机器学习——图像识别、分布式、推荐系统-8
文章目录
-
- Tensorflow与深度学习
- 深度学习
- CIFAR图片分类
- CIFAR图片分类设计
- 分布式会话API
- hooks
- 常用钩子
- 分布式Tensorflow
- 分布式原理
- 多机多卡分布式的架构
- 分布式的模式
- 分布式API
- 1、创建集群
- 2、创建服务
- 3、工作节点指定设备运行
- 分布式案例
- 将图片识别的程序改成分布式
- 推荐系统
- 生活中无时无刻都在使用着推荐系统
- 推荐系统的意义
- ——解决信息过载
- 如何去给你的网站用户推荐?
- ——推荐的依据:
- 推荐系统的结构
- 推荐系统的原理
- 推荐系统的分类
- 推荐系统的分类
- 基于用户的协同过滤
- 基于物品的协同过滤
- 基于物品的协同过滤分析
- 用户电影打分表
- 1.相似度计算公式
- 对于用户A来说:
- 对于用户B来说
- 对于用户C来说
- 对于用户D来说
- 合并四个矩阵,得出一个总矩阵:
- 计算相似度为:
- 2.计算用户对未看过电影兴趣度
- ItemCF与UserCF的综合对比
- 公司 算法 用途
- 为什么新闻推荐使用UserCF算法,而购物网站使用ItemCF算法?
- ItemCF的缺点
- 改进的协同过滤-隐语义模型
- 隐因子矩阵分解
- 损失函数最小化求解
- 隐语义模型与ItemCF、UserCF对比
- 推荐系统开源库
- python-recsys安装(python2)
- 为了不影响外面环境,在虚拟环境中运行
-
- 推荐系统应用
- id,电影名称,电影类型
- id,性别,年龄,职业
- 用户id,电影id,评分,时间戳
- python-recsys-----矩阵分解API
- SVD分析
- 案例分析
- python-recsys----- 数据API
- data分析
- python-recsys----- 评估API
- data分析
- 开启运行输出信息
- 总结
Tensorflow与深度学习
深度学习
1、CIFAR图像分类
2、分布式会话函数
3、分布式TensorFlow
4、推荐系统
CIFAR图片分类

CIFAR图片分类设计
——cifar_data.py 读取图片数据
——
——cifar_model.py 建立神经网络模型
——
——cifar_train.py 训练模型

分布式会话API
——MonitoredTrainingSession(master=‘’,is_chief=True,checkpoint_dir=None,
