【源码讲解】Redis中内存优化的数据结构是如何设计的
文章目录
- 优化的数据结构
-
- SDS 设计
-
- redisObject 结构体
- 嵌入式字符串
- ziplist 设计
- intset 设计
- 共享对象
Redis 作为内存数据库,如何高效地使用内存非常重要。为了提升内存的使用率,主要采取数据结构优化设计及使用以及内存数据按照规则淘汰。内存数据按照淘汰规则主要通过 Redis 的内存替换策略实现的,也就是将很少使用的内存数据淘汰,这样就可以更好地把内存空间给频繁使用的数据使用。
下面,我们就通过源码讲解下 Redis 中内存友好的数据结构是如何设计的以及Redis 如何优化内存使用的。
优化的数据结构
在 Redis 中,有三种数据结构针对内存使用率做了设计上的优化。分别是动态字符串(SDS)、压缩列表(ziplist)和整数集合(intset)。下面我们来学习下。
SDS 设计
字符串在平常应用开发中使用的非常频繁,对于 Redis 来说,键值中的键是字符串,值有时也是字符串。而且客户端和服务器之间交互的命令和数据也是字符串表示的。既然字符串的使用那么广泛和关键,在实现字符串时,应该满足以下条件:
- 支持丰富的字符串操作(比如追加、删除、比较、获取长度等操作)
- 能保存任意的二进制数据
- 可以节省内存开销
在 C 语言中经常使用 char* 字符数组来实现字符串。同时,C 语言标准库 string.h 也定义了字符串操作函数。比如获取字符串长度的 strlen 等,从而方便使用者操作字符串。这样感觉是可以复用 C 语言的字符串操作的实现了,但是 C 语言中需要频繁手动检查和分配字符串的内存空间,从而增加了代码开发工作量。而且很多二进制数据还无法用字符串保存,也限制了使用范围。
Redis 从系统设计角度上来说,设计 SDS(Simple Dynamic String)结构,用来表示字符串。同 C 语言的字符串比较,它会提升字符串的操作效率,并且可以保存二进制数据。这部分内容我会在之后的文章中讲解。为了避免内存浪费,SDS 设计了 不同类型的结构头,主要包括 sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。它们可以适配不同大小的字符串。
SDS 除了使用设计精巧的结构头外,在保存较小字符串时,其实还用了嵌入式字符串。这样避免了给字符串分配额外的空间,可以让字符串直接保存在 Redis 的基本数据对象结构中。
所以,接下来我们赶紧来理解下,Redis 使用的基本数据对象结构体 redisObject 是啥样的?
redisObject 结构体
redisObject 是定义在 server.h 文件中的,其主要功能是保存键值对中的值,这个结构一共定义了 4 个元数据和一个指针。
typedef struct redisObject {
//redisObject 数据类型,4bits
unsigned type:4;
//redisObject 的编码类型,4bits
unsigned encoding:4;
//redisObject 的 LRU 时间,LRU_BITS 占用 24 个 bits
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
//redisObject 的引用技术
int refcount;
//指向值的指针
void *ptr;
} robj;
从 redisObject 结构体定义中我们可以看到,在 type、encoding、lru 这三个变量后面都跟着一个冒号,冒号后紧跟着一个数值表示该元数据占用的比特数。其中 type 和 encoding 占用 4 比特,而 lru 占用的比特数是有 server.h 中的宏定义的,默认是 24 比特。
#define LRU_BITS 24
在这里变量后使用冒号和数值的定义方法,实际上是 C 语言的位域定义方法,这种方法可以节省内存开销。当一个变量占用不了一个数据类型的所有 bits 时就采用位域的方法,把一个数据类型中的 bits 划分为多个位域。每个位域占用一定的比特数,这样一个数据类型的所有 bits 可以定义多个变量节省了内存开销。对于 type、encoding、lru 都是 unsigned 的,unsigned 本身 4 个字节,使用位域的方法后节省了 8 个字节。下面我们再继续了解下嵌入式字符串是如何实现的。
嵌入式字符串
SDS 在保存较小的字符串时,会使用嵌入式字符串。直接将字符串保存在结构体 redisObject 中。redisObject 结构中的指针 ptr 指向值的数据结构。比如创建一个 String 类型的值,Redis 会调用 createStringObject 函数来创建对应的 redisObject、redisObject 结构中的 ptr 指针就会指向 SDS 结构。createStringObject 函数中会根据字符串长度来选择调用哪个函数,源码如下:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
//创建嵌入式字符串,长度小于 44 字节
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
//创建普通字符串,长度大于 44 字节
else
return createRawStringObject(ptr,len);
}
对于 createRawStringObject 函数来说,它在创建 String 类型的值时调用 createObject 函数。createObject 函数主要用来创建 Redis 的数据对象的,Redis 中数据对象类型比较多。(比如 String、List、Hash 等),因此 createObject 函数包含两个参数,第一个是用来表示索要创建的数据对象类型,第二个参数是指向数据对象的指针。来看下 createRawStringObject 源码看看是如何调用 createObject 函数的。
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
可以看到在调用 createObject 函数时,会调用 OBJ_STRING 类型,它表示要创建 String 类型的对象。指向 SDS 结构的指针都是由 sdsnewlen 函数返回的,而 sdsnewlen 函数正式用来创建 SDS 结构的。
