原文链接:http://tecdat.cn/?p=23982
在等距时间段内以一系列点获得的数据通常称为时间序列数据。月度零售销售、每日天气预报、失业数据、消费者情绪调查等都是时间序列数据的经典示例。事实上,自然界、科学、商业和许多其他应用中的大多数变量都依赖于可以在固定时间间隔内测量的数据。
分析时间序列数据的关键原因之一是了解过去并预测未来。科学家可以利用历史气候数据来预测未来的气候变化。营销经理可以查看某种产品的历史销售额并预测未来的需求。
在数字世界中,时间序列数据的一个很好的应用可以是分析特定网站/博客的访问者,并预测该博客或页面将来会吸引多少用户。
在本文中,我们将查看与访问此博客的用户有关的时间序列数据集。我将在 R 中建立与 Google Analytics API 的连接,并将每日用户引入。然后我们将创建一个预测来预测博客可能会吸引的用户数量。我随机选择了日期范围仅用于说明目的。
这里的想法是让我们学习如何将 Google Analytics 中的数据查询到 R 中以及如何创建时间序列预测。
让我们首先设置我们的工作目录并加载必要的库:
# 设置工作目录
setwd("/Users/")
# 加载所需的软件包。
library(ggplot2) # 用于绘制一些初始图。
library(forecast) # 用于时间序列的预测。从 Google Analytics API 查询博客用户的每日时间序列数据。下面是设置我想要的参数的初始查询。在这个例子中,我只是从 2017 年 1 月中旬到 2017 年 5 月中旬每天拉博客的用户数据。
# 创建一个在谷歌分析查询中使用的参数列表
listparam = Int(
dinsns= "ga:date",
mercs = "ga:users",
sot = "ga:date",
maresults = 10000,
tae.id = "ga:99395442"
)设置了我的查询参数列表,我就可以开始查询 Google Analytics API:
# 存储谷歌分析的查询结果
es = QueyBlder(lit_pram)
#通过查询结果和oauth从Google Analytics获得数据
df = GetRporData(rs, oaut_tken, splidawse = T)
# 对结果重新排序
# 检查前30天的用户
head(df,30)
从上面的 30 条记录中可以看出,唯一使用的特征或变量是日期和用户数量。这是一个非常简单的数据集,但可以很好地说明时间序列预测示例。
时间序列分析中最重要的步骤之一是绘制数据并检查它是否有序列中的任何模式和波动。让我们在时间序列图中绘制我们日常用户的结果,以检查趋势或季节性,周末用S符号标识:
# 处理日期和绘制每日用户
df$dte <- as.ate(dfdte, '%m%d')
df$d = as. fator(weekays(dfdate))
ggplot( daa = df, as( dateusers )) +
geom_line()
用这个博客的每日用户数据看上面的图表,用户似乎随着时间的推移而增加。该序列从不到 100 名用户开始,在一天内在给定的时间点增加到 400 多名用户。用户似乎普遍存在上升 趋势 。我们还可以粗略地识别出系列中的波峰和波谷,或起伏。这种模式可能与 季节性变化有关。换句话说,每天访问此博客的用户数量似乎存在一定程度的季节性。我们可以按星期几运行一个简单的箱线图,尝试更好地可视化这种模式:
