[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(下)
这是本文的最后一部分内容了,前两部分内容的文章:
- [GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(上)
- [GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)
以及原文的地址:
http://bamos.github.io/2016/08/09/deep-completion/
最后一部分的目录如下:
- 第三步:为图像修复寻找最佳的假图片
- 利用 DCGANs 实现图像修复
- [ML-Heavy] 损失函数
- [ML-Heavy] TensorFlow 实现 DCGANs 模型来实现图像修复
- 修复你的图片
第三步:为图像修复寻找最佳的假图片
利用 DCGANs 实现图像修复
在第二步中,我们定义并训练了判别器D(x)和生成器G(z),那接下来就是如何利用DCGAN网络模型来完成图片的修复工作了。
在这部分,作者会参考论文"Semantic Image Inpainting with Perceptual and Contextual Losses" 提出的方法。
对于部分图片y,对于缺失的像素部分采用最大化D(y)这种看起来合理的做法并不成功,它会导致生成一些既不属于真实数据分布,也属于生成数据分布的像素值。如下图所示,我们需要一种合理的将y映射到生成数据分布上。
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(下)_第1张图片](http://img.e-com-net.com/image/info8/ea2e398270634377bfc2a8fdd935d885.jpg)
[ML-Heavy] 损失函数
首先我们先定义几个符号来用于图像修复。用M表示一个二值的掩码(Mask),即只有 0 或者是 1 的数值。其中 1 数值表示图片中要保留的部分,而 0 表示图片中需要修复的区域。定义好这个 Mask 后,接下来就是定义如何通过给定一个 Mask 来修复一张图片y,具体的方法就是让y和M的像素对应相乘,这种两个矩阵对应像素的方法叫做哈大马乘积,并且表示为 M ⊙ y ,它们的乘积结果会得到图片中原始部分,如下图所示:
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(下)_第2张图片](http://img.e-com-net.com/image/info8/ac6f58ba3371428b9e54bb34076cf8eb.jpg)
接下来,假设我们从生成器G的生成结果找到一张图片,如下图公式所示,第二项表示的是DCGAN生成的修复部分:
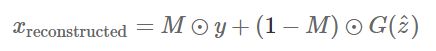
根据上述公式,我们知道最重要的就是第二项生成部分,也就是需要实现很好修复图片缺失区域的做法。为了实现这个目的,这就需要回顾在第一步提出的两个重要的信息,上下文和感知信息。而这两个信息的获取主要是通过损失函数来实现。损失函数越小,表示生成的G(z)越适合待修复的区域。
Contextual Loss
为了保证输入图片相同的上下文信息,需要让输入图片y(可以理解为标签)中已知的像素和对应在G(z)中的像素尽可能相似,因此需要对产生不相似像素的G(z)做出惩罚。该损失函数如下所示,采用的是 L1 正则化方法:
![]()
这里还可以选择采用 L2 正则化方法,但论文中通过实验证明了 L1 正则化的效果更好。
理想的情况是y和G(z)的所有像素值都是相同的,也就是说它们是完全相同的图片,这也就让上述损失函数值为0
Perceptual Loss
为了让修复后的图片看起来非常逼真,我们需要让判别器D具备正确分辨出真实图片的能力。对应的损失函数如下所示:
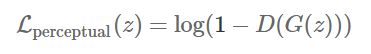
因此,最终的损失函数如下所示:
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(下)_第3张图片](http://img.e-com-net.com/image/info8/6bf65748d27e4c37a9e7e75940810fc2.jpg)
这里 λ 是一个超参数,用于控制两个函数的各自重要性。
另外,论文还采用泊松混合(poisson blending) 方法来平滑重构后的图片。
[ML-Heavy] TensorFlow 实现 DCGANs 模型来实现图像修复
代码实现的项目地址如下:
https://github.com/bamos/dcgan-completion.tensorflow
首先需要新添加的变量是表示用于修复的 mask,如下所示,其大小和输入图片一样
self.mask = tf.placeholder(tf.float32, [None] + self.image_shape, name='mask')
对于最小化损失函数的方法是采用常用的梯度下降方法,而在 TensorFlow 中已经实现了自动微分的方法,因此只需要添加待实现的损失函数代码即可。添加的代码如下所示:
self.contextual_loss = tf.reduce_sum(
tf.contrib.layers.flatten(
tf.abs(tf.mul(self.mask, self.G) - tf.mul(self.mask, self.images))), 1)
self.perceptual_loss = self.g_loss
