Python 内置模块 持久化
一.序列化(pickling):把对象(变量)从内存中变成可存储或传输的过程
- 在其他语言中也被称之为serialization,marshalling,flattening等等
- 把变量内容从序列化的对象读到内存称为反序列化(unpickling)
要在不同的编程语言间传递对象,就必须把对象序列化为标准格式(如XML);但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储或传输;并且JSON比XML更快,而且可以直接在Web页面中读取
二.json(JavaScript Object Notation)模块:可以进行任何语言间数据交换,数据可读
JSON字符串:可以被所有语言识别
其中只能使用双引号,字符串本身用’ ‘/" "扩起(不可见)
原本为字符串则先转换,再用’ '/" "扩起
JSON表示的对象就是标准的JavaScript语言的对象
JSON和Python内置的数据类型对应如下:
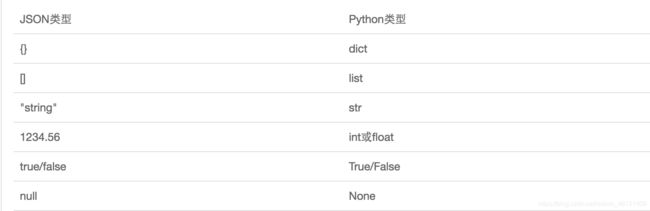
{
'name':'alex'}--->{
"name":"alex"}--->'{"name":"alex"}'
8--->'8'
'hello'--->"hello"--->' "hello" '
[11,22]--->"[11,22]"
json.loads(x):将一个字符串转成python对象(不支持类变量)
对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值
import json
x="[null,true,false,1]"
print(eval(x))
print(json.loads(x))

json.dumps(data):转换成json字符串
import json
data=json.dumps(["as",12,'1d'])
print(data) #'["as",12,"1d"]'
json.dump(data,file)与json.load(file)
import json
dic={
'name':'alvin','age':23,'sex':'male'}
print(type(dic))#
import json
f=open('序列化对象')
i=f.read() #|3
data=json.loads(i) #|4 data=json.load(f)等价于3,4两行
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
dct='{"1":"111"}'
print(json.loads(dct))
- 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads


三.pickle模块:用法与json模块相似,数据不可读(显示乱码),支持普通变量/函数变量/类变量
参见:https://www.cnblogs.com/baby-lily/p/10990026.html
- 只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系
#要序列化对象层次结构,只需调用该dumps()即可
#同样,要对数据流进行反序列化,调用该loads()即可
#但是,如果想要更多地控制序列化和反序列化,则可以分别创建一个Pickler/一个Unpickler对象
#pickle模块提供以下常量:
pickle.HIGHEST_PROTOCOL
#整数,可用的最高协议版本
pickle.DEFAULT_PROTOCOL
#整数,用于编码的默认协议版本
#可能不到HIGHEST_PROTOCOL
#目前,默认协议是3;这是为Python3设计的新协议。
import pickle
dic={
'name':'alvin','age':23,'sex':'male'}
print(type(dic))#四.shelve模块:支持数据类型有限
shelve.open(r"filename")(filename可任意)
返回类似字典的对象,可读可写
存储的键值对中key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open(r'shelve.txt')
#获得一个类字典句柄f,对f进行类字典操作
f['stu1_info']={
'name':'alex','age':'18'}
f['stu2_info']={
'name':'alvin','age':'20'}
f['school_info']={
'website':'oldboyedu.com','city':'beijing'} #存储了3个键值对
f.close()
print(f.get('stu_info')['age']) #18
五.XML模块:实现不同语言或程序之间进行数据交换的协议,跟json相似,但json使用起来更简单
1.XML文件:通过"<>节点"区别数据结构,使用"标签语言"
格式如下:
<?xml version="1.0"?> #版本声明
<data> #标签,两个间数据属于data #根节点,目前无属性
<country name="Liechtenstein"> #标签,两个间数据属于Lie
<rank updated="yes">2</rank> #内容(text)为2
<year>2008</year> #内容(text)为2008
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/> #n.n.为标签名,有2个属性
<neighbor name="Switzerland" direction="W"/> #另一个标签及其属性
</country>
<country name="Singapore"> #标签名为country,name=S是一个属性
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/> #该标签无内容(text)
</country>
<country name="Panama"> #子节点对象
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data> #以上为一个文档树
2.标签:
- 自闭和标签(如< country name=“Panama”>)