sds sdsnewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 0);
}
接下来,我们继续看看 createObject 函数的源码:
robj *createObject(int type, void *ptr) {
//为 redisObject 分配内存空间
robj *o = zmalloc(sizeof(*o));
//指定 redisObject 的类型
o->type = type;
//指定 redisObject 的编码类型,这里表示普通的 SDS
o->encoding = OBJ_ENCODING_RAW;
//指针直接传入给 ptr 成员
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
也就是说创建普通的 SDS 时,需要给 redisObject 和 SDS 分配内存,这样就会遭成极大的内存分配开销和内存碎片。所以当 SDS 小于和等于 44 字节时,Redis 创建嵌入式字符串来减少不必要的内存分配开销和内存碎片。要创建嵌入式字符串就得调用 createEmbeddedStringObject 函数。我们来看下这个函数的源码:
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
//sh 指向 SDS 结构头起始位置
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
//移动 ptr 指针到结构头末尾,字符数组起始位置
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
//ptr 指向的字符串拷贝到 SDS 的字符数组中
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
在代码中可以看到首先分配了一块连续的内存区域,该区域包含 redisObject 大小、SDS 结构头 sdshdr8 大小以及字符串大小总和。最后加 1 表示加上了字符串结束符 \0。内存分配完后,则创建 SDS 结构头指针 sh,sh 指向这块连续内存区域 SDS 结构头所在的位置。o+1 表示从内存区域开始位置移动了 redisObject 大小的位置。接着 redisObject 中 ptr 指针将指向 SDS 的字符数组。其中 sh 就是刚才说的 SDS 结构头指针,指向 sdshdr8 类型。sh+1 表示把地址从 sh 开始移动 sdshdr8 大小的距离,这时候 ptr 指针指向了 SDS 结构头的末尾,字符数组的起始位置处。最后把 ptr 指向的字符串拷贝给到结构 SDS 中的字符数组,并在数组尾部添加结束符 \0。
通过代码实现看到 Redis 把 redisObject 和 SDS 一起放在了一块连续的内存空间中,对于大小不超过 44 字节的字符串来说不容易遭成内存分配开销和内存碎片。除了嵌入式字符串设计外,Redis 还设计了压缩列表(ziplist)和整数集合(intset)这两种类似的数据结构。
ziplist 设计
在 Redis 中,List、Hash 以及 Sorted Set 都可以用压缩列表(ziplist)来保存。下面我们首先通过它的创建函数来看下如何实现的,源代码如下:
unsigned char *ziplistNew(void) {
//初始分配的大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
这个代码首先分配一块大小为 ZIPLIST_HEADER_SIZE 和 ZIPLIST_END_SIZE 总和的内存区域,然后最后一个字节用 ZIP_END 来赋值表示列表结束。那么宏 ZIPLIST_HEADER_SIZE 和 ZIPLIST_END_SIZE 又是多少呢?我们来看下:
//ziplist 的列表头大小,分别表示压缩列表总共的字节数,最后一个元素离头部的偏移、列表元素个数
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
//ziplist 的列表尾大小,表示列表结束
/* Size of the "end of ziplist" entry. Just one byte. */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
所以在创建一个空的压缩列表的时候,其内存布局如下:
| 32bit | 32bit | 16bit | 8bit |
|---|---|---|---|
| ziplist 总字节数 | 最后一个元素离头部的偏移 | ziplist 包含的元素个数 | 255 |
当我们往压缩列表插入数据的时候,ziplist 会根据不同的数据类型(字符串、整数)以及它们的大小来进行编码。这种方式起到了节省内存的作用。下面我们就来看看它们是如何编码的。
要了解 ziplist 是如何编码的,我们得首先来了解 ziplist 的 entry,它主要包含前一项的长度(prevlen),当前项长度的编码(encoding),以及当前项的实际数据(data)。
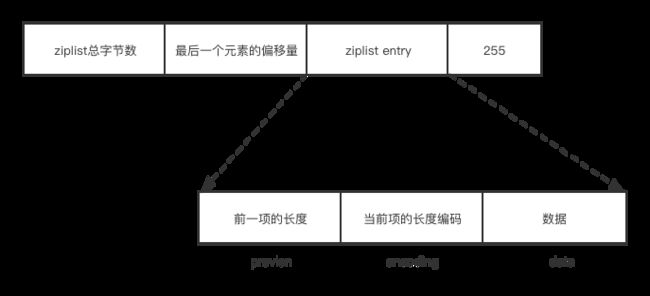
这里的编码指的是用不同数量的字节来表示保存的信息,ziplist 中包含多个列表项,每个列表项都是紧挨着的。为了方便查找每个列表项都会包含前一项的长度,因为每个列表长度不一样,如果都统一使用相同大小来记录 prevlen 将遭成内存空间浪费。比如,某个列表项只是一个字符串“hello”,包含 5 个字节,1 个字节可以表达 256 字节的字符串,此时 prevlen 有 3 个字节是被浪费掉的。Redis 在对 prevlen 进行编码时就先调用 zipStorePrevEntryLength 函数。函数源码如下:
unsigned int zipStorePrevEntryLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIG_PREVLEN) ? 1 : sizeof(uint32_t) + 1;
} else {
//如果 len 小于 254 字节,那么返回 prevlen 为 1 个字节