# 创建工作日作为因素并绘制它
df$wd = fator(df$kd)
ggplot(df, aes(x=wd, y=srs)) +
geom_boxplt()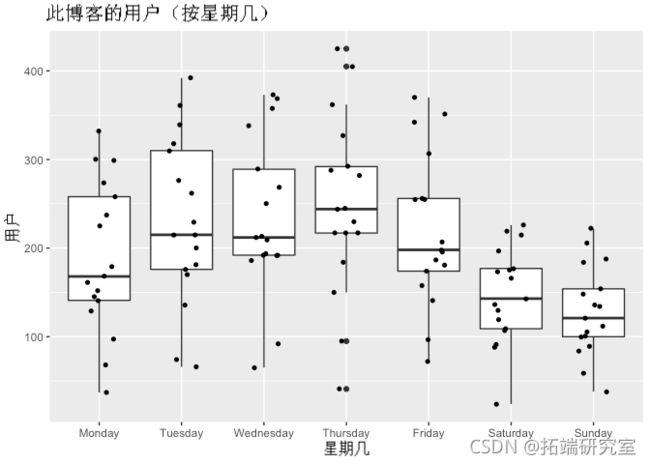
正如您在上图中所看到的,周二到周四是访客最多的日子。它吸引了很多用户,在某些时候,某些工作日的用户已经超过 400 人。事实上,与一周中的其他日子相比,周四似乎包含大量异常值。相反,与一周中的其他日子相比,周六、周日和周一吸引的用户数量最少。
因此,当我们重新审视上面的时间序列图时,我们现在可以说用户倾向于在周内(星期四的高峰期)更多地访问此博客,而在周末(星期日)则更少。这是我们之前观察到的季节性变化。
在时间序列分析中,我们倾向于将观察到的时间序列数据分解为三个基本组成部分: 趋势、 季节性 和 不规则。
我们这样做是为了观察它的特性并将_信号_ 与 _噪声_分开 。我们分解时间序列识别模式、进行估计、对数据建模并提高我们了解正在发生的事情和预测未来行为的能力。分解时间序列使我们能够在最能描述其行为的数据中拟合模型。
趋势成分是时间序列的长期方向,反映了观察到的潜在水平或模式。在我们的例子中,趋势是向上的,这反映了越来越多的用户访问博客。
季节性成分包括在时间、幅度和方向上一致的数据中观察到的一般效应。例如,在我们这里的例子中,我们看到用户在周三到周四频繁出现正峰值。季节性可能由许多因素驱动。在零售业,季节性发生在特定日期,例如长假、双十一。在我们的博客示例中,似乎用户在学习/工作周访问更多,而在周末访问更少。
不规则,或者也被称为残差,是我们去除趋势和季节性成分后剩下的成分。它反映了序列中不可预知的波动。
在我们分解这个博客日常用户的时间序列之前,我们需要将查询的用户数据框转换为 R 中的时间序列对象 _ts()_:
# 将数据框转换成时间序列对象
dfts = ts(df$ers, freqny = 7)
# 分解时间序列并绘制结果
dcmp = dompose(dfts, tye = "aditve")
prit(dcmp)

plot(decp)
通常,时间序列分解采用加法 或 乘法的形式 。还有其他形式的分解,但我们不会在本例中涉及这些。
简单地说,加法分解用于时间序列,其中序列的基础水平波动但季节性的幅度保持相对稳定。随着趋势水平随时间变化,季节性和不规则成分的幅度不会发生显着变化。
另一方面,当季节性和不规则的幅度随着趋势的增加而增加时,使用乘法分解。
我们可以在上面的初始时间序列图中观察到,季节性的幅度在整个时间序列中基本保持稳定,这表明加法分解更有意义。
我们在这个练习中的目标之一也是尝试和拟合一个模型,使我们能够推断数据并进行预测,预测本博客的未来用户。很明显,预测时间序列的一个关键假设是,目前的趋势将继续。也就是说,在没有任何令人惊讶的变化或冲击的情况下,总体趋势在未来应该保持类似(至少在短期内)。我们也将不考虑观察到的模式的任何潜在原因(例如,本博客的任何帖子在微信公众号有很大的知名度,可能促使很多用户来到博客页面,等等)。
