并且预测了客户的生存时长,计算了其剩余价值以及潜在可提升的价值,结果具有一定的参考性。
参考:
Churn Prediction and Prevention in Python
生存分析——KM生存曲线、hazard比例、PH假定检验、非比例风险模型(分层/时变/参数模型)(二)
数据科学工程实践:用户行为分析与建模、A/B实验、SQLFlow