if (len < ZIP_BIG_PREVLEN) {
p[0] = len;
return 1;
} else {
return zipStorePrevEntryLengthLarge(p,len);
}
}
}
该函数中用于判断一个列表项是否小于 254 字节,如果小于 254 字节 prevlen 就用 1 个字节表示,否则就用 zipStorePrevEntryLengthLarge 函数进一步编码, zipStorePrevEntryLengthLarge 函数源码如下:
int zipStorePrevEntryLengthLarge(unsigned char *p, unsigned int len) {
uint32_t u32;
if (p != NULL) {
// 将 prevlen 的第一个字节设置为 ZIP_BIG_PREVLEN
p[0] = ZIP_BIG_PREVLEN;
u32 = len;
// 将前一个列表项的长度值拷贝到第 2 到第 5 个字节
memcpy(p+1,&u32,sizeof(u32));
memrev32ifbe(p+1);
}
// 返回 prevlen 的大小
return 1 + sizeof(uint32_t);
}
会先将 prevlen 第一个字节设置成 ZIP_BIG_PREVLEN,这个宏的值就是 254,然后使用 memcpy 将前一个列表项的长度拷贝到第 2 到第 5 个字节。所以 prevlen 有 1 字节和 5 字节两种方式编码。这种方式其实是根据不同长度的数据,使用不同大小的元数据信息。
intset 设计
整数集合(intset)是数据类型集合 Set 的底层实现。和嵌入式字符串和 ziplist 类似,整数集合也是用了一块连续的内存空间,下面我们来看看整数集合的定义。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
其中数据部分就是一个 int8_t 的整形数组 contents,一般来说整形数组是作为一块连续的内存空间的。所以这样也同样避免了内存碎片从而提高了内存使用率。除此以外,为了节省内存开销,Redis 在内存访问上还采取了共享对象的方式。
共享对象
Redis 的实例运行时,会遇到有些经常访问的数据,比如常见的整数或者 Redis 的回复信息 OK、ERR,以及报错信息。因此,为了避免反复创建经常访问的数据,Redis 采用了共享对象的方式,就是把常用数据创建为共享对象,上层应用访问时只需要直接读取。比如现在有 2000 个用户同时保存”40“这个对象,如果 Redis 为每一个用户都为 40 创建 redisObject 将遭成内存大量的浪费,采用共享对象的方式内存中只保存一个 40 的 redisObject,节省了内存空间。创建共享对象需要使用 server.c 中的 createSharedObjects 函数。该函数定义如下:
void createSharedObjects(void) {
int j;
/* 常见的回复信息 */
shared.crlf = createObject(OBJ_STRING,sdsnew("\r\n"));
shared.ok = createObject(OBJ_STRING,sdsnew("+OK\r\n"));
shared.emptybulk = createObject(OBJ_STRING,sdsnew("$0\r\n\r\n"));
shared.czero = createObject(OBJ_STRING,sdsnew(":0\r\n"));
shared.cone = createObject(OBJ_STRING,sdsnew(":1\r\n"));
shared.emptyarray = createObject(OBJ_STRING,sdsnew("*0\r\n"));
shared.pong = createObject(OBJ_STRING,sdsnew("+PONG\r\n"));
shared.queued = createObject(OBJ_STRING,sdsnew("+QUEUED\r\n"));
shared.emptyscan = createObject(OBJ_STRING,sdsnew("*2\r\n$1\r\n0\r\n*0\r\n"));
shared.space = createObject(OBJ_STRING,sdsnew(" "));
shared.colon = createObject(OBJ_STRING,sdsnew(":"));
shared.plus = createObject(OBJ_STRING,sdsnew("+"));
/* Shared command error responses */
shared.wrongtypeerr = createObject(OBJ_STRING,sdsnew(
"-WRONGTYPE Operation against a key holding the wrong kind of value\r\n"));
shared.err = createObject(OBJ_STRING,sdsnew("-ERR\r\n"));
shared.nokeyerr = createObject(OBJ_STRING,sdsnew(
"-ERR no such key\r\n"));
shared.syntaxerr = createObject(OBJ_STRING,sdsnew(
"-ERR syntax error\r\n"));
shared.sameobjecterr = createObject(OBJ_STRING,sdsnew(
"-ERR source and destination objects are the same\r\n"));
shared.outofrangeerr = createObject(OBJ_STRING,sdsnew(
"-ERR index out of range\r\n"));
shared.noscripterr = createObject(OBJ_STRING,sdsnew(
"-NOSCRIPT No matching script. Please use EVAL.\r\n"));
