基于python爬虫数据处理_基于Python爬虫的校园数据获取
苏艺航 徐海蛟 何佳蕾 杨振宇 王佳鹏

摘要:随着移动时代的到来,只适配了电脑网页、性能羸弱的校园教务系统,已经不能满足学生们的移动查询需求。为此,设计了一种基于网络爬虫的高实用性查询系統。它首先通过Python爬虫以HTTP(hypertext transport protocol)分析与模拟方法获取校园教务系统的网页数据,然后对网页数据进行HTTP解析并定位以精确抽取目标校园数据,最后存入高速NoSQL数据库以供快速查询。通过课表获取实例,验证了该设计的可行性与有效性。
关键词:网络爬虫;HTTP分析;模拟登陆;网络反爬;Scrapy框架
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)17-0086-03
开放科学(资源服务)标识码(OSID):
Abstract: With the advent of the mobile Internet era, only adapted to PC web pages, the conventional educational administration system with weak performance has been unable to meet the requirement of students mobile access. Therefore, a retrieval system with strong practicability is developed, which is based on Web crawler. First, through a python crawler, the HTTP (HyperText Transport Protocol) parsing and simulation login are leveraged to fetch the content of Web pages in an educational administration system. Then, the page content is parsed and the target campus data is precisely extracted. Finally, the campus data is persisted in a high-speed NoSQL database for fast query service. By design a case of curriculum timetable acquisition, the feasibility and validity of the proposed approach is demonstrated.
Key words: web crawler; HTTP parsing; simulation login; anti-web crawler; scrapy framework
1 背景
移动互联网时代下,传统B/S架构的校园教务系统向移动智能终端延伸势在必行。为满足同学们日常的教务查询需求,实现一个高实用性的第三方移动查询平台是一个亟须的解决方案。网络爬虫技术为实现这种校园数据查询系统提供了技术基础。
网络爬虫是一类会按照一定的规则,自动地从互联网中获取信息的程序或脚本。按照系统结构和实现技术,可主要分为以下四种:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫[1],实际的爬虫系统通常会将上述几种技术搭配结合使用。对于聚焦网络爬虫,它是对网页进行有目的性的爬取,而与目标无关的网页和数据会被过滤掉,因此可使用聚焦网络爬虫技术实现校园数据的查询获取。
2 爬虫设计思路
设计爬虫程序的通常步骤为:爬取目标确定、HTTP请求分析与模拟、数据解析与定位、数据逻辑处理、数据高速储存[2]。遵循该五步骤设计法,设计思路分述如下。
2.1 爬取目标确定