- 非闭合标签(如< gdppc>13600< /gdppc>)
3.操作XML:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml") #解析xml文件(相当于读取)---内容为上方代码
root = tree.getroot() #获得根节点对象---可以调用方法/属性
print(root.tag) #data #根节点对象的标签名
#遍历xml文档
for child in root:
print(child,child.tag, child.attrib)
#可以获得内存地址,指向的一定是对象
#获得3个子节点对象的内存地址,名字,属性构成的字典
for i in child:
print(i,i.tag,i.text) #获得对象的内存地址,名字,内容
#只遍历year 节点
for node in root.iter('year'):
#root.iter("x"=none)得到一个生成器对象,包括root下所有元素;再筛选出x,不填则为所有
print(node.tag,node.text) #获得所有year标签名字,内容
new_year=int(node.text=str)+1
node.text=str(new_year) #修改所有year标签内容
node.set("updated","yes") #修改所有year标签属性(增加updated="yes")
#以上修改在内存发生,未写入原文件
#写入修改
tree.write("xmltest.xml") #直接覆盖
#删除node
for country in root.findall('country'): #获得root下所有country标签
rank = int(country.find('rank').text) #获得country下rank标签,再获得其内容
if rank > 50:
root.remove(country)
findall可找多个,find只能找一个
tree.write('output.xml')
4.创建XML文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
#创建新文件new_xml,创建根节点标签并添加属性enrolled="yes"
age = ET.SubElement(name,"age",attrib={
"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33' #给sex标签赋值
name2 = ET.SubElement(new_xml,"name",attrib={
"enrolled":"no"})
#在new_xml中再创建一个标签并添加属性
age = ET.SubElement(name2,"age")
age.text = '19'
#创建结果new_xml:
<namelist>
<name enrolled="yes">
<age checked="no"/>
<sex>33</sex>
</name>
<name enrolled="no">
<age>19</age>
</name>
</namelist>
et = ET.ElementTree(new_xml)
#生成文档树
et.write("test.xml", encoding="utf-8",xml_declaration=True)
#写入
ET.dump(new_xml) #打印生成的格式
六.struct模块
参考:https://www.cnblogs.com/coser/archive/2011/12/17/2291160.html
1.pack():把一个类型,如数字,转成固定长度的bytes
struct.pack(fmt,n)
#fmt指定要转换的数据类型
#n指定要转换的数据
#'i' format requires -2147483648 <= n <= 2147483647
struct.pack('i',111)
#结果:b'o\x00\x00\x00'
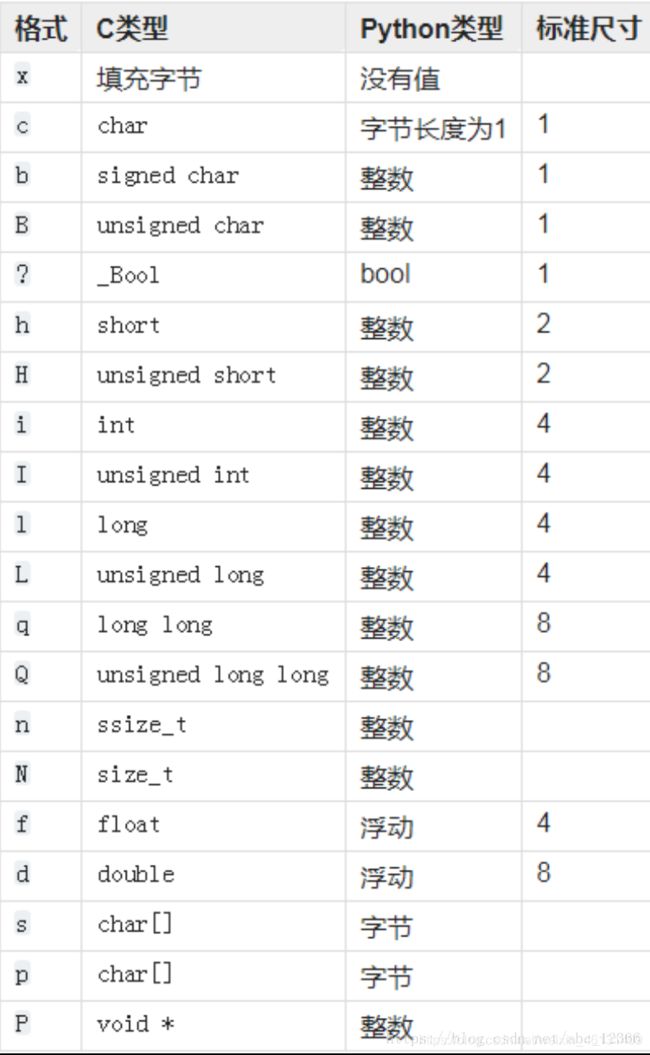
2.unpack():读取已有的二进制数据
struct.unpack(fmt,l)
#返回解压出的数据构成的元组
#fmt指定读取出出的数据的格式;l指定要读取的数据
l=struct.pack('i',123123)
struct.unpack('i',l)
#(123123,)
3.struct的详细用法
#_*_coding:utf-8_*_
#http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html
__author__ = 'Linhaifeng'
import struct
import binascii
import ctypes
values1 = (1, 'abc'.encode('utf-8'), 2.7)
values2 = ('defg'.encode('utf-8'),101)
s1 = struct.Struct('I3sf')
s2 = struct.Struct('4sI')
print(s1.size,s2.size)
prebuffer=ctypes.create_string_buffer(s1.size+s2.size)
print('Before : ',binascii.hexlify(prebuffer))
# t=binascii.hexlify('asdfaf'.encode('utf-8'))
# print(t)
s1.pack_into(prebuffer,0,*values1)
s2.pack_into(prebuffer,s1.size,*values2)
print('After pack',binascii.hexlify(prebuffer))
print(s1.unpack_from(prebuffer,0))
print(s2.unpack_from(prebuffer,s1.size))
s3=struct.Struct('ii')
s3.pack_into(prebuffer,0,123,123)
print('After pack',binascii.hexlify(prebuffer))
print(s3.unpack_from(prebuffer,0))