shared.loadingerr = createObject(OBJ_STRING,sdsnew(
"-LOADING Redis is loading the dataset in memory\r\n"));
shared.slowscripterr = createObject(OBJ_STRING,sdsnew(
"-BUSY Redis is busy running a script. You can only call SCRIPT KILL or SHUTDOWN NOSAVE.\r\n"));
shared.masterdownerr = createObject(OBJ_STRING,sdsnew(
"-MASTERDOWN Link with MASTER is down and replica-serve-stale-data is set to 'no'.\r\n"));
shared.bgsaveerr = createObject(OBJ_STRING,sdsnew(
"-MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.\r\n"));
shared.roslaveerr = createObject(OBJ_STRING,sdsnew(
"-READONLY You can't write against a read only replica.\r\n"));
shared.noautherr = createObject(OBJ_STRING,sdsnew(
"-NOAUTH Authentication required.\r\n"));
shared.oomerr = createObject(OBJ_STRING,sdsnew(
"-OOM command not allowed when used memory > 'maxmemory'.\r\n"));
shared.execaborterr = createObject(OBJ_STRING,sdsnew(
"-EXECABORT Transaction discarded because of previous errors.\r\n"));
shared.noreplicaserr = createObject(OBJ_STRING,sdsnew(
"-NOREPLICAS Not enough good replicas to write.\r\n"));
shared.busykeyerr = createObject(OBJ_STRING,sdsnew(
"-BUSYKEY Target key name already exists.\r\n"));
/* The shared NULL depends on the protocol version. */
shared.null[0] = NULL;
shared.null[1] = NULL;
shared.null[2] = createObject(OBJ_STRING,sdsnew("$-1\r\n"));
shared.null[3] = createObject(OBJ_STRING,sdsnew("_\r\n"));
shared.nullarray[0] = NULL;
shared.nullarray[1] = NULL;
shared.nullarray[2] = createObject(OBJ_STRING,sdsnew("*-1\r\n"));
shared.nullarray[3] = createObject(OBJ_STRING,sdsnew("_\r\n"));
shared.emptymap[0] = NULL;
shared.emptymap[1] = NULL;
shared.emptymap[2] = createObject(OBJ_STRING,sdsnew("*0\r\n"));
shared.emptymap[3] = createObject(OBJ_STRING,sdsnew("%0\r\n"));
shared.emptyset[0] = NULL;
shared.emptyset[1] = NULL;
shared.emptyset[2] = createObject(OBJ_STRING,sdsnew("*0\r\n"));
shared.emptyset[3] = createObject(OBJ_STRING,sdsnew("~0\r\n"));
for (j = 0; j < PROTO_SHARED_SELECT_CMDS; j++) {
char dictid_str[64];
int dictid_len;
dictid_len = ll2string(dictid_str,sizeof(dictid_str),j);
shared.select[j] = createObject(OBJ_STRING,
sdscatprintf(sdsempty(),
"*2\r\n$6\r\nSELECT\r\n$%d\r\n%s\r\n",
dictid_len, dictid_str));
}
shared.messagebulk = createStringObject("$7\r\nmessage\r\n",13);
shared.pmessagebulk = createStringObject("$8\r\npmessage\r\n",14);
shared.subscribebulk = createStringObject("$9\r\nsubscribe\r\n",15);
shared.unsubscribebulk = createStringObject("$11\r\nunsubscribe\r\n",18);
shared.psubscribebulk = createStringObject("$10\r\npsubscribe\r\n",17);
shared.punsubscribebulk = createStringObject("$12\r\npunsubscribe\r\n",19);
/* Shared command names */
shared.del = createStringObject("DEL",3);