—— hooks=None,save_checkpoint_secs=600,save_summaries_steps=USE_DEFAULT,
save_summaries_secs=USE_DEFAULT,config=None)
——分布式会话函数
——master:指定运行会话协议IP和端口(用于分布式)
—— “grpc://192.168.0.1:2000”
——is_chief是否为主worker(用于分布式)
—— 如果True,它将负责初始化和恢复基础的TensorFlow会话。如果False,
——它将等待一位负责人初始化或恢复TensorFlow会话。
——checkpoint_dir:检查点文件目录,同时也是events目录
——config:会话运行的配置项, tf.ConfigProto(log_device_placement=True)
——hooks:可选SessionRunHook对象列表
——
——should_stop():是否异常停止
——run():跟session一样可以运行op
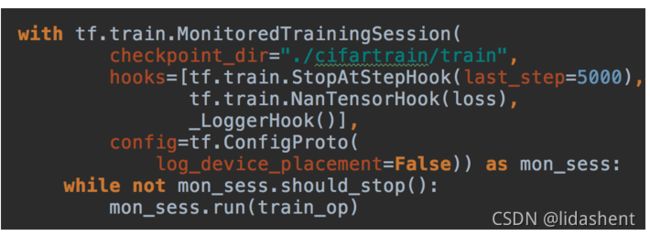
hooks
——tf.train.SessionRunHook
——Hook to extend calls to MonitoredSession.run()
——1、begin():
——在会话之前,做初始化工作
——2、before_run(run_context)
在每次调用run()之前调用,以添加run()中的参数。
——ARGS:
——run_context:一个SessionRunContext对象,包含会话运行信息
——return:一个SessionRunArgs对象,例如:tf.train.SessionRunArgs(loss)
——3、after_run(run_context,run_values)
在每次调用run()后调用,一般用于运行之后的结果处理
——该run_values参数包含所请求的操作/张量的结果 before_run()。
——该run_context参数是相同的一个发送到before_run呼叫。
——ARGS:
——run_context:一个SessionRunContext对象
——run_values一个SessionRunValues对象, run_values.results
——
注:再添加钩子类的时候,继承SessionRunHook