本步骤为开发爬虫程序的首要步骤。相对于其他类型爬虫,爬取目标的描述或定义对聚焦网络爬虫来说至关重要。爬取目标的描述和定义是确定如何制定网页分析算法和网址搜索策略的基础。聚焦爬虫的工作流程较为复杂,只有清晰地制定好爬取规则,才能更合理地设计和开发出网络爬虫程序。
2.2 HTTP请求分析与模拟
实现HTTP请求[3],首先要实现一个支持HTTP各种请求方法(如GET、POST)的请求报文与相应的模型。然后还需要合理处理每个请求的请求头。有时会出现即使请求数据是正确的,但仍被服务器拒绝访问的情况。这是因为服务器会校验请求头,并对非正常的请求拒绝服务或弹出验证码等措施,这也是最常见的反爬虫[4]手段。另外还需注意部分爬虫需要保存Cookie信息,这是因为HTTP协议是无状态的,用户的登录信息等会被保存到浏览器Cookie中。查询系统需要对Cookie进行适当管理,以实现模拟浏览器请求。最后,在完备的查询系统中,还需处理异常,如请求超时、非2XX响应码的响应、请求重定向等。在网络爬虫实现上,可使用Python3[5]内置的网络模块urllib来实现,也可使用更人性化的第三方网络模块:Requests库。
2.3 数据解析与定位
数据解析目的是将已下载响应网页中的目标数据提取出来并解析成基本数据类型。通常,响应网页文本类型为:HTML、XML和JSON,其中HTML文档最常见。对于HTML和XML类型的文档来说,最常见的数据解析方法是先将文档转换成树形结构对象,然后通过XPath语法来提取相应数据。如果是HTML文档,还可使用CSS选择器语法来定位相关节点。在Python爬虫开发中,常用解析工具包是Beautiful Soup(bs4)库。而JSON文档则是最容易处理的,可使用Python的JSON内置库来将其反序列化成dict类型,于是就可以方便地提取其数据了。另外,可使用正则表达式来捕获一些含有一定应用语义规则的字符串。Python中re内置库提供了通过正则表达式捕获所需目标字符串的功能,这加速了开发过程。
2.4 数据清洗与逻辑处理
这个处理步骤是将解析出来的原始HTML数据按照一定规则清洗、转换成便于存储或后续进行数据分析的数据。这一逻辑处理步骤与應用相关,不是必需的,或者说这一步骤多数不在网络爬虫程序中完成。
2.5 数据高速储存
数据高速储存是指将爬虫程序获取到的校园应用数据持久化存储到磁盘中,这是爬虫程序中数据的终点。一个通常的解决方案是:将解析好的目标数据写入到数据库或者将目标数据序列化成JSON或XML文档写入磁盘文件中。被持久化的校园数据,可提供给快速查询服务而无须访问校园教务系统。
在移动互联网时代与Web 3.0[6]时代下,选择什么类型的数据库对基于Python爬虫的查询系统性能较重要。传统的关系型数据库系统如MySQL以完善的关系代数理论作为基础,支持事务ACID特性,借助索引机制可实现高效的查询,但是可扩展性较差,无法较好支持海量数据存储、Web 2.0/3.0应用。新型的NoSQL数据库系统[7]如MongoDB可支持超大规模数据存储,较好支持高并发低延时的Web 2.0/3.0应用,但是缺乏数学理论基础,复杂查询性能不高,很难实现数据完整性约束。
3 爬虫开发过程—以课表获取为例
以我校教务系统课表查询为例,讲述基于Scrapy[8]异步爬虫框架下的开发过程,重点给出爬虫实现过程中的关键设计思想和核心代码。
3.1 HTTP模拟登录
获取课表网页需要验证校园教务系统登录,拟采用模拟登录技术。当模拟登录时,在每一次HTTP请求中保存用户Cookie数据,Scrapy已提供相关处理函数。此外,模拟登录还涉及请求头处理、验证码输入、隐藏表单字段输入、页面跳转与重定向等四个关键步骤。
3.1.1 请求头处理
如图1所示,修改Scrapy项目中的settings.py文件,以设置请求头Headers。通过设置请求头,可防止服务器拒绝模拟登录发出的HTTP请求。
3.1.2 验证码输入
我校教务系统无须输入验证码登录,因此在实验中无须处理验证码。对于传统的验证码输入,可使用谷歌Tesseract-OCR库来识别;而对于最近较流行的滑动验证码输入,可使用浏览器自动化框架Selenium来模拟鼠标在浏览器上的拖动操作,以此通过验证。