shared.unlink = createStringObject("UNLINK",6);
shared.rpop = createStringObject("RPOP",4);
shared.lpop = createStringObject("LPOP",4);
shared.lpush = createStringObject("LPUSH",5);
shared.rpoplpush = createStringObject("RPOPLPUSH",9);
shared.lmove = createStringObject("LMOVE",5);
shared.blmove = createStringObject("BLMOVE",6);
shared.zpopmin = createStringObject("ZPOPMIN",7);
shared.zpopmax = createStringObject("ZPOPMAX",7);
shared.multi = createStringObject("MULTI",5);
shared.exec = createStringObject("EXEC",4);
shared.hset = createStringObject("HSET",4);
shared.srem = createStringObject("SREM",4);
shared.xgroup = createStringObject("XGROUP",6);
shared.xclaim = createStringObject("XCLAIM",6);
shared.script = createStringObject("SCRIPT",6);
shared.replconf = createStringObject("REPLCONF",8);
shared.pexpireat = createStringObject("PEXPIREAT",9);
shared.pexpire = createStringObject("PEXPIRE",7);
shared.persist = createStringObject("PERSIST",7);
shared.set = createStringObject("SET",3);
shared.eval = createStringObject("EVAL",4);
/* Shared command argument */
shared.left = createStringObject("left",4);
shared.right = createStringObject("right",5);
shared.pxat = createStringObject("PXAT", 4);
shared.px = createStringObject("PX",2);
shared.time = createStringObject("TIME",4);
shared.retrycount = createStringObject("RETRYCOUNT",10);
shared.force = createStringObject("FORCE",5);
shared.justid = createStringObject("JUSTID",6);
shared.lastid = createStringObject("LASTID",6);
shared.default_username = createStringObject("default",7);
shared.ping = createStringObject("ping",4);
shared.setid = createStringObject("SETID",5);
shared.keepttl = createStringObject("KEEPTTL",7);
shared.load = createStringObject("LOAD",4);
shared.createconsumer = createStringObject("CREATECONSUMER",14);
shared.getack = createStringObject("GETACK",6);
shared.special_asterick = createStringObject("*",1);
shared.special_equals = createStringObject("=",1);
shared.redacted = makeObjectShared(createStringObject("(redacted)",10));
for (j = 0; j < OBJ_SHARED_INTEGERS; j++) {
shared.integers[j] =
makeObjectShared(createObject(OBJ_STRING,(void*)(long)j));
shared.integers[j]->encoding = OBJ_ENCODING_INT;
}
for (j = 0; j < OBJ_SHARED_BULKHDR_LEN; j++) {
shared.mbulkhdr[j] = createObject(OBJ_STRING,
sdscatprintf(sdsempty(),"*%d\r\n",j));
shared.bulkhdr[j] = createObject(OBJ_STRING,
sdscatprintf(sdsempty(),"$%d\r\n",j));
}
/* The following two shared objects, minstring and maxstrings, are not
* actually used for their value but as a special object meaning
* respectively the minimum possible string and the maximum possible
* string in string comparisons for the ZRANGEBYLEX command. */
shared.minstring = sdsnew("minstring");
shared.maxstring = sdsnew("maxstring");
}