常用钩子
——tf.train.StopAtStepHook(last_step=5000)
——
——指定执行的训练轮数也就是max_step,超过了就会抛出异常
——
——tf.train.NanTensorHook(loss)
——
——判断指定Tensor是否为NaN,为NaN则结束
注:在使用钩子的时候需要定义一个全局步数:global_step = tf.contrib.framework.get_or_create_global_step()
分布式Tensorflow
分布式Tensorflow是由高性能的gRPC框架作为底层技术来支持的。这是一个通信框架gRPC(google remote procedure call),是一个高性能、跨平台的RPC框架。RPC协议,即远程过程调用协议,是指通过网络从远程计算机程序上请求服务。
分布式原理
单机多卡
多机多卡(分布式)


多机多卡分布式的架构
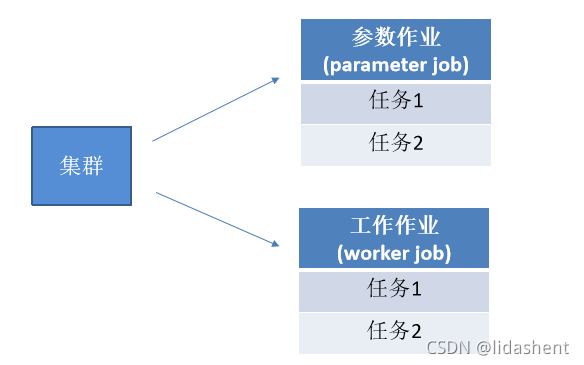
注:参数作业所在的服务器称为参数服务器(parameter server),负责管理
参数的存储和更新;工作节点的服务器主要从事计算的任务,如运行操作,
worker节点中需要一个主节点来进行会话初始化,创建文件等操作,其他节点等
待进行计算
分布式的模式
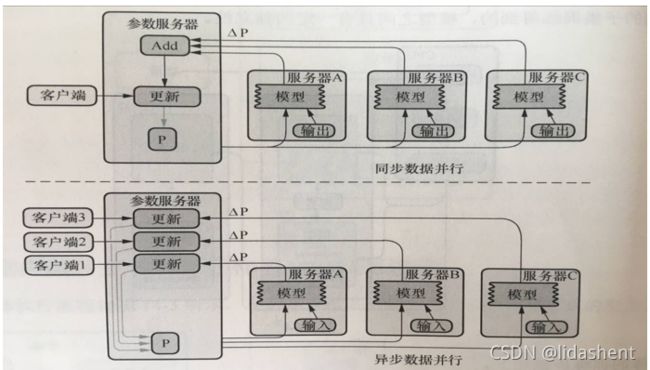
分布式API
——1、创建一个tf.train.ClusterSpec,用于对集群中的所有任务进行描述,该描述内容对所有任务应该是相同的
——
——2、创建一个tf.train.Server,用于创建一个任务(ps,worker),并运行相应作业上的计算任务。
1、创建集群
1、 cluster = tf.train.ClusterSpec({“ps”: ps_spec, “worker”: worker_spec})
cluster = tf.train.ClusterSpec(
{“worker”: [“worker0.example.com:2222”, /job:worker/task:0 “worker1.example.com:2222”, /job:worker/task:1 “worker2.example.com:2222”], /job:worker/task:2
“ps”:
[“ps0.example.com:2222”, /job:ps/task:0 “ps1.example.com:2222”] /job:ps/task:1
