通用爬虫模块使用(上)
一:爬虫的流程
爬虫的分类
爬虫分为两种:通用爬虫和聚焦爬虫
- 通用爬虫:通常指搜索引擎的爬虫
- 聚焦爬虫:针对特定网站的爬虫
两种爬虫的工作流程

二:HTTP与HTTPS
URL的形式:

HTTP请求形式:
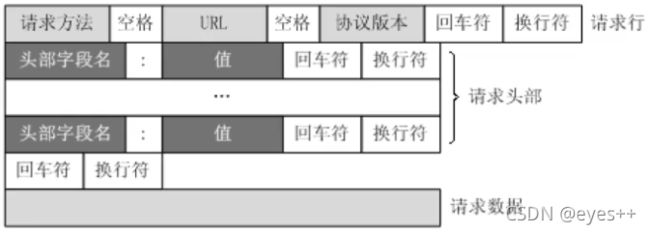
HTTP常用请求头:

有关HTTP与HTTPS的详情可以看看我的另一篇博客,这里就不赘述了。HTTP详解
三:requests库发送请求和获取网页的字符串
打开命令行工具–>进入python环境–>导入requests包–>请求网站数据–>打印返回结果类型
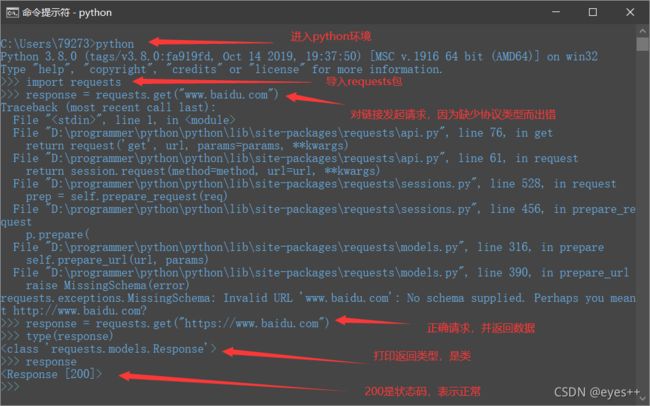
response有很多属性操作
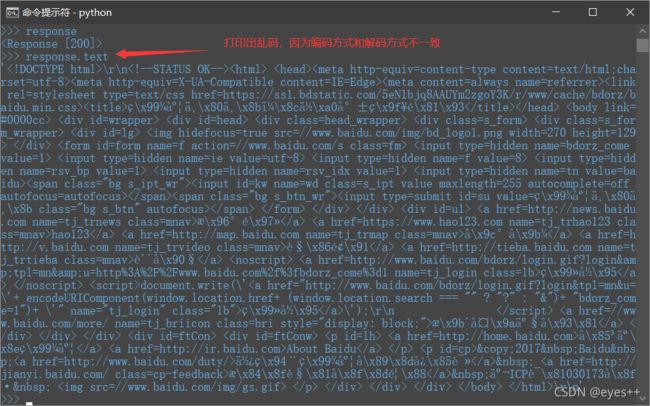
- response.text,可以打印出响应的内容,
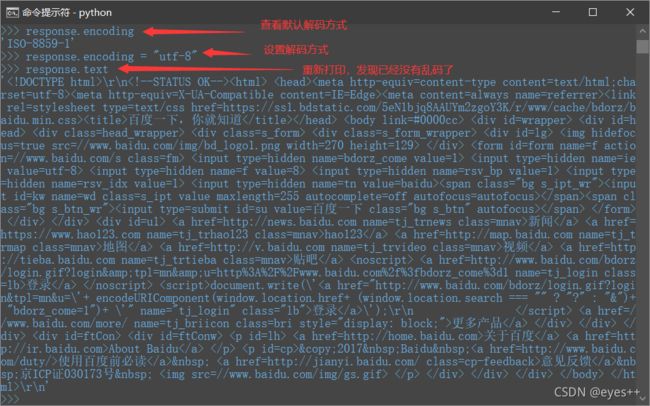
- response.encoding,查看默认解码方式,默认解码方式是根据HTTP头部对响应的编码做出有根据的推测的方式,不过可能会推测错误。
- response.encoding = “utf-8”,设置解码方式
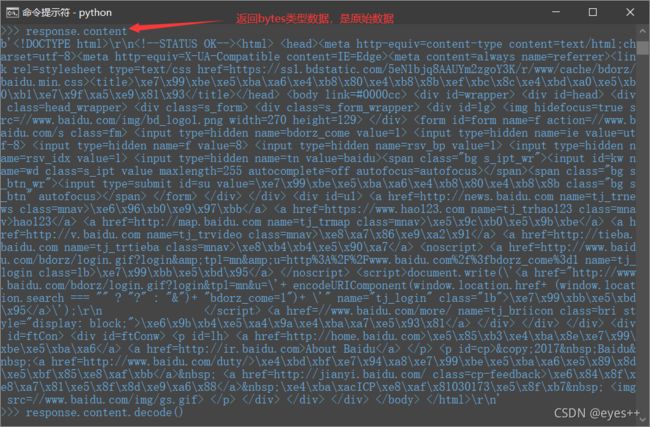
- response.content,返回bytes类型数据
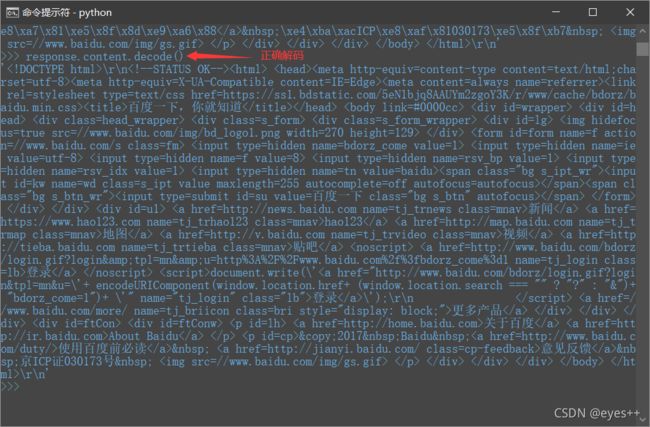
- response.content.decode(),解码bytes数据
- response.content.decode(“gbk”),可以设置解码方式
更推荐使用response.content.decode()方式获取响应的html页面
四:使用requests保存图片
代码如下:
# coding=utf-8
import requests
# 发送请求
response = requests.get("https://docs.python-requests.org/zh_CN/latest/_static/requests-sidebar.png")
# 保存
with open("a.png", "wb") as f:
f.write(response.content)
效果如下:
五:requests发送带headers的请求
response = requests.get(url),其中response的常用方法如下:
- response.text
- response.content
- response.status_code
- response.request.*
- response.url
- response.headers
一些用法:
import requests
response = requests.get("https://www.baidu.com")
print("响应状态码:", response.status_code)
print("响应头:", response.headers)
print("请求:", response.request)
print("请求的地址:", response.request.url) # 如果被网站重定向了,则请求的地址与响应的地址会不同
print("响应的地址:", response.url)
print("请求头:", response.request.headers)
print("请求体:", response.request.body)
print("请求钩子:", response.request.hooks)
print("请求方式:", response.request.method)
结果:
为了正确爬取数据,需要在请求时带上header,模拟浏览器,欺骗服务器,获取和浏览器一致的内容。之前使用response.content.decode()只能获取少量数据,具体可以见前面的测试,但设置请求头模拟浏览器后可以获得大量数据,就像浏览器访问一样。

