Python常用库的使用(Numpy,Pandas,Matplotlib,wordcloud,Opencv-python,PIL)
一、前言
最近做python实验的时候,重点考察了对题述的库的使用,经过一段时间学习,将其汇总至一处,方便取用。
二、Numpy库
首先安装numpy库,只需要在cmd窗口输入pip install numpy即可,注意保证网速
导入库的时候,注意给numpy起个简称
import numpy as np
numpy中含有很强大的数组,它的主要对象时多维数组,数组的维度叫做轴Axes,轴的个数叫做秩Rank。
# 通过列表创建一位数组
np.array([1,2,3])
# Rank=1,len(Axes)=3
np.array([(1,2,3),(4,5,6)])
# Rank=2,len(Axes)=3此外,numpy还可以创建全是0,或者全是1的n维数组
# 创建一个三行四列的二维数组,全是0
np.zeros((3,4))
# 创建一个2*3*4的三维数组,全是1
np.ones((2,3,4))更厉害的是,它还可以使用full函数指定数组内容
# 创建一个5*5的二维数组,值都为2
np.full((5,5),2)它还能创建等差数组,一维或者二维...
# 创建一维等差数组[0,1,2,3,4]
np.arange(5)
# 指定范围2——5,生成的数组为[2,3,4]
np.arange(2,5)注意的是,在创建二维等差数组时,还可以使用reshape指定它的行列数。
# 创建二维等差数组[0,1,2][3,4,5]
print(np.arange(6).reshape((2,3)))加上随机数,也可以创建随机数组
# 随机创建一个二行三列的数组
np.random.rand(2,3)
# 创建一个随机的二维数组,但数字小于5,二行三列
np.random.randint(5,size=(2,3))
此外,它还可以进行求和操作,默认是对整个数组进行操作,但是如果进行轴的设置,就可以单独对行或者列求和。
# 假设a为一个二行三列的数组
# 对二行三列求和
np.sum(a)
# 对列求和,因为axis为0
np.sum(a,axis=0)
# 对行求和,因为axis为1
np.sum(a,axis=1)
在C语言或者java中,经常要求平均和排序,在numpy中已经实现好了
# 对数组a求平均,也可以像上面一样按照行列操作
np.mean(a)
# 对数组a排序,可以按照行列排序
np.argsort()
# 按照列排序
np.argsort(axis=0)
很重要的是!对于二维数组A、B,如果想将他们进行矩阵的运算,那么其实是有两种方法的
# 对于二维数组A和B,如果求其乘法
A=np.array([[1,2],[3,4]])
B=np.array([[5,6],[7,8]])
# 可以使用dot方法
np.dot(A,B)
# 当然也可以先将其转化为矩阵,然后直接进行*运算就行
np.mat(A)*np.mat(B)
其余矩阵基本操作有
# 计算对角线的和
np.tarce(A)
# 矩阵a的逆置
a.T
# 或者
np.linalg.inv(a)对二维数组一些基本操作的函数有
np.mean()# 平均值
np.cumsum(axis=0)# 按列累加
np.std()# 方差
np.var()# 标准差
np.argmax()# 最大值索引二、pandas库
安装pandas库需要在cmd输入pip install pandas
在导入的时候需要写上
import pandas as pd
其实,pandas作为数据处理的重要法宝,主要是对一维二维数据的处理,一维是Series,二维是Dataframe。数据导入后会产生索引,所以下面代码
# 将一维列表转化为Series
data=[1,"B",3,"D",5,6,"G",8,9]
s1=pd.Series(data)输出s1,可以发现
