原文链接:http://tecdat.cn/?p=23991
在这个例子中,我们考虑随机波动率模型 SV0 的应用,例如在金融领域。
统计模型
随机波动率模型定义如下
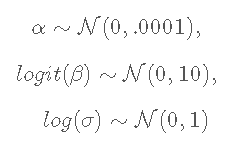
并为![]()

其中 yt 是因变量,xt 是 yt 的未观察到的对数波动率。N(m,σ2) 表示均值 m 和方差 σ2 的正态分布。
αα、β 和 σ 是需要估计的未知参数。
BUGS语言统计模型
文件内容 'sv.bug':
moelfle = 'sv.bug' # BUGS模型文件名
cat(readLies(moelfle ), sep = "\\n")# 随机波动率模型SV_0
# 用于随机波动率模型
var y\[t\_max\], x\[t\_max\], prec\_y\[t\_max\]
model
{
alha ~ dnorm(0,10000)
logteta ~ dnorm(0,.1)
bea <- ilogit(loit_ta)
lg_sima ~ dnorm(0, 1)
sia <- exp(log_sigma)
x\[1\] ~ dnorm(0, 1/sma^2)
pr_y\[1\] <- exp(-x\[1\])
y\[1\] ~ dnorm(0, prec_y\[1\])
for (t in 2:t_max)
{
x\[t\] ~ dnorm(aa + eta*(t-1\]-alha, 1/ia^2)
pr_y\[t\] <- exp(-x\[t\])
y\[t\] ~ dnorm(0, prec_y\[t\])
}设置
设置随机数生成器种子以实现可重复性
set.seed(0)加载模型并加载或模拟数据
sample_data = TRUE # 模拟数据或SP500数据
t_max = 100
if (!sampe_ata) {
# 加载数据 tab = read.csv('SP500.csv')
y = diff(log(rev(tab$ose)))
SP5ate_str = revtab$te\[-1\])
ind = 1:t_max
y = y\[ind\]
SP500\_dae\_r = SP0dae_tr\[ind\]
SP500\_e\_num = as.Date(SP500_dtetr)模型参数
if (!smle_dta) {
dat = list(t_ma=ax, y=y)
} else {
sigrue = .4; alpa_rue = 0; bettrue=.99;
dat = list(t\_mx=\_mx, sigm_tue=simarue,
alpatrue=alhatrue, bet\_tue=e\_true)