})

2、创建服务
——tf.train.Server(server_or_cluster_def, job_name=None, task_index=None,
——protocol=None, config=None, start=True)
——创建服务(ps,worker)
——server_or_cluster_def: 集群描述
——job_name: 任务类型名称
——task_index: 任务数
——
——attribute:target
——返回tf.Session连接到此服务器的目标
——method:join()
——参数服务器端,直到服务器等待接受参数任务关闭
3、工作节点指定设备运行
——tf.device(device_name_or_function)
——选择指定设备或者设备函数
——if device_name:
——指定设备
——例如:"/job:worker/task:0/cpu:0”
——
——if function:
——tf.train.replica_device_setter(worker_device=worker_device,
——cluster=cluster)
——作用:通过此函数协调不同设备上的初始化操作
——worker_device:为指定设备, “/job:worker/task:0/cpu:0” or
——"/job:worker/task:0/gpu:0"
——cluster:集群描述对象
注:使用with tf.device(),使不同工作节点工作在不同的设备上
分布式案例
1、创建集群对象
2、创建服务
3、服务端等待接受参数
4、客户端使用不同设备进行定义模型以进行计算
5、使用高级会话类
将图片识别的程序改成分布式
推荐系统
1、推荐系统的背景
2、推荐系统的意义
3、推荐系统原理介绍
4、推荐系统应用
生活中无时无刻都在使用着推荐系统
推荐系统的意义
——互联网时代的信息量过载:
——
——视频网站每天都会有上万小时的视频上传
——购物网站每天上架百万商品
——每天大概数以万计的新闻报道
——解决信息过载
——
——搜索引擎时代
——分类导航 雅虎
——搜索 谷歌、百度
——
——个性化时代(提高用户粘度、增加营收)
——系统自动推荐相关的东西 今日头条、豆瓣、电商
如何去给你的网站用户推荐?
——推荐的依据:
——用户的历史行为
——用户的兴趣点
——社交关系
——…
推荐系统的结构
