python+sklearn进行交叉验证(使用交叉验证对数据划分,模型评估和参数估计,使用决策树举例)
文章目录
- 一、普及
- 二、使用交叉验证法进行数据划分
-
- 分类:
- 三、适用交叉验证进行模型评估
- 四、决策树样例
-
- 1.数据的简单处理
- 2.参数分析
- 3.开始调参
- 4.代码分析
- 五、参考文章
- 六、总结
一、普及
首先普及一下数据评估方法都有哪些:
1.留出法
留出法是将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T,S∩T=空集,在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计。
在采样的过程中,为了保证数据分布的一致性,比如在分类任务中保证类别比例的采样方式叫做“分层采样”。
另外单次的使用留出法得到的结果往往不够稳定可靠,在使用留出法时,一般采用若干次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。
2.自助法(bootstrapping)
以自助采样为基础(从自助采样延申出的Bagging方法,继而可以引出随机森林的采样方法,这里不做详细讲解)。
每次随机从D中挑选一个样本,将其拷贝放入D‘,然后再将该样本放回初始数据集D中,使得样本在下次采样时仍然有可能被采集到,循环执行m遍,就得到了m个样本的数据集D’,这就是自助采样的结果。
3.交叉验证法
通常把交叉验证法叫做K折交叉验证法,其先将数据集D划分为 k个大小相似的互斥子集,即D=D1∪D2∪…∪Dk,Di∩Dj=空集(i≠j),每个自己Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到。
比较常用的是10折交叉验证法,示意图如下:

(鼠标不好画,看懂就好了)
总结:
自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习(随机森林用到)等方法有很大的好处。然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。因此,在初始数据量足够时,留出法和交叉验证法更常用一些
二、使用交叉验证法进行数据划分
提前说一下,这部分提到的函数其实在代码中,只是将其实例化作为一个参数使用。
在这里终于要回归题目,在sklearn中有很多交叉验证的库进行数据的划分,分别是:
KFold,GroupKFold,StratifiedKFold,LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut,ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit(train_test_split,个人理解这个方法和StratifiedShuffleSplit作用是相同的),PredefinedSplit,TimeSeriesSplit。
分类:
从原理上来分类:
- K折交叉验证:
KFold,GroupKFold,StratifiedKFold,RepeatedKFold - 留一法(是k折交叉验证的特列,如果数据有m个样本,那么k当等于m,就是留一法,这样划分之后每一个样本都是一个独立的数据集,这种方法虽然效果被认为很好,但是当数据量很多的时候,比如100万个样本,那么就要训练100万个模型,计算开销很大,no free launch对于实验评估方法仍然适用):
LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut - 随机划分法:
ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit
从应用上来分类
- 对于分类数据来说,它们的target可能分配是不均匀的,比如在医疗数据当中得癌症的人比不得癌症的人少很多,这个时候,使用的数据划分方法有
StratifiedKFold ,StratifiedShuffleSplit - 对于分组数据来说,它的划分方法是不一样的,主要的方法有
GroupKFold,LeaveOneGroupOut,LeavePGroupOut,GroupShuffleSplit - 对于时间关联的数据,方法有
TimeSeriesSplit
在这里我具体说一下StratifiedShuffleSplit,后面实例会用到,其他可以到sklearn官网进行学习:
一共有四个参数
Parameters:
原文如下:
n_splitsint, default=10
Number of re-shuffling & splitting iterations.
test_size, float or int, default=None
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples. If None, the value is set to the complement of the train size. If train_size is also None, it will be set to 0.1.()
train_size, float or int, default=None
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples. If None, the value is automatically set to the complement of the test size.
random_state, int or RandomState instance, default=None
Controls the randomness of the training and testing indices produced. Pass an int for reproducible output across multiple function calls. See Glossary.
解释:
n_splitsint, default=10(重新洗牌和拆分迭代次数,也就是默认会把原数据集D分成10组和进行10折交叉验证)
test_size和train_size就是简单的训练和测试数据集的比例,整数代表具体数量,百分比代表占总数据集的多少比例
random_state 这个值在参数估计很重要,我们需要将其设置为一个大于0的整数,这样对于在不同的参数估计中,可以保证每次k折划分的数据都是相同的;如果设置为0,那么每次进行交叉验证进行数据划分结果是不相同的,这样没办法保证参数评估的准确性)
举例:
>>> import numpy as np
>>> from sklearn.model_selection import StratifiedShuffleSplit
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([0, 0, 0, 1, 1, 1])
>>> sss = StratifiedShuffleSplit(n_splits=5, test_size=0.5, random_state=0)
>>> sss.get_n_splits(X, y)
5
>>> print(sss)
StratifiedShuffleSplit(n_splits=5, random_state=0, ...)