self.complete_loss = self.contextual_loss + self.lam*self.perceptual_loss
self.grad_complete_loss = tf.gradients(self.complete_loss, self.z)
接着,就是定义一个 mask。这里作者实现的是位置在图片中心部分的 mask,可以根据需求来添加需要的任意随机位置的 mask,实际上代码中实现了多种 mask
if config.maskType == 'center':
scale = 0.25
assert(scale <= 0.5)
mask = np.ones(self.image_shape)
l = int(self.image_size*scale)
u = int(self.image_size*(1.0-scale))
mask[l:u, l:u, :] = 0.0
因为采用梯度下降,所以采用一个 mini-batch 的带有动量的映射梯度下降方法,将z映射到[-1,1]的范围。代码如下:
for idx in xrange(0, batch_idxs):
batch_images = ...
batch_mask = np.resize(mask, [self.batch_size] + self.image_shape)
zhats = np.random.uniform(-1, 1, size=(self.batch_size, self.z_dim))
v = 0
for i in xrange(config.nIter):
fd = {
self.z: zhats,
self.mask: batch_mask,
self.images: batch_images,
}
run = [self.complete_loss, self.grad_complete_loss, self.G]
loss, g, G_imgs = self.sess.run(run, feed_dict=fd)
# 映射梯度下降方法
v_prev = np.copy(v)
v = config.momentum*v - config.lr*g[0]
zhats += -config.momentum * v_prev + (1+config.momentum)*v
zhats = np.clip(zhats, -1, 1)
修复你的图片
选择需要进行修复的图片,并放在文件夹dcgan-completion.tensorflow/your-test-data/raw下面,然后根据之前第二步的做法来对人脸图片进行对齐操作,然后将操作后的图片放到文件夹dcgan-completion.tensorflow/your-test-data/aligned。作者随机从数据集LFW中挑选图片进行测试,并且保证其DCGAN模型的训练集没有包含LFW中的人脸图片。
接着可以运行下列命令来进行修复工作了:
./complete.py ./data/your-test-data/aligned/* --outDir outputImages
上面的代码会将修复图片结果保存在--outDir参数设置的输出文件夹下,接着可以采用ImageMagick工具来生成动图。这里因为动图太大,就只展示修复后的结果图片:
而原始的输入待修复图片如下:
小结
最后,再给出前两步的文章链接:
- [GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(上)
- [GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)
当然这个图片修复方法由于也是2016年提出的方法了,所以效果不算特别好,这两年其实已经新出了好多篇新的图片修复方法的论文,比如:
-
2016CVPR Context encoders: Feature learning by inpainting
-
Deepfill 2018–Generative Image Inpainting with Contextual Attention
-
Deepfillv2–Free-Form Image Inpainting with Gated Convolution
-
2017CVPR–High-resolution image inpainting using multi-scale neural patch synthesis
-
2018年的 NIPrus收录论文–Image Inpainting via Generative Multi-column Convolutional Neural Networks
欢迎关注我的微信公众号–机器学习与计算机视觉,或者扫描下方的二维码,在后台留言,和我分享你的建议和看法,指正文章中可能存在的错误,大家一起交流,学习和进步!
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(下)_第4张图片](http://img.e-com-net.com/image/info8/cc37be827829464aa6654d6f286f14f0.jpg)
我的个人博客:
http://ccc013.github.io/
往期精彩推荐
1.机器学习入门系列(1)–机器学习概览(上)
2.机器学习入门系列(2)–机器学习概览(下)
3.[GAN学习系列] 初识GAN
4.[GAN学习系列2] GAN的起源
5.[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(上)
6.[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)