Python爬虫 | 爬取高质量小姐姐照片
Python爬虫 | 爬取高质量小姐姐照片
- 1、数据来源分析
- 2、获取author_id_list和img_id
- 3、代码实现
-
- 3.1、制作detial
- 3.2、制作detial_list
- 3.3、数据保存
- 3.4、批量获取
- 4、完整代码
- 声明
1、数据来源分析
在网页HTML源代码里,我们找到了每一张照片的地址为
https://photo.tuchong.com/5489136/f/360962642.jpg
解析如下
https://photo.tuchong.com/author_id_list/f/img_id.jpg
其中author_id_list和img_id都是我们需要自己获取的
2、获取author_id_list和img_id
打开网站图虫网首页,经过分析,发现数据请求是动态加载的来源是下面的请求
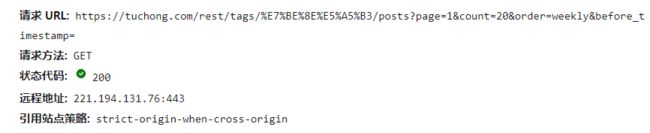
返回的数据中包含author_id_list和img_id,一个author_id_list对应好几个img_id,因此在获取数据的时候对每一个author_id_list下的图片进行单独保存,建立独立的文件夹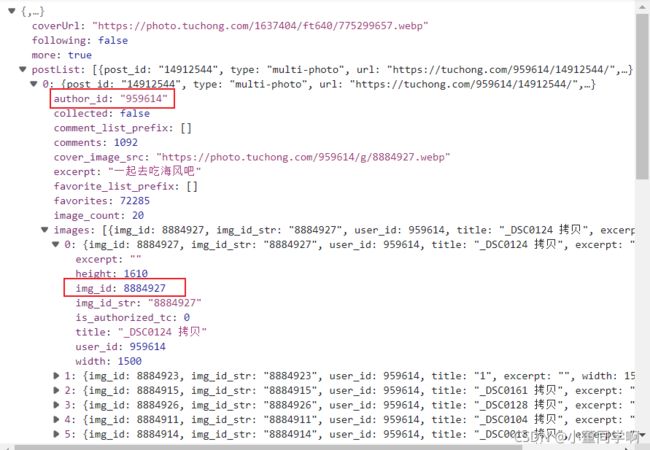
3、代码实现
3.1、制作detial
将每一个author_id_list和img_id保存到一个detial中,利用键值对的形式,author_id_list存放author_id_list,img_id存放img_id
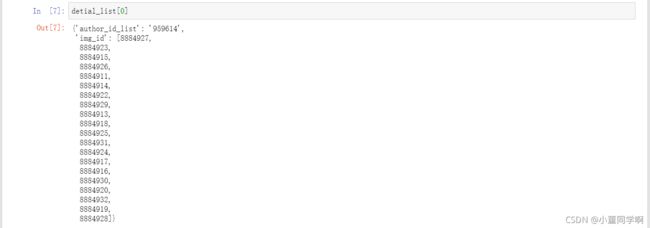
3.2、制作detial_list
将每一个detial存放在detial_list,那么第一页的所需数据就准备好了

3.3、数据保存
对每一个author_id建立应的文件夹
3.4、批量获取
前面的请求参数有page和count,表示请求页数和每一页的数据量,将page放在循环中就行了

4、完整代码
import requests
import os
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.44",
}
for i in range(1, 11):
url = f'https://tuchong.com/rest/tags/%E7%BE%8E%E5%A5%B3/posts?page={
i}&count=20&order=weekly&before_timestamp='
response = requests.get(url=url, headers=headers)
page = response.json()["postList"]
# 制作detial_list
detial_list = []
for item in page:
author_id_list = ""
img_id = []
detial = {
"author_id_list": author_id_list,
"img_id": img_id
}
author_id_list = (item["author_id"])
for it in item["images"]:
img_id.append(it["img_id"])
detial["author_id_list"] = author_id_list
detial["img_id"] = img_id
detial_list.append(detial)
for item in detial_list:
# 新建文件夹
author_id_list = item["author_id_list"]
if not os.path.exists(f'img/{
author_id_list}'):
os.makedirs(f"img/{
author_id_list}")
# 保存数据
for it in item["img_id"]:
with open(f'img/{
author_id_list}/{
it}.jpg', mode="wb") as fp:
page = requests.get(url=f"https://photo.tuchong.com/{
author_id_list}/f/{
it}.jpg", headers=headers)
data = page.content
fp.write(data)
# 打印提示信息
print(f"第{
i}页完成...")
毕竟图虫网提供高质量的图片,而且都是版权所有的,也就只是用于学习交流,不要太过分,爬取10页数据

源代码地址:gitee
声明
本文仅限于做技术交流学习,请勿用作任何非法商用!