>>> for train_index, test_index in sss.split(X, y):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [5 2 3] TEST: [4 1 0]
TRAIN: [5 1 4] TEST: [0 2 3]
TRAIN: [5 0 2] TEST: [4 3 1]
TRAIN: [4 1 0] TEST: [2 3 5]
TRAIN: [0 5 1] TEST: [3 4 2]
使用这个函数是为了保证每个分类样本中每个类别的占比相同,避免出现某一个类别过多或者过少的情况,train_test_split作用也一样
三、适用交叉验证进行模型评估
列举sklearn中三种模型评估方法:
- cross_val_score
- cross_validate
- cross_val_predict
这里举例说一下cross_val_score函数:
原文:(有点多,可跳过看后面解释)
Parameters:
estimator: estimator object implementing ‘fit’
The object to use to fit the data.
X: array-like of shape (n_samples, n_features)
The data to fit. Can be for example a list, or an array.
y: array-like of shape (n_samples,) or (n_samples, n_outputs), default=None
The target variable to try to predict in the case of supervised learning.
groups: array-like of shape (n_samples,), default=None
Group labels for the samples used while splitting the dataset into train/test set. Only used in conjunction with a “Group” cv instance (e.g., GroupKFold).
scoring: str or callable, default=None
A str (see model evaluation documentation) or a scorer callable object / function with signature scorer(estimator, X, y) which should return only a single value.
Similar to cross_validate but only a single metric is permitted.
If None, the estimator’s default scorer (if available) is used.
cv: int, cross-validation generator or an iterable, default=None
Determines the cross-validation splitting strategy. Possible inputs for cv are:
None, to use the default 5-fold cross validation,
int, to specify the number of folds in a (Stratified)KFold,
CV splitter,
An iterable yielding (train, test) splits as arrays of indices.
For int/None inputs, if the estimator is a classifier and y is either binary or multiclass, StratifiedKFold is used. In all other cases, KFold is used.
Refer User Guide for the various cross-validation strategies that can be used here.
Changed in version 0.22: cv default value if None changed from 3-fold to 5-fold.
n_jobs: int, default=None
The number of CPUs to use to do the computation. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
verbose: int, default=0
The verbosity level.
fit_params: dict, default=None
Parameters to pass to the fit method of the estimator.
pre_dispatch: int or str, default=’2*n_jobs’
Controls the number of jobs that get dispatched during parallel execution. Reducing this number can be useful to avoid an explosion of memory consumption when more jobs get dispatched than CPUs can process. This parameter can be:
None, in which case all the jobs are immediately created and spawned. Use this for lightweight and fast-running jobs, to avoid delays due to on-demand spawning of the jobs
An int, giving the exact number of total jobs that are spawned
A str, giving an expression as a function of n_jobs, as in ‘2*n_jobs’
error_score: ‘raise’ or numeric, default=np.nan
Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised. This parameter does not affect the refit step, which will always raise the error.