推荐系统的原理
1、推荐系统的分类
2、基于物品的协同过滤分析
3、改进的协同过滤-隐语义模型
4、推荐系统开源库
推荐系统的分类
基于内容的推荐:
1、推荐系统最初使用的最广泛的推荐机制
2、根据推荐物品或内容的元数据特征,发现物品或者内容
的相关性,然后进行推荐相似的物品(tf-idf权重)
3、物品通过内容比较关联:
电影题材:爱情片/动作片/科幻片/惊悚片
电影人物:范迪塞尔/保罗/吴京
电影时间:2017/7/7…
4、优缺点:
物品相似度的分析仅仅依赖于物品本身的特征,这里没有考
虑人对物品的态度
推荐系统的分类
——基于协同过滤的推荐(CF->Collaboration Filter)
——
——
——基于用户的协同过滤(UserCF)
——计算用户的相似度,推荐相似用户的喜好
——
——
——
——
——基于物品的协同过滤(ItemCF重点)
——计算物品的相似度,推荐相似度高的物品(不同于基于内容的推荐)
——
基于用户的协同过滤

基于物品的协同过滤
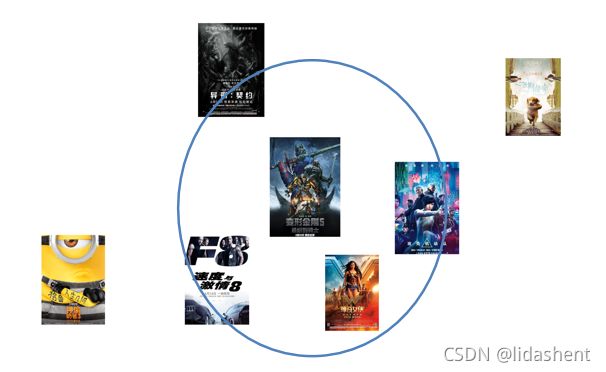
基于物品的协同过滤分析
步骤:
(1)计算物品之间的相似度
(2)计算被推荐物品的兴趣度(评分)
(3)根据物品的相似度和用户的历史行为给用户生
成推荐列表
用户电影打分表
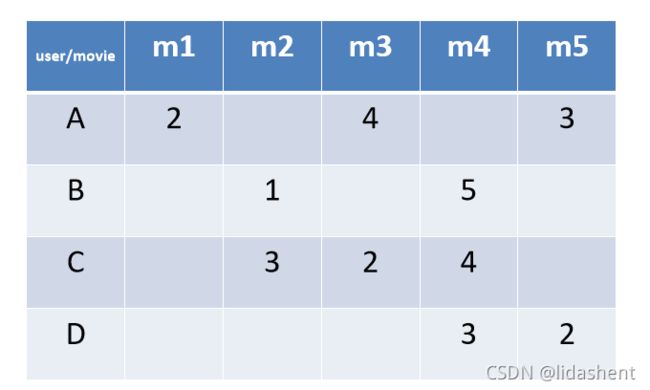
1.相似度计算公式

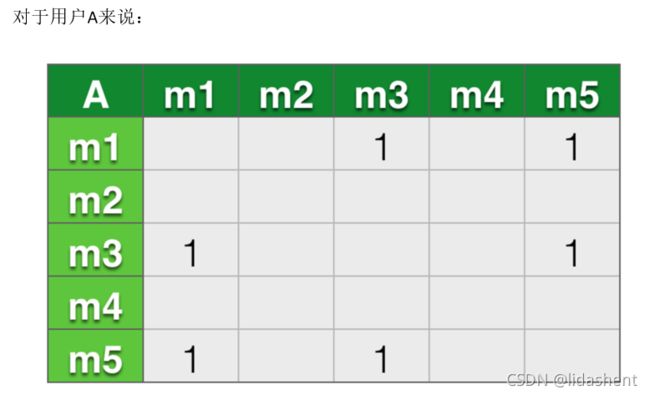
对于用户A来说:
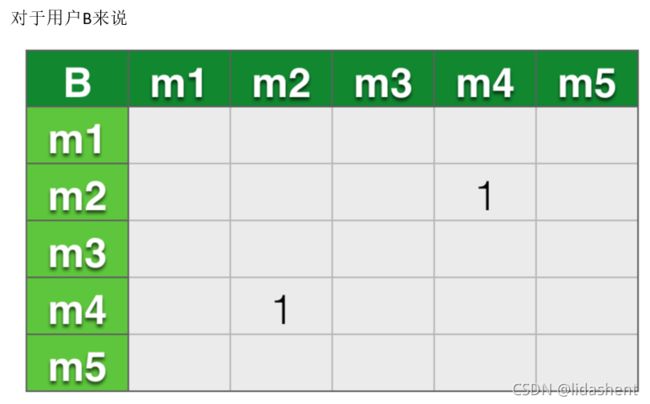
对于用户B来说
对于用户C来说
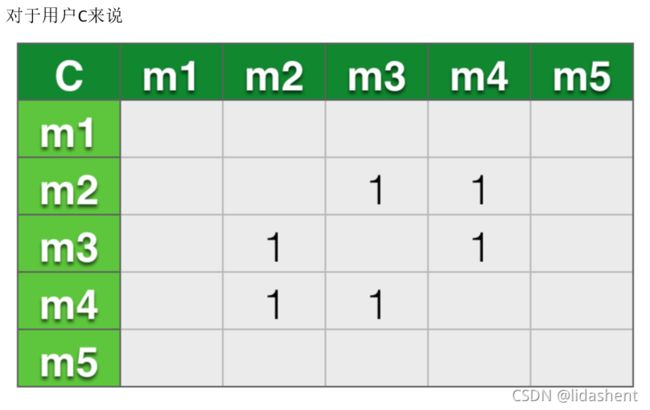
对于用户D来说
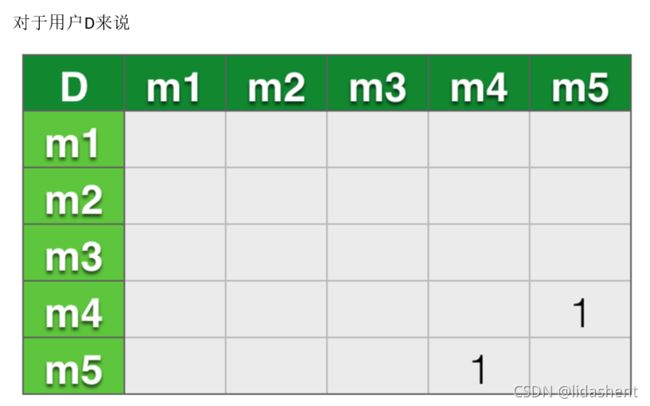
合并四个矩阵,得出一个总矩阵:
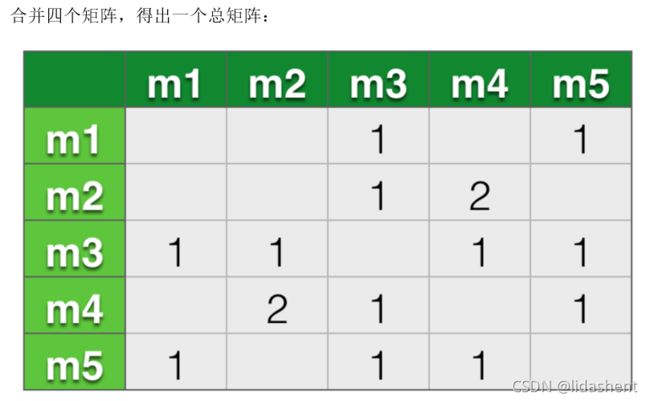
计算相似度为:
2.计算用户对未看过电影兴趣度

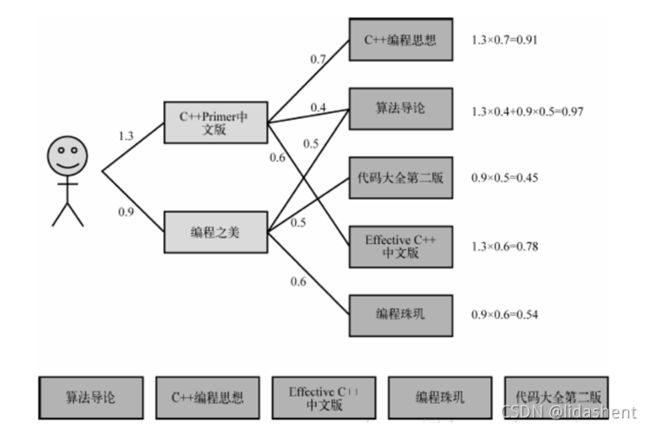
ItemCF与UserCF的综合对比
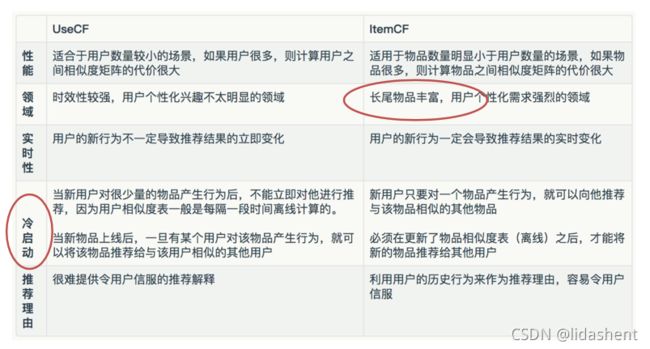
公司 算法 用途
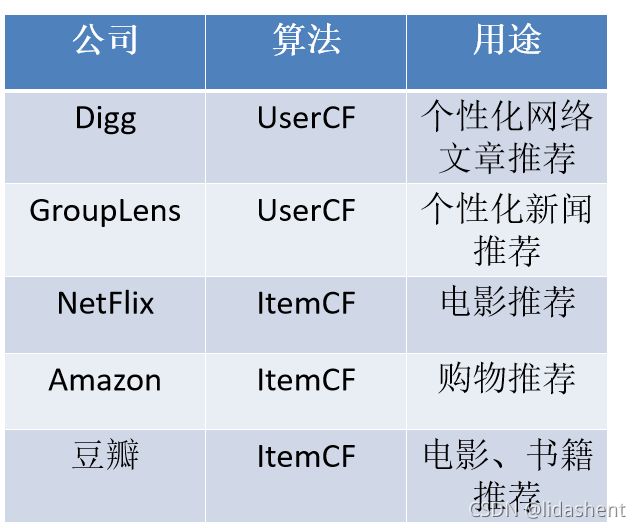
为什么新闻推荐使用UserCF算法,而购物网站使用ItemCF算法?