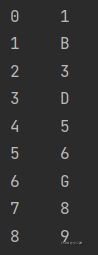
数据前面多了索引,但是最有意思的是,可以手动设置索引,比如
index1=[11,12,13,14,15,16,17,18,19] #手动设置索引 数值类型
index2=["你","这","瓜","要","熟","我","肯","定","要"]#手动设置索引 字符类型
s2=pd.Series(data,index=inlst)
s3=pd.Series(data,index=inlst1)
这样输出s2和s3就有了
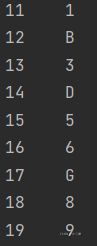
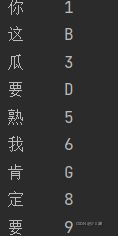
对于二维数据,我们使用Dataframe,主要用来处理Excel文件等,但是我们可以清楚的发现,在处理二维数据的时候,经常容易出现因为字符串长短不一而造成的不对齐问题 ,我们可以通过下面语句解决
pd.set_option('display.unicode.east_asian_width',True)在Dataframe中有很多很重要的属性
df1.values #查看所有元素
df1.index # 查看所有行名,重命名行名
df1.columns # 查看所有列名,重命名列名
df1.T #行列数据转换
df1.head(10) #查看前十条数据,默认五条
df1.tail(10) #查看后十条数据,默认五条
df1.shape() #查看行数和列数,df1.shape[0],就是看行,shape[1]就是看列
所以它亦可以单独修改行或者列的索引哟。
还有一点需要提一下,在导入文件时,encoding可以指定字符集类型,默认值为None,但是我们通常指定为utf-8,不修改的话可能会出错哈
三、matplotlib库
安装matplotlib库需要在cmd输入pip install matplotlib
在导入的时候需要写上
import matplotlib.pyplot as plt
import matplotlib
想必大家都知道,这是一个绘图的库,纵观我Qt和javaGUI的学习,在绘图之前我们需要一个窗口或者是画板,matplotlib也不例外,它需要一个Figure对象
fig=plt.figure()在拥有对象之后,我们还需要轴!添加步骤如下
ax=fig.add_subplot(111)# 参数的解释为,在画板的第一行第一列的位置确定一个对象
# 如果通过 fig.add_subplot(2,2,1)可以将整个面板画成2*2 的形式,第三个参数的范围就是1到4
之后还有一些基本设置
# 下面参数含义分别是x轴范围,y轴范围,图的标题,x轴标签,y轴标签
# ax.set(xlim=[0,5],ylim=[0,5],title='林哥的图',xlabel="X轴",ylabel="Y轴")
# 上述绘图方法的简便方式是
# plt.plot([1,2,3,4],[10,20,25,40],color='lightblue',linewidth=3)
# plt.xlim(0,5)
# plt.show()matplotlib库常与numpy库结合使用,因为numpy中含有三角函数之类的复杂函数,可以通过matplotlib显示出来,例如希望画一个正弦图像
# 先设置图像的x轴范围,0到π,其中np.pi指的是π
x=np.linespace(0,np.pi)
sinx=np.sin(x)
# 第一个参数就是范围,第二个是函数
ax.plot(x,sinx)
plt.show()等等!还有一个问题,matplotlib不支持中文!所以为了让中文显示出来,需要加上这两行代码
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.sans-serif'] = ['SimHei']它还可以绘制散点图、条形图、直方图、饼图、箱型图、泡泡图、等高线、雷达图等等..