}如果模拟数据,编译BUGS模型和样本数据

data = mdl$da()绘制数据

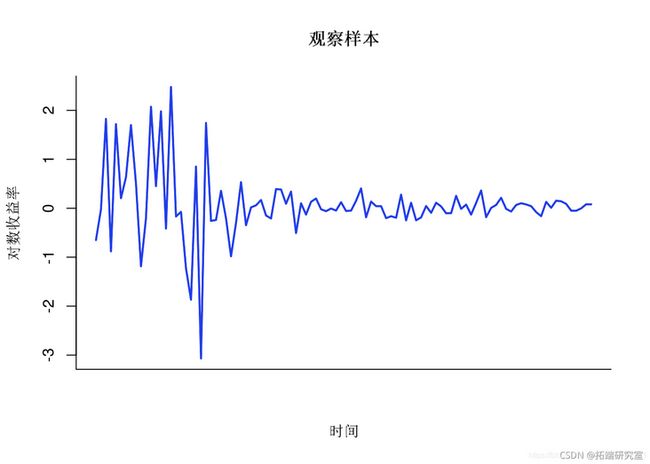
对数收益率
Biips粒子边际Metropolis-Hastings
我们现在运行Biips粒子边际Metropolis-Hastings (Particle Marginal Metropolis-Hastings),以获得参数 α、β 和 σ 以及变量 x 的后验 MCMC 样本。
PMMH的参数
n_brn = 5000 # 预烧/适应迭代的数量
n_ir = 10000 #预烧后的迭代次数
thn = 5 #对MCMC输出进行稀释
n_art = 50 # 用于SMC的nb个粒子
para\_nmes = c('apha', 'loit\_bta', 'logsgma') # 用MCMC更新的变量名称(其他变量用SMC更新)。
latetnams = c('x') # 用SMC更新的、需要监测的变量名称初始化PMMH
![]()
![]()
![]()
运行 PMMH
update(b\_pmh, n\_bun, _rt) #预烧和拟合迭代
samples(oj\_mh, ter, n\_art, thin=hn) # 采样
汇总统计
summary(otmmh, prob=c(.025, .975))计算核密度估计
density(out_mh)参数的后验均值和置信区间
for (k in 1:length(pram_names)) {
suparam = su\_pmm\[\[pam\_as\[k\]\]\]
cat(param$q)
}
参数的MCMC样本的踪迹
if (amldata)
para\_tue = c(lp\_tue, log(dt$bea_rue/(-dta$eatru)), log(smtue))
)
for (k in 1:length(param_aes)) {
smps_pm = tmmh\[\[paranesk\]\]
plot(samlespram\[1,\]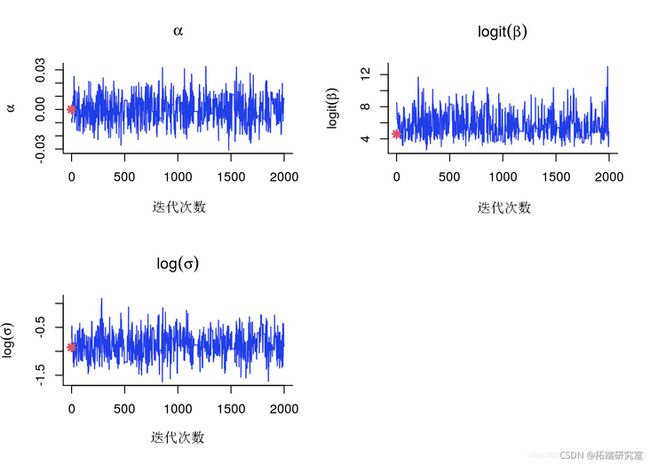
PMMH:跟踪样本参数
参数后验的直方图和 KDE 估计
for (k in 1:length(paramns)) {
samps\_aram = out\_mmh\[\[pramnaes\[k\]\]\]
hist(sple_param)
if (sample_data)
points(parm_true)
}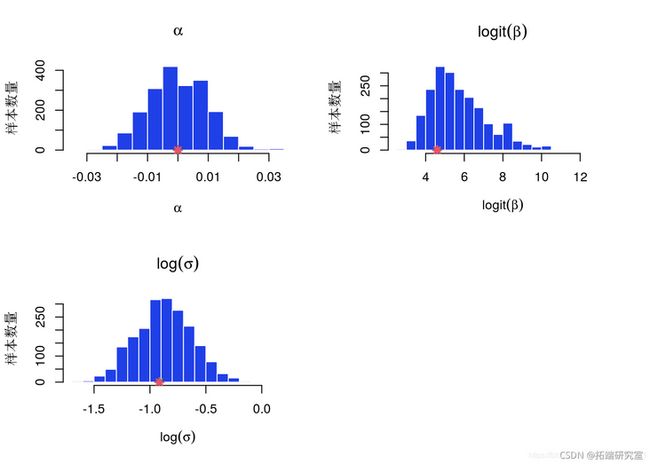
PMMH:直方图后验参数
for (k in 1:length(parm) {