UserCF算法的推荐结果着重于反映那些与目标用户兴趣相似的小群体的热点,而ItemCF算法的推荐结果着重于维护目标用户的历史兴趣。换句话说,UserCF的推荐更加社会化,而ItemCF的推荐更加个性化。
ItemCF的缺点
越是热门的类,其类内物品的相似度越大。除此之外,不同领域的最热门物品之间的相似度往往也是很高的
改进的协同过滤-隐语义模型
——目的:
——用户评分矩阵中,有很多位置空着的,希望能够正确
——填满未打分的项目
——
——
——主要思想:
——找到隐藏因子,可以对user和item进行关联
——
——
——
隐因子矩阵分解


损失函数最小化求解

隐语义模型与ItemCF、UserCF对比
——理论基础
——隐语义模型有较好的理论基础,后两种是一种基于统计的方法,
——没有学习过程
——
——计算复杂度
——隐语义模型时间复杂度高于后两者,主要是需要多次迭代
——
——在线实时推荐
——隐语义模型不能在线实时推荐,需要线下计算好
——
——推荐解释
——ItemCF、UserCF有较好的推荐解释,利用用户的历史行为来解释推荐结果
——而隐语义模型它的隐类能够代表一类兴趣或者物品,却很难用自然语言描
——述并生成解释展现给用户
——
——
推荐系统开源库
LibFM
LibFM是专门用于矩阵分解的利器
Python-recsys
一个非常轻量级的开源推荐系统,Python-recsys主要实现了
SVD、Neighborhood SVD推荐算法(python2)
Crab
Crab是基于Python开发的开源推荐软件,其中实现有item
和user的协同过滤,只支持python2
pyspark
目前使用比较广泛的机器学习库,集成了推荐系统(python2)
python-recsys安装(python2)
1、安装依赖项:
pip install csc-pysparse
pip install networkx
pip install divisi2
2、源码安装python-recsys
tar xvfz python-recsys.tar.gz
cd python-recsys
为了不影响外面环境,在虚拟环境中运行
python setup.py install
推荐系统应用
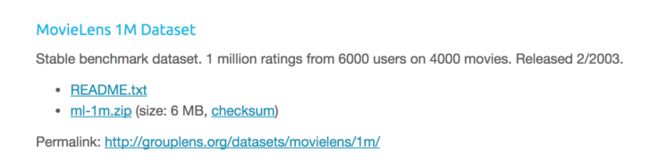
——电影推荐数据集 MovieLens 6M数据集
——6000名用户对4000部电影的100万条评分数据
——
——
——分为三部分:电影信息,用户信息,打分信息
——每位用户至少评判20场电影
——
id,电影名称,电影类型
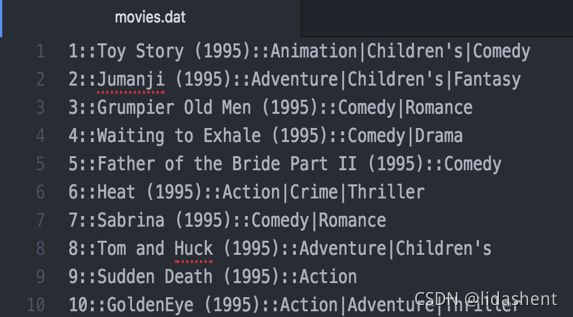
id,性别,年龄,职业
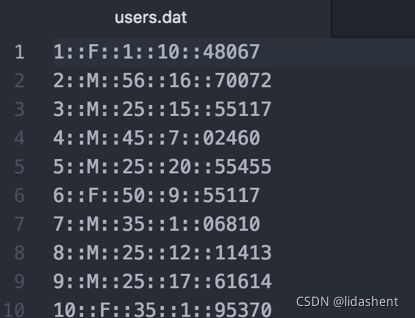
用户id,电影id,评分,时间戳
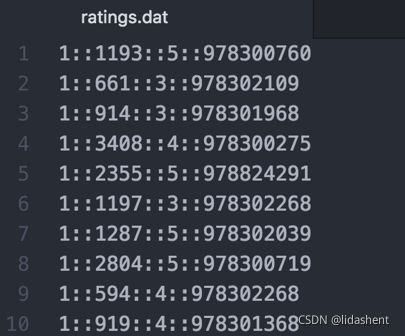
python-recsys-----矩阵分解API
——recsys.algorithm.factorize.SVD
SVD分析
——recsys.algorithm.factorize.SVD()
——矩阵分解法推荐
——method:
——load_data(filename=,sep=, format=):加载文件数据