在这里!
对于这个函数cross_val_score,其实用到参数不多,大多是默认。
cross_val_score(clf, x, y, cv=cv),大概就是这四个参数,
第一个是机器算法,看要对什么算法进行模型评估,我用的是决策树,后面有代码样例;
第二个参数和第三个参数就是训练和测试数据的list
第四个参数最重要:
确定交叉验证拆分策略。cv的可能输入包括:
- 无,要使用默认的5倍交叉验证
- int,指定(分层)k文件夹中的折叠数
- CV分离器
- 一个可承受的屈服(训练,测试)分裂成一系列的指数(翻译的好像不对,但不影响后续使用)
对于int/None输入,如果估计器是分类器且y是二进制或多类,则使用StratifiedKFold。在所有其他情况下,使用KFold。
最后,本人也是在摸着石头过河,对于第二部分和第三部分本人不敢保证说的很全,或者说没有瑕疵,如果有,欢迎大家评论区指正,这些是在大量查阅资料后总结的,算是综合众多大佬的智慧结晶,可查看最后一部分的参考文章进行加深阅读理解。
或者直接看后续样例代码更容易理解
四、决策树样例
1.数据的简单处理
data = np.genfromtxt(data, delimiter='\t')
x = data[:, 1:]
y = data[:, 0]
x[:, 0], x[:, 1], x[:, 2], x[:, 3], x[:, 4], x[:, 5] = \
x[:, 0] * 0.2, x[:, 1] * 0.2, x[:, 2] * 0.1, x[:, 3] * 0.1, x[:, 4] * 0.2, x[:, 5] * 0.2
主要为数据加了权重(对于决策树不需要标准化)
2.参数分析
在进行参数分析时,就需要知道哪些参数重要,哪些参数不重要。而分类决策树总共有12个参数可以自己调整,这么多参数一个个记起来太麻烦,我们可以把这些参数分成三个类别。
- 用于模型调参的参数:
1)criterion(划分标准):有两个参数 ‘entropy’(熵) 和 ‘gini’(基尼系数)可选,默认为gini。
2)max_depth(树的最大深度):默认为None,此时决策树在建立子树的时候不会限制子树的深度。也可以设置具体的整数,一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
3)min_samples_split(分割内部节点所需的最小样本数):意思就是只要在某个结点里有k个以上的样本,这个节点才需要继续划分,这个参数的默认值为2,也就是说只要有2个以上的样本被划分在一个节点,如果这两个样本还可以细分,这个节点就会继续细分
4)min_samples_leaf(叶子节点上的最小样本数):当你划分给某个叶子节点的样本少于设定的个数时,这个叶子节点会被剪枝,这样可以去除一些明显异常的噪声数据。默认为1,也就是说只有有两个样本类别不一样,就会继续划分。如果是int,那么将min_samples_leaf视为最小数量。如果为float,则min_samples_leaf为分数,ceil(min _ samples _ leaf * n _ samples)为每个节点的最小样本数。 - 用于不平衡样本预处理参数:
class_weight: 这个参数是用于样本不均衡的情况下,给正负样本设置不同权重的参数。默认为None,即不设置权重。具体原理和使用方法见:【机器学习超详细实践攻略(12):三板斧干掉样本不均衡问题之2——通过正负样本的惩罚权重解决样本不均衡】 - 不重要的参数:
这些参数一般无需自己手工设定,只需要知道具体的含义,在遇到特殊情况再有针对性地调节即可。
1)‘max_features’:如果我们训练集的特征数量太多,用这个参数可以限制生成决策树的特征数量的,这个参数在随机森林中有一定的作用,但是因为随机抽取特征,这个算法有概率把数据集中很重要的特征筛选掉,所以就算特征太多,我宁愿采用降维算法、或者计算特征重要度自己手工筛选也不会设置这个参数。
2) ‘min_impurity_decrease’(节点划分最小不纯度): 这是树增长提前结束的阈值,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点 。一般不推荐改动。
3)‘max_leaf_nodes’(最大叶子节点数): 默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立一个在最大叶子节点数内最优的决策树。限制这个值可以防止过拟合,如果特征不多,可以不考虑这个值,但是如果特征多的话,可以加以限制。
4)‘random_state’(随机数种子): 默认为None,这里随便设置一个值,可以保证每次随机抽取样本的方式一样。
5)‘splitter’:用来控制决策树中划分节点的随机性,可选”best"和“random"两个值,默认为“best”。当输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝,输入“random",决策树在分枝时会更加随机,从而降低对训练集的拟合成都。这也是防止过拟合的一种方式。当然,这种防止过拟合的方法属于“伤敌一千自损八百”的方法,树的随机分枝会使得树因为含有更多的不必要信息而更深更大,所以我们最好使用上边的剪枝参数来防止过拟合,这个参数一般不用动。
6)min_weight_fraction_leaf(叶子节点最小的样本权重和):这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们才会稍微注意一下这个值。
7)‘ccp_alpha’(复杂性参数):这个参数同样是是用于避免树的过度拟合。在树生成节点的过程中,加入一个惩罚因子(逻辑回归里的惩罚项),避免生成的树过于冗余,公式如下:
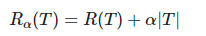
其中T就是树的总节点个数,α \alphaα 就是我们设置的参数,随着树节点的增多,最终损失函数就会变得更大。默认为0,即不加入惩罚项。
以上就是分类决策树12个参数的介绍。
说完了分类决策树,回归决策树就自然而然懂了,它和分类决策树在参数上的区别只有两个地方:
1) ‘criterion’: 评价划分节点质量的参数,类似于分类决策树的熵,有三个参数可选,‘mse’(default)均方误差;'friedman_mse’均方误差近似,最小化L2 loss;'mae’平均绝对误差,最小化L1 loss。
2)少了’class_weight’: None,当然,回归问题也就不存在给每个类别加不同的权重了。
3.开始调参
在知道了哪些是重要的参数,那么就可以开始调参了,分别是:
1)确定criterion参数(决策树划分标准):这里可以简单比较一下。
2)通过绘制得分曲线缩小max_depth(树的最大深度)的搜索范围,得到一个暂定的max_depth。
之所以第一个参数调max_depth,是因为模型得分一般随着max_depth单调递增,之后会区域稳定。
3)利用暂定的max_depth参数,绘制曲线,观察得分随着min_samples_split(分割内部节点所需的最小样本数)的变化规律,从而确定min_samples_split参数的大概范围。
因为随着min_samples_split的增大,模型会倾向于向着简单的方向发展。所以如果模型过拟合,那么随着min_samples_split的增大,模型得分会先升高后下降,我们选取得分最高点附近的min_samples_split参数;如果模型欠拟合,那么随着min_samples_split的增大,模型得分会一直下降,接下来调参时只需要从默认值2开始取就好。
4)利用暂定的max_depth和min_samples_split参数,绘制曲线,观察得分随着min_samples_leaf(叶子节点上应有的最少样例数)的变化规律,从而确定min_samples_leaf参数的大概范围。该参数的范围确定方法同上。
5)利用网格搜索,在一个小范围内联合调max_depth、min_samples_split和min_samples_leaf三个参数,确定最终的参数。
4.代码分析
对《3.开始调参》中步骤一一填写代码
在这里特别强调一下random_state,一定要将其设置为一个大于0的整数,否则参数评估中每次数据都不相同,那就没有评估的意义了!具体多少没有要求
调用所需库:
from sklearn import tree
from sklearn.model_selection import StratifiedShuffleSplit, GridSearchCV, cross_val_score
import matplotlib.pyplot as plt
import numpy as np
1)确定criterion参数(决策树划分标准):这里可以简单比较一下。
cv = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=42)
clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=42)
score = cross_val_score(clf, x, y, cv=cv).mean()
print(score)
clf = tree.DecisionTreeClassifier(criterion='gini', random_state=42)
score = cross_val_score(clf, x, y, cv=cv).mean()
print(score)
0.764375
0.7543749999999999
有的说gini效果好一点,但我数据跑出来entropy效果更好一点
2)通过绘制得分曲线缩小max_depth(树的最大深度)的搜索范围,得到一个暂定的max_depth。
之所以第一个参数调max_depth,是因为模型得分一般随着max_depth单调递增,之后会区域稳定。
ScoreAll = []
cv = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=42)
for i in range(5, 100, 5):
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=i, random_state=42)
score = cross_val_score(clf, x, y, cv=cv).mean()
ScoreAll.append([i, score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll == np.max(ScoreAll[:, 1]))[0][0] # 找出最高得分对应的索引
print("最优参数以及最高得分:", ScoreAll[max_score])
plt.figure(figsize=[20, 5])
plt.plot(ScoreAll[:, 0], ScoreAll[:, 1])
plt.show()
输出:
最优参数以及最高得分: 最优参数以及最高得分: [10. 0.78375]
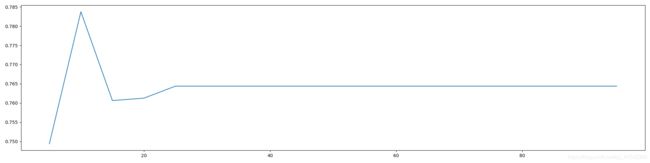
不要忘记,我们还需要在10左右进行具体的分析
ScoreAll = []
cv = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=42)
for i in range(5, 15):
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=i, random_state=42)
score = cross_val_score(clf, x, y, cv=cv).mean()
ScoreAll.append([i, score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll == np.max(ScoreAll[:, 1]))[0][0] # 找出最高得分对应的索引
print("最优参数以及最高得分:", ScoreAll[max_score])
plt.figure(figsize=[20, 5])
plt.plot(ScoreAll[:, 0], ScoreAll[:, 1])
plt.show()
输出:
最优参数以及最高得分: [7. 0.791875]
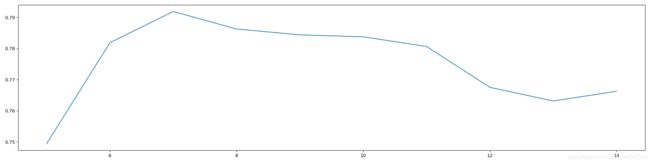
我们暂定树的高度为7,达到了0.791875
3)利用暂定的max_depth参数,绘制曲线,观察得分随着min_samples_split(分割内部节点所需的最小样本数)的变化规律,从而确定min_samples_split参数的大概范围。
ScoreAll = []
cv = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=42)
for i in range(5, 15):
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=9, min_samples_split=i, random_state=42)
score = cross_val_score(clf, x, y, cv=cv).mean()
