pytorch加载模型遇到问题ModuleNotFoundError: No module named ‘models‘
Pytorch保存和加载模型
- 模型的保存和加载
-
- 1. 只保存模型状态state_dict
-
- * 训练中断时
- 2. 保存整个模型并加载(包含参数和网络)
- 问题
- 原因
- 解决
-
- 1. 尝试转换模型
- 2. 使用第一种方法保存模型状态
模型的保存和加载
Pytorch保存和加载模型主要有两种方式:
1. 只保存模型状态state_dict
保存:
torch.save(model.state_dict(),"model.pth")
加载:
model.load_state_dict(torch.load("model.pth"))
model.eval()
该方法仅需要保存训练后的模型学习参数。使用torch.save()函数保存模型的state_dict将提供最大的灵活性,以便以后恢复模型,推荐使用此方法来保存模型。常见的PyTorch文件格式是使用.pt或.pth文件扩展名保存模型。
注意:
- a. 必须调用model.eval(),以便在推理之前将dropout和batch层设置为评估模式。如果不这样做,将会产生不一致的推理结果。
- b. 在使用load_state_dict()函数加载模型时使用字典对象,而不是保存的路径。这意味着,在将保存的state_dict传递给
load_state_dict()函数之前,必须使用torch.load()对其进行反序列化,无法使用model.load_state_dict(PATH)
* 训练中断时
有时候可能由于其他原因模型训练过程中被中断了,这时候就需要保存模型的状态,从终止状态进行训练。
定义模型的状态并保存:
state={
'model':model.state_dict(),'optimizer':optimizer.state_dict(),'epoch':epoch}
torch.save(state,path)
加载继续训练:
checkpoint=torch.load(path)
model.load_state_dict(checkpoint('model'))
optimizer.load_state_dict(checkpoint['optimizer'])
epoch=checkpoint['epoch']
2. 保存整个模型并加载(包含参数和网络)
保存:
torch.save(model,"whole_model.pth")
加载:
model=torch.load("whole_model.pth")
model.eval()
这种保存/加载过程使用最直观的语法,并且涉及最少的代码。但以这种方式保存模型将使用Python的pickle模块保存整个模块。这种方法的缺点使序列化的数据保存到特定的类,并且在保存模型时使用确切的目录结构。这样做的原因是因为pickle不会保存模型类本身,而是将其保存到包含类的文件的路径,该路径在加载时使用。因此,在其他项目中使用或重构后,代码可能会以各种方式中断。
问题
File "load_model.py", line 9, in load_model
ckpt = torch.load(weights, map_location=device)
File "/usr/local/python378/lib/python3.7/site-packages/torch/serialization.py", line 594, in load
return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
File "/usr/local/python378/lib/python3.7/site-packages/torch/serialization.py", line 853, in _load
result = unpickler.load()
ModuleNotFoundError: No module named 'models'
原因
训练时采用第二种方式保存整个模型以便于在其他地方调用测试,而该方式保存模型会使序列化的数据保存到特定的类,并且依赖该类文件的特定的目录结构,该路径在加载时使用。因此,在上面项目中调用其他地方保存的模型时由于缺少models路径而找不到models模块。
使用Netron打开保存的整个网络:
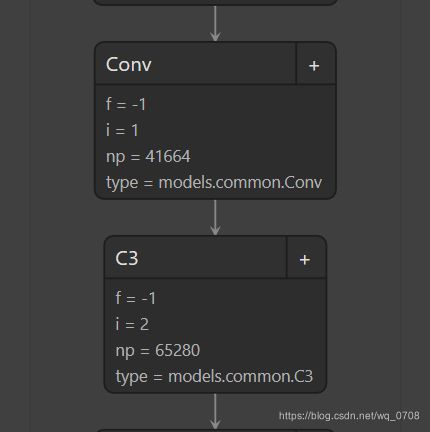
上图截取的一部分显示网络层的type是带有目录结构models.common的类型,如果加载时目录变了就会导致无法正常导入。
解决
参考github相关解答
1. 尝试转换模型
def convert_model(model, input=torch.tensor(torch.rand(size=(1,3,112,112)))):
model = torch.jit.trace(self.model, input)
torch.jit.save(model,'/home/projects/models/model.tjm')
然后加载模型:
# load the model
self.model = torch.jit.load('/home/projects/models/model.tjm')
2. 使用第一种方法保存模型状态
self.model = checkpoint['model'].module
# create the new checkpoint based on what you need