当我们在时间序列中进行预测时,我们的目的是在给定某个时间点的过去观察历史的情况下预测某个未来值。需要围绕拟合时间序列模型所需的指数平滑形式进行许多考虑。为简单起见,我们将在这里只涉及一种方法。
因此,考虑到我们的时间序列存在季节性并使用加法分解,适当的平滑方法是 Holt-Winters ,它使用指数加权移动平均线来更新估计值。
让我们在时间序列数据中拟合一个预测模型:
# 在时间序列中应用HoltWinters模型并检查拟合情况
print(pred)
从上面的模型拟合中可以看出,Holt-Winters 的平滑是使用三个参数完成的: alpha、 beta 和 gamma。Alpha 估计趋势(或水平)分量,β 估计趋势分量的斜率,而 gamma 估计季节性分量。这些估计值基于系列中的最新时间点,这些值将用于预测。alpha、beta 和 gamma 的值范围从 0 到 1,其中接近 0 的值表示最近的观测值在估计中的权重很小。
从上面的结果中,我们可以看到 alpha 的平滑估计值为 0.4524278,beta 为 0.0211364,gamma 为 0.5593518。alpha 的值大约为 0.5,这表明短期的、近期的观察和历史的、更远的观察都在时间序列的趋势估计中起作用。beta 值接近于零,这表明趋势分量的斜率(从一个时间段到下一个时间段的水平变化)在整个序列中保持相对相似。gamma 的值与 alpha 相对相似,这表明季节性估计基于近期和远距离观测。
下面的模型拟合(红色)和实际观察值(黑色)的图有助于说明结果:
# 绘制模型拟合图
plot(pred)
我们现在可以推断模型来预测这个博客的未来用户:
#对未来用户的预测
forecast(pred, h=28)
请注意上图中,粗而亮的蓝线表示用户在下个月左右访问此博客的预测。深蓝色阴影区域代表 80% 的预测区间,浅蓝色阴影区域代表 95% 的预测区间。正如我们所见,该模型通常说明了观察到的模式,并且在估计此博客的未来用户数量方面做得相对较好。
建议我们检查预测模型准确性。首先让我们看看 平方误差总和 (SSE) ,它衡量我们的模型与实际观察数据的差距。执行平方是为了避免负值,并为较大的差异赋予更多权重。接近 0 的值总是更好。在我们的例子中,我们可以看到我们模型的 SSE 是 9.8937336 10^4。
检查自相关也很重要。一般来说,自相关是用来评估时间序列和同一时间序列的时滞之间是否存在相关关系。这就像把该时间序列复制多次,并在每一步时间前粘贴,评估是否发现了一个模式。在时间序列误差的背景下,自相关被用来尝试和寻找存在于残差中的模式。这就是下面的关系图所要做的。
# 模型残差的相关图和柱状图
acf(residuals\[8:length\])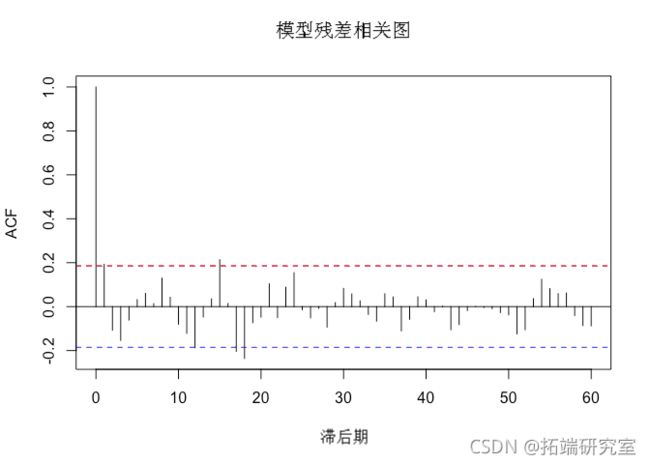
无需在 Correlogram 本身上花费太多时间,我们可以注意到,虽然模型运行得相对较好,但它在系列的早期阶段并没有像 _acf() 函数的_ 自相关结果 (y轴)在滞后 2 和 3 处。
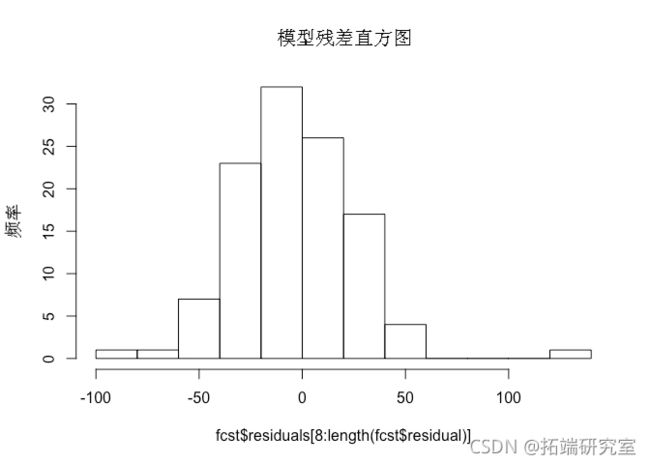
此外,我们可以从残差的直方图中看到,预测误差在一定程度上呈正态分布,存在一些异常值,表明模型拟合相对较好。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析