kd\_pram =kde\_mm\[\[paramames\[k\]\]\]
plot(kd_arm, col'blue
if (smpldata)
points(ar_true\[k\])
}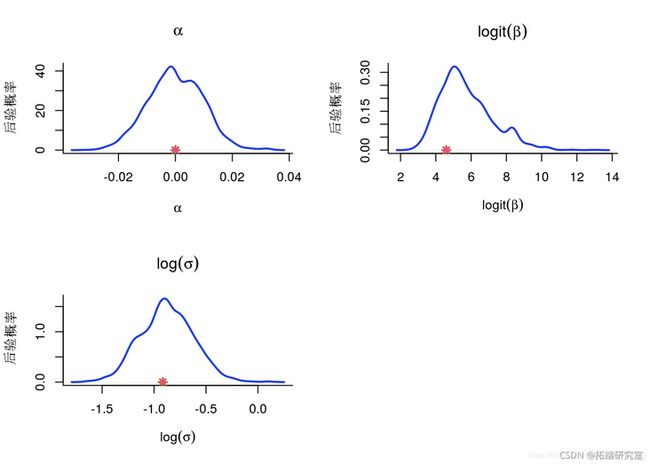
PMMH:KDE 估计后验参数
x 的后均值和分位数
x\_m\_mean = x$mean
x\_p\_quant =x$quant
plot(xx, yy)
polygon(xx, yy)
lines(1:t\_max, x\_p_man)
if (ame_at) {
lines(1:t\_ax, x\_true)
} else
legend(
bt='n)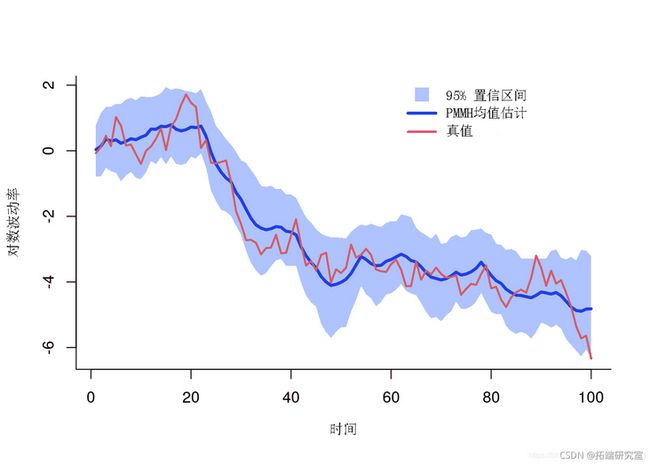
PMMH:后验均值和分位数
x 的 MCMC 样本的踪迹
par(mfrow=c(2,2))
for (k in 1:length) {
tk = ie_inex\[k\]
if (sample_data)
points(0, dtax_t
}
if (sml_aa) {
plot(0
legend('center')
}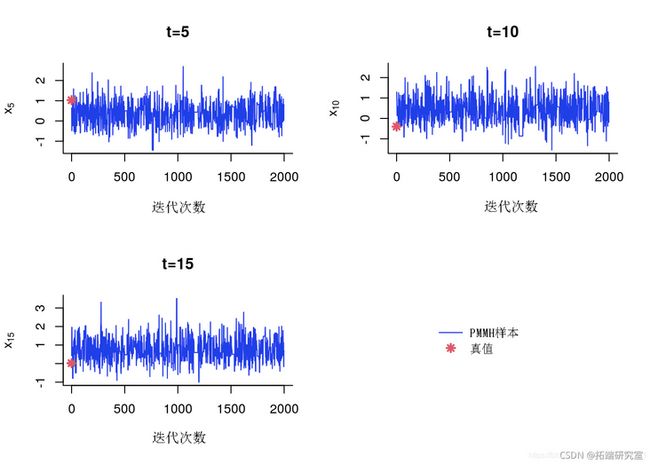
PMMH:跟踪样本 x
x 后验的直方图和核密度估计
par(mfow=c(2,2))
for (k in 1:length(tie_dex)) {
tk = tmnex\[k\]
hist(ot_m$x\[tk,\]
main=aste(t=', t, se='')
if (sample_data)
points(ata$x_re\[t\],
}
if (saml_dta) {
plot(0, type='n', bty='n', x
legend('center
bty='n')
}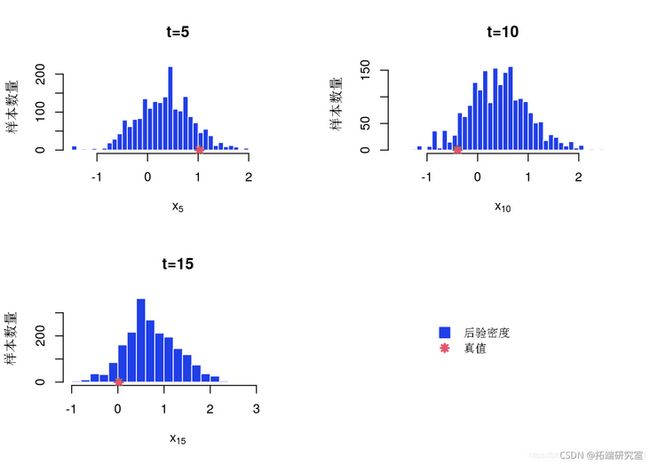
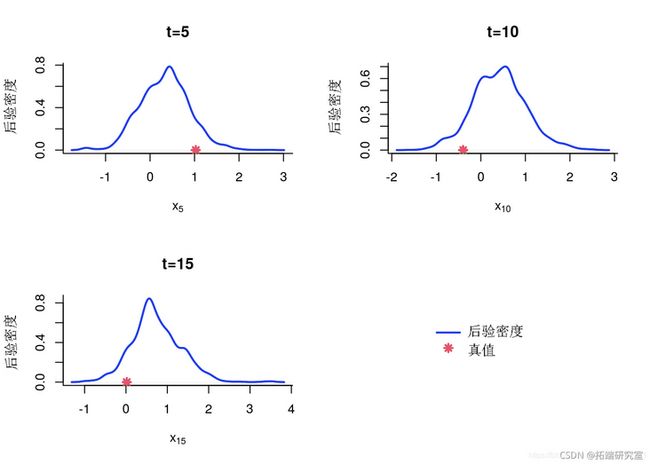
PMMH:后_边际_直方图
par(mfrow=c(2,2))
for (k in 1:length(idx)) {
tk =m_dx\[k\]
plot(kmmk\]\] if (alata)
point(dat_r\[k\], 0)
}
if (aldt) {
plot(0, type='n', bty='n', x, pt.bg=c(4,NA)')
}

最受欢迎的见解
1.R语言对S&P500股票指数进行ARIMA + GARCH交易策略
2.R语言改进的股票配对交易策略分析SPY—TLT组合和中国股市投资组合
3.R语言时间序列:ARIMA GARCH模型的交易策略在外汇市场预测应用