——1、filename文件名
——2、sep分割的字符,
——3、format为字典,矩阵的value, row, col指定为文件中的第几列,
——还有ids指定数据类型
——set_data(train):直接输入获取的数据,SVD没有加载文件时候
——
——compute(k=, min_values = 10, post_normalize=None,savefile=):
——计算评分矩阵
——1、K为隐因子数量,默认100
——2、min_values为某物品评分用户数量少于10个的直接删除
——3、post_normalize:数据前进行归一化
——4、savefile:文件的名字movielens, 例如movielens.zip
_____similarity(item1,item2):计算两个物品相似度
——
——similar(item):获得默认10个相近的物品
——
——recommend(userid,is_row=False):推荐给某用户
——的指定数量的物品或者为某物品没有打过分的用户
——打分前10名,is_row为True则id为数据格式中的row的id,
——
——predict(itemid,userid):
——返回预测某用户对物品的评分
——
——get_matrix().value(ITEMID, USERID)获取评分矩阵中的值
——
——load_model(filename):加载本地模型,模型加载无需训练
——save_model(filename):保存模型到本地,zip格式
案例分析
1、加载数据
2、计算评分矩阵(compute)
3、推荐指定用户物品
4、推荐评估(Data、RMSE)
python-recsys----- 数据API
——recsys.datamodel.data.Data
data分析
——recsys.datamodel.data.Data()
——数据处理类
——method:
——load(filename,sep=, format=):加载文件数据
——1、filename文件名,不是字典
——2、sep分割的字符,
——3、format为字典,矩阵的value, row, col指定为文件中的第几列,
——ids指定数据类型
——split_train_test(percent=80):分割数据集,返回训练测试集
——给SVD.set_train使用,train或者test的数据格式顺序为: ——,col>,通过get()获取, ——add_tuple(tuple):添加元组 ——recsys.evaluation.prediction.RMSE ——recsys.evaluation.prediction.RMSE(data = None) ——数据处理类 ——data包含真实值和预测值的元组列表 ——例如:[(3,2.3),(1,0.9),(5,4.9),(2,0.9),(3,1.5)] ——method: ——add(rating,rating_pred):单独添加真实值与预测值 ——compute():计算误差,返回误差字符串 import recsys.algorithm recsys.algorithm.VERBOSE = True 你看懂了吗?python-recsys----- 评估API
data分析
开启运行输出信息
总结