四、wordcloud库
安装wordcloud库需要在cmd输入pip install wordcloud
在导入的时候需要写上
import wordcloud
import os
import wordcloud
from wordcloud import WordCloud
from matplotlib import pyplot as plt
# 加上这句话可以使wordcloud支持中文
os.environ['FONT_PATH'] = '/usr/share/fonts/wenquanyi/wqy-microhei/wqy-microhei.ttc'
# 我觉得更好的方法是使用font等于底下这一串,之后在wordcloud那一行加上font_path=font
font = r'C:\Windows\Fonts\simfang.ttf'
w=wordcloud.WordCloud()
# 加载词云文本
w.generate("word by python ")
w.to_file("file")# 输出词云文件
# 配置参数
wo=wordcloud.WordCloud(width=400,height=400,min_font_size=4,font_step=2,font_path=r'C:\Windows\Fonts\simfang.ttf')
# width 指定词云对象生成图片的宽度,默认400像素
# >>>w=wordcloud.WordCloud(width=600)
# height 指定词云对象生成图片的高度,默认200像素
# >>>w=wordcloud.WordCloud(width=400)
# min_font_size可以指定云字体的最小字号,默认四号
# font_step 可以指定云中字体的步进间隔,默认为1
# font_path 指定字体文件的路径,默认为None,一般我们设置为r'C:\Windows\Fonts\simfang.ttf'
# max_words指定词云显示的最大单词数量,默认为200
# stop_words 指定词云的排除词列表,默认无
# mask指定词云形状,默认为长方形,需要引用imread函数
# from scipy.misc import imread
# mk=imread(filepath) 在里面填充文件图片路径就行
# background_color 指定词云的背景颜色,默认为黑色。
太懒了,就直接把笔记复制过来了...
五、opencv-python 库
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# openCV 常见函数
# cv.imread(filepath,flags) filepath指的是图片路径,flags指的是图片标志
# IMREAD_COLOR默认参数,读入彩色图片
# cv.imshow(wname,img)
# 第一个参数是显示图形的窗口的名称
# 第二个参数是要显示的图像,窗口大小自动调整为图片大小
img=cv.imread('cat.jpg')
# # 等待键盘输入,这样可以让窗口时间维持长点
# cv.waitKey(0)
# cv.destroyAllWindow()销毁所有窗口
# cv.destroyWindow()销毁指定窗口
# cv.imwrite(file,img,num) 保存一张图像
# 第一个参数是要保存的文件名
# 第二个参数是要保存的图像,
# 第三个参数表示压缩级别,默认为3
# cv.copy() 图像复制
# cv.cvtColor() 图像颜色空间转换
# img2=cv.cvtColor(img,cv2.COLOR_RGB2GRAY) 灰度化,彩色转为灰色
# cv.resize(img,img2,dsize) 输入原始图像,输出新图像,图像的大小
# cv.flip(img,0)# 图像翻转:flipcode=0沿x轴翻转,>0沿y轴翻转,<0沿xy同时翻转
# cv.warpAffine(img,M,(400,600)) 图像变换,平移、裁剪、旋转
# cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) →dst
rows,cols,_=img.shape
# 第一个参数是旋转中心,第二个是旋转角度,第三个参数表示缩放系数,1表示维持原图
matrix=cv.getRotationMatrix2D((cols/2,rows/2),90,0.6)
# 需要用另一张图像保存
img1=cv.warpAffine(img,matrix,(cols,rows))
cv.imshow('mywindow',img1)
cv.waitKey(0)
cv.destroyWindow(img1)
太懒了+1
六、PIL库
from PIL import Image
import matplotlib.pyplot as plt
im=Image.open('cat.jpg')
# 创建新图
# img_t=Image.new('RGBA',(256,256))
# 缩放图像
w,h=im.size
im.thumbnail((w//2,h//2))
im.show()
# 图像旋转 im.transpose(Image.ROTATE_180)
# 几何变换
# out=im.resize((128,128))
# out=im.rotate(45) 逆时针旋转45°
# 颜色变换
# im = Image.open('chrome.png').convert("L")
# 模糊效果图片
# im2=im.filter(ImageFilter.BLUR)
# 图片增强
# im3=ImageEnhance.Contrast(im) # 调整对比度
# im3.enhance(1,3).show("30% more contrast")
# 此外还有ImageDraw类创建新的图片,有基本绘图操作
# ImageFont类有矢量字体支持
太懒了+2
七、总结
总的来说,这次对这么多库的基本学习都是基于实验的需要,所以这篇博客所用到的知识仅仅是我在学习时觉得对本人实验有用的,不足之处,还望斧正。