ScoreAll.append([i, score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll == np.max(ScoreAll[:, 1]))[0][0] # 找出最高得分对应的索引
print("最优参数以及最高得分:", ScoreAll[max_score])
plt.figure(figsize=[20, 5])
plt.plot(ScoreAll[:, 0], ScoreAll[:, 1])
plt.show()
输出:
最优参数以及最高得分: [5. 0.79375]

确定min_samples_split为5
4)利用暂定的max_depth和min_samples_split参数,绘制曲线,观察得分随着min_samples_leaf(叶子节点上应有的最少样例数)的变化规律,从而确定min_samples_leaf参数的大概范围。该参数的范围确定方法同上。
ScoreAll = []
cv = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=42)
for i in range(5, 15):
clf = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=i, max_depth=7, min_samples_split=5, random_state=42)
score = cross_val_score(clf, x, y, cv=cv).mean()
ScoreAll.append([i, score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll == np.max(ScoreAll[:, 1]))[0][0] # 找出最高得分对应的索引
print("最优参数以及最高得分:", ScoreAll[max_score])
plt.figure(figsize=[20, 5])
plt.plot(ScoreAll[:, 0], ScoreAll[:, 1])
plt.show()
输出:
最优参数以及最高得分: [2. 0.795]

5)利用网格搜索,在一个小范围内联合调max_depth、min_samples_split和min_samples_leaf三个参数,确定最终的参数。
cv = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=42)
param_grid = {
'max_depth': np.arange(2, 10),
'min_samples_leaf': np.arange(1, 8),
'min_samples_split': np.arange(2, 10)}
clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=42)
GS = GridSearchCV(clf, param_grid, cv=cv)
GS.fit(x, y)
print(GS.best_params_)
print(GS.best_score_)
输出:
{
'max_depth': 9, 'min_samples_leaf': 7, 'min_samples_split': 2}
0.796875
可以看到,最终模型提高到了0.796875。这里我们可以看到,上述三个参数和我们前边所暂定的参数都不一样。证明三者之间确实是相互影响的!
GridSearchCV():穷尽的网格搜索
RandomizedSearchCV():随机参数的优化
我这里使用了网格搜索,想尝试的可以试试RandomizedSearchCV()
五、参考文章
- https://www.cnblogs.com/nolonely/p/7007432.html
- https://blog.csdn.net/qq_30815237/article/details/87904205
- https://www.cnblogs.com/jiaxin359/p/8552800.html#_label3_5
- https://blog.csdn.net/u013044310/article/details/103996047
- https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedShuffleSplit.html?highlight=stratifiedshufflesplit#sklearn.model_selection.StratifiedShuffleSplit
- 周志华的《机器学习》,俗称的书
- https://blog.csdn.net/robin_pi/article/details/103971343(强推,巨详细)
六、总结
- 最后的最后,再多说几句,整篇文章,其实概括就是
1.选数据划分算法,我是使用了交叉验证中的一个算法
2.对某个机器学习算法中影响较大的参数进行参数估计和模型评估,通过不同的参数选择,使用交叉验证进行模型评估,从而选出最优的参数 - 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,与其找出最优的模型和算法,不如对数据和特征进行严格的处理,我这里的决策时模型,最终达到了0.796875的精度,没能拿下0.8的高分,这和我数据的提取有关系;当然提升模型和算法也是一种思路,说不定决策树的上限就那了,换个模型和算法又会有更好的表现,说不定我的数据上限更高呢,哈哈哈哈哈,这就是后话了,还得进行稍后的实验证明才可以。
- 调参的目标(以随机森林为例):
调参的目标就是为了达到整体模型的偏差和方差的大和谐!进一步,这些参数又可分为两类:过程影响类及子模型影响类。在子模型不变的前提下,某些参数可以通过改变训练的过程,从而影响模型的性能,诸如:“子模型数”(n_estimators)、“学习率”(learning_rate)等。另外,我们还可以通过改变子模型性能来影响整体模型的性能,诸如:“最大树深度”(max_depth)、“分裂条件”(criterion)等。正由于bagging的训练过程旨在降低方差,而boosting的训练过程旨在降低偏差,过程影响类的参数能够引起整体模型性能的大幅度变化。一般来说,在此前提下,我们继续微调子模型影响类的参数,从而进一步提高模型的性能。
疑问:
那么从这段话可以分析:随机森林基于bagging方法做了小改动,AdaBoost基于boosting方法,而随机森林和AdaBoost都算是集成类算法,都是在决策树为基学习器,一个降低偏差,一个减低方差,而且随机森林会降低决策树过拟合的风险,那么是否可以认为这两个方法都会比决策树有更好的训练结果呢?日后解决。
2020/12/6补充
随机森林