3.1.3 隐藏表单字段输入
通过使用Chrome浏览器的开发者工具,抓取到模拟登录过程中关键的HTTP POST请求,发现其中有两个非账号非密码的必填表单字段,在每次请求时都会变化,如图2所示。通过查看HTTP响应的HTML文档,发现这是两个隐藏的input标签中的值:tokens和stamp。对于这种隐藏字段,可请求一次登录页面,然后使用正则表达式来将其捕获。
3.1.4 页面跳转与重定向
当提交了HTTP POST请求后,所得到的响应页面会包含一个重定向网址URL。使用该URL重发一次HTTP GET请求,就可获取登录相关的用户Cookie数据,并且会被重定向到我校教务系统的主页。图3给出了模拟登录代码,它首先获取储存在数据库中的校园网账号,然后保存用户Cookie数据并把登录账号传递给回调函数,之后使用正则表达式捕获模拟登录页面中的隐藏字段数据,最后使用正则表达式捕获需要跳转的教务系统URL以完成模拟登录。
3.2 目标页面获取
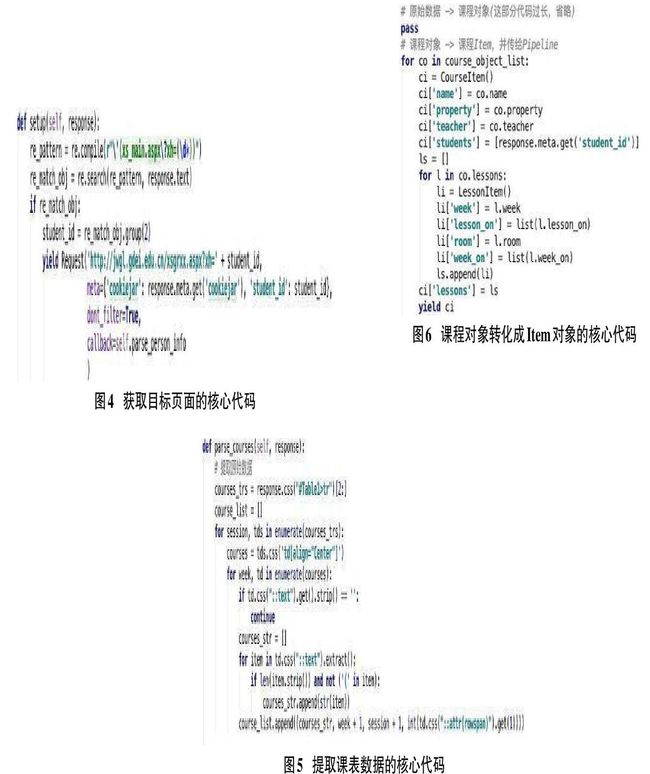
完成模拟登录后,就可成功获取课表页面了。在这个步骤中,仅需生成一个相应的Python Request对象,并把解析页面数据的函数作为回调函数即可。相应代码如图4所示。
3.3 页面数据解析
为解析并获取目标课表数据,首先检视课表网页,然后使用HTML代码工具分析目标数据的位置,最后使用CSS选择器定位目标数据:整个课表数据在id为Table1的table标签中。其中前两个tr标签的内容为课程表表头,可将其抛弃。此外,检视含课程信息的td标签,发现它们都含有值为Center的align属性。据此,可通过程序精确提取目标课表数据。图5为提取课表数据的核心代码。
3.4 课表数据储存
在查询实验中,选择MongoDB这种基于分布式存储的高速NoSQL数据库来储存课表数据。其主要考虑是:1)许多校园数据获取应用如查课选课,易产生课表查询的高并发瞬时峰值,而MongoDB数据库可支持大规模数据存储并较好支持高并发低延时Web查询;2)通用校园数据获取应用的复杂度不高,对数据完整性约束要求不强,适于MongoDB这种新型的NoSQL数据库系统。
图6演示了将处理完的课程数据对象转化成Item对象的代码。然后,按照Python Scrapy处理框架约定,传递Item对象给类Pipeline处理。在Pipeline类中的process_item()方法中,编写Item插入MongoDB数据库的语句即可完成数据持久化以供快速查询。
4 结束语
为改善传统校园教务系统的查询性能,设计了一种基于Python爬虫技术的校园数据查询系统,较好解决了快速、移动访问的校园数据获取问题。文中以课表数据获取为实例,讲解了爬虫程序的设计与实现。类似地,还可开发课程成绩获取、校园卡消费记录获取以及图书借阅信息获取等网络爬虫,以实现多功能校园数据查询系统。
参考文献:
[1] 潘巧智, 张磊. 浅谈大数据环境下基于python的网络爬虫技术[J]. 网络安全技术与应用, 2018(5): 41-42.
[2] 魏程程. 基于Python的数据信息爬虫技术[J]. 电子世界, 2018(11): 208-209.
[3] 路辉, 高尚飞, 李少龙. 基于HTTP协议的业务系统网页数据采集应用集成[J]. 电子技术与软件工程, 2019(2): 1-3.
[4] 刘洋. 基于网页浏览行为的反爬虫研究[J]. 现代计算机: 专业版, 2019(7): 58-60.
[5] 吴剑冰. 基于Python3爬虫获取最新上架图书的实现[J]. 电脑编程技巧与维护, 2018(4): 31-33.
[6] 刘鹏. Web3.0环境下的数据库设计及程序开发[J]. 信息与电脑: 理论版, 2018(3): 124-126.
[7] 宋俊苏. 大数据环境下基于NoSQL数据库的查询技术研究与应用[J]. 电脑编程技巧与维护, 2019(2): 76-77.
[8] 韩贝, 马明栋, 王得玉. 基于Scrapy框架的爬虫和反爬虫研究[J]. 计算机技术与发展, 2019(2): 139-142.
【通联编辑:谢媛媛】