import requests
# 获取请求头,一般而言带上User-Agent就可以了,如果不行,则可以尝试Accept,Host,Cookie之类的
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}
# 请求头在第二个参数
response = requests.get("https://www.baidu.com", headers=headers)
print(response.content.decode())
六:requests发送带参数的请求
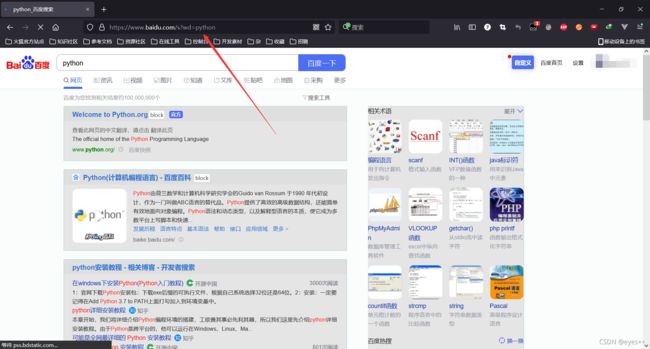
一般的请求都是带参数的,如下百度搜索:

整条链接如下,?号后面,&连接且A=B形式的都是参数:
https://www.baidu.com/s?wd=python&rsv_spt=1&rsv_iqid=0xc6f3adb20001c17d&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=&tn=baiduhome_pg&ch=&rsv_enter=1&rsv_btype=i&rsv_dl=ib&inputT=6532
但不是所有参数都是必须的,经过尝试发现,只有wd=python是必须的,即传入的搜索的参数。
那么现在就可以尝试让请求带参数了:
- 参数形式:字典
- p={‘wd’=‘python’}
- 用法:requests.get(url,params=p)
import requests
# 请求地址
url = "https://www.baidu.com/s?"
# 获取请求头,一般而言带上User-Agent就可以了,如果不行,则可以尝试Accept,Host,Cookie之类的
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}
# 携带参数
p = {
'wd':'python'}
# 发请求
response = requests.get(url, headers=headers, params=p)
print(response.content.decode())
七:贴吧爬虫
这里我爬取的是百度贴吧里的原神吧,代码如下:
# coding=utf-8
import requests
class Tieba:
def __init__(self, name):
self.tieba_name=name
self.url_temp = "https://tieba.baidu.com/f?kw=" + name + "&ie=utf-8pn={}"
self.headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}
def get_url_list(self): # 构造url列表
url_list = []
for i in range(1000):
url_list.append(self.url_temp.format(i + 50))
return url_list
def parse_url(self, url): # 发送请求,获取响应
response = requests.get(url, headers=self.headers)
return response.content.decode()
def save_html(self, html_str, page_num): # 保存html字符串
file_path = "page/{}--第{}页.html".format(self.tieba_name, page_num)
with open(file_path, "w", encoding="utf-8") as f:
f.write(html_str)
print("成功爬取:", file_path)
def run(self): # 实现主要逻辑
# 1.构造url列表
url_list = self.get_url_list()
# 2.遍历,发送请求,获取响应
for url in url_list:
html_str = self.parse_url(url)
# 3.保存
page_num = url_list.index(url) + 1
self.save_html(html_str, page_num)
if __name__ == '__main__':
tieba = Tieba("原神")
tieba.run()
有兴趣了解更多相关知识的话可以前往我的个人网站看看:eyes++的个人空间