onnx 模型转换与 onnxruntime 和caffe2 推理速度比较
onnx 模型转换与 onnxruntime 和caffe2 推理速度比较
-
- 背景
- 1、模型转换
- 2、PC端运行onnx模型
背景
pytorch 模型通常包括网络结构.py文件和模型参数文件.pth,通常需要转换为onnx格式再向其他终端或移动端部署(onnx模型一般用于中间部署阶段,相当于翻译的作用)。移动端通常使用ncnn、mnn、Caffe2进行inference,实现实时计算。
本文展示pytorch转onnx的模型在PC端 以CPU方式运行。
1、模型转换
1.1. pytorch 模型转onnx 模型
def torch2onnx(model, save_path):
"""
:param model:
:param save_path: XXX/XXX.onnx
:return:
"""
model.eval()
data = torch.rand(1, 3, 48, 64)
input_names = ["input"]
output_names = ["cls","lmk"]
torch.onnx._export(model, data, save_path, export_params=True, opset_version=11, input_names=input_names, output_names=output_names)
print("torch2onnx finish.")
在实际使用过程中我们希望inference时支持batch=2的操作,比如左右眼分类。
可以修改
data = torch.rand(2, 3, 48, 64)
这样在onnx 模型inference时必须要输入两张图,运行时间理论上应该能比单张图输入稍快点。以下模型推理均按batch=2实验.
1.2. onnx 模型简化
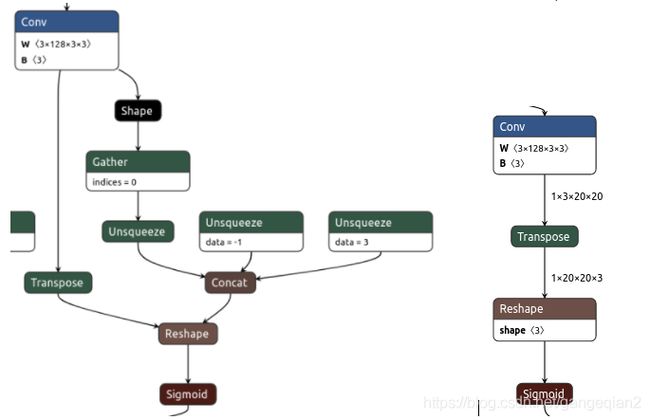
onnx 模型简化是可以理解为,根据输入图像尺寸对pytorch动态图中动态变化的量进行固定,比如Gather取tensor维度、unsqueeze/squeeze、shape等算子,其参数与数据流尺寸相关,当输入图像尺寸固定后,相关参数可以转换为constant 值。左图是原始onnx模型图,右侧是简化后的图。可以看到图中数据流尺寸已经很具体,且相关的shape,取维度操作均被干掉了。
 安装:
安装:
pip install onnx-simplifier
默认安装最新版,也可以指定版本,因为某些情况下依赖库版本不匹配
pip install onnx-simplifier==0.2.18
使用:
在pytorch 转换为onnx模型之后,执行:
python -m onnxsim ${
model} ${
model}
如果需要在python中调用,执行:
import subprocess
subprocess.call('python -m onnxsim {} {}'.formal(out_model_name,out_model_name) , shell=True)
2、PC端运行onnx模型
2.1.预处理
加载图像和预处理:
import cv2
import numpy as np
img=cv2.imread("test.png")
img=cv2.resize(img,(224,224),interpolation=cv2.INTER_AREA)
img2=img.copy().astype(np.float32)
img2=(img2/255-0.5)/0.5 # 归一化
img_array=np.expand_dims(img2.transpose((2,0,1)),axis=0) #BGR->RGB
img_array=img_array.repeat(2,axis=0) #2 batch data in
当然,对于pytorch 也可以写成:
import torchvision.transforms as transforms
img = cv2.imread('test.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
tensor = transforms.ToTensor()(img)
tensor = transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))(tensor)
tensor = tensor.unsqueeze_(0)
img_array=tensor.cpu().numpy()
2.2.onnxruntime 运行导出的模型
可参考:帮助文档
安装:
pip install onnxruntime
pip install onnxruntime-gpu
使用:
import onnxruntime
session=onnxruntime.InferenceSession('out.onnx')
input={
"input.1":img_array.astype(np.float32)}
output=session.run(None,input)
运行10次:

平均运行时间>550ms
2.3.caffe2 运行导出的模型
import onnx
import caffe2.python.onnx.backend
modelFile=onnx.load('out.onnx')
有两种写法:
- run_model 加载并运行模型
output=caffe2.python.onnx.backend.run_model( modelFile, img_array.astype(np.float32))
运行10次:

平均时间>130ms
- 先加载模型后运行
prepared_backend=caffe2.python.onnx.backend.prepare(modelFile)
W={
modelFile.graph.input[0].name:img_array.astype(np.float32)}
output=prepared_backend.run(W)
运行10次:

平均时间约11ms 左右,可见加载模型占了较长的时间。
2.4.总结:
onnx 模型在caffe2 CPU上运行时间远小于onnxruntime的方式。
此外还有Tensorflow 运行导出的模型等方式,可参见:Tensorflow 运行onnx
在移动端使用caffe2 可参考:移动端部署caffe2