通用爬虫模块使用(中)
一:requests发送POST请求
哪些时候我们会用到POST请求:
- 登陆注册(POST比GET更安全)
- 传输大文本内容(POST请求对数据长度没要求,GET有)
POST请求用法:
response = requests.post("https://www.baidu.com/", data=data, headers=headers)
以下是百度的示例:
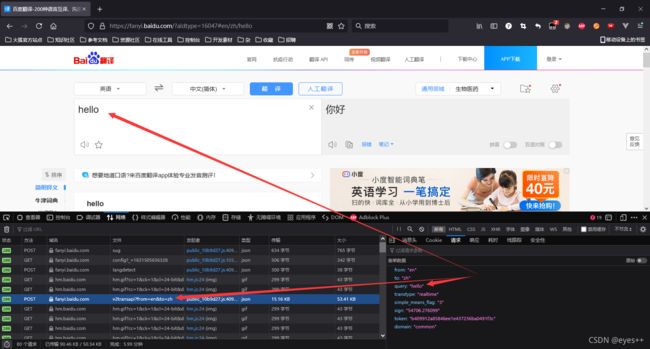
 获取到接口地址和参数后我们就可以用python发请求了:
获取到接口地址和参数后我们就可以用python发请求了:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0"}
data = {
"from": "zh",
"to": "en",
"query": "人生苦短,我用python",
"transtype": "realtime",
"simple_means_flag": "3",
"sign": "289133.35420",
"token": "b409912a85846ee1e437236ba0491f3c",
"domain": "common"
}
post_url = "https://fanyi.baidu.com/v2transapi"
r = requests.post(post_url, data=data, headers=headers)
print(r.content.decode())
运行结果如下:
很明显出了错,通过多次抓取翻译请求,发现携带的参数中sign是变化的,token是不变的,通过代码查找发现token是固定的:
 而没有找到sign,因此暂时无法找到sign的生成算法,这个接口应该是用不了了。。。。。。无所谓,反正这也不是写如何调用百度翻译接口的博客。。。。。
而没有找到sign,因此暂时无法找到sign的生成算法,这个接口应该是用不了了。。。。。。无所谓,反正这也不是写如何调用百度翻译接口的博客。。。。。
二:requests使用代理
代理引用知乎上的解释就是:代理就是用服务器(其他人的电脑)帮你访问要访问的网页。和召唤美团快递小哥一个道理。餐厅老板和你,你们俩谁都没见过谁。在这个过程中,只有快递小哥知道你家地址,老板并不知道,(不好吃就给个差评,老板也找不到你)是不是很安全。
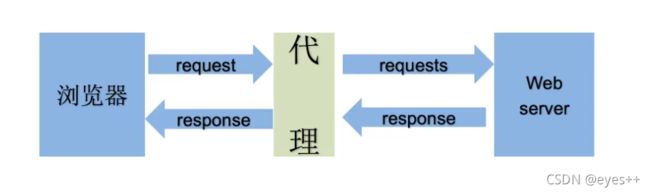 而代理分为正向代理和反向代理:
而代理分为正向代理和反向代理:
代理服务器(Proxy Serve):提供代理服务的电脑系统或其它类型的网络终端,代替网络用户去取得网络信息。
使用代理服务器的好处:
- 提高访问速度:由于目标主机返回的数据会存放在代理服务器的硬盘中,因此下一次客户再访问相同的站点数据时,会直接从代理服务器的硬盘中读取,起到了缓存的作用,尤其对于热门网站能明显提高访问速度。
- 防火墙作用:由于所有的客户机请求都必须通过代理服务器访问远程站点,因此可以在代理服务器上设限,过滤掉某些不安全信息。同时正向代理中上网者可以隐藏自己的IP,免受攻击。
- 突破访问限制:互联网上有许多开发的代理服务器,客户机在访问受限时,可通过不受限的代理服务器访问目标站点,通俗说,我们使用的浏览器就是利用了代理服务器,可以直接访问外网。
正向代理: 正向代理(forward proxy) ,一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并制定目标(原始服务器),然后代理向原始服务器转发请求并将获得的内容返回给客户端,客户端才能使用正向代理。我们平时说的代理就是指正向代理。
反向代理: 反向代理(Reverse Proxy),以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求的客户端,此时代理服务器对外表现为一个反向代理服务器。
为什么爬虫需要使用代理:爬虫可能会频繁请求服务器数据,使用代理可以让服务器以为不是同一个客户端在请求,防止我们的真实地址被泄露,防止被追究。
使用代理:
用法:requests.get(URL, proxies=proxies)
proxies的形式:字典
例如:
proxies = {
"http": "http://12.34.56.78.8000",
"https": "https://12.34.56.78.8000"
}
对于代理地址,国内有很多公司会提供免费代理ip,大家可以自行百度搜索。
一次简单的代理使用:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0"}
proxies = {
"https": "https://47.98.183.59:3128"}
r = requests.get("https://www.runoob.com", proxies=proxies, headers=headers)
print(r.status_code)
我使用的时候编译器报错了:
 百度之后发现是因为我的requests库版本太高,解决方法就是降低requests模块的版本或者是降低urllib3的版本,我采用的是降低urllib3的版本:(注意安装模块前,要关闭)fiddler抓包工具。我是直接在pycharm中进行修改的,也可以使用 pip install 指定版本进行安装:
百度之后发现是因为我的requests库版本太高,解决方法就是降低requests模块的版本或者是降低urllib3的版本,我采用的是降低urllib3的版本:(注意安装模块前,要关闭)fiddler抓包工具。我是直接在pycharm中进行修改的,也可以使用 pip install 指定版本进行安装:
pip install urllib3==1.25.8
 然后就成功了:
然后就成功了:
使用代理需要注意的事项:
- 为了防止同一ip多次请求服务器导致被封ip,一般爬虫需要大量代理ip形成ip池,每次请求时随即调用其中的某个
- 使用ip池的时候,需要对每个ip先进行判断是否有效,然后再去使用它进行代理请求,判断是否有效可以判断返回的状态码,并且注意请求方式是http还是https
三:requests携带cookie
使用爬虫的时候有时候需要带上cookie或session。带上cookie、session的好处就是能够请求到登录之后的页面,但是也有弊端,一套cookie和session往往与一个用户对应,请求太快,请求次数太多都容易被服务器识别为爬虫,所以不需要cookie的时候尽量不使用cookie,怕被封号。当然也可以注册一堆账号,这样就有一堆cookie了,cookie池的使用方式跟ip池一样。
requests提供了一个session类来实现客户端和服务端的会话保持。
使用方法:
- 实例化一个session对象
- 让session发送get或者post请求
如:
session = request.session() # 先使用session发送一次请求,这样就有cookie了
response = session.get(url, headers) # 带上之前的cookie请求数据
以下代码只是个session使用示例,现在大多数的网站都会加密密码再发送给后端,所以模拟登录很麻烦:
import requests
url = "https://xxxxxx.com"
data = {
"email": "[email protected]",
"password": "123456789"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
# 实例化一个session对象
session = requests.session()
# 使用session发送post请求,cookie保存在其中
session.post(url, data=data, headers=headers)
# 在使用session进行请求登录之后才能访问的地址
r = session.get("http://xxxxxx.com/home", headers=headers)
# 保存页面
with open("xxxxxx.html", "w", encoding="utf-8") as f:
f.write(r.content.decode())
如果有兴趣了解更多相关内容的话,可以来我的个人网站看看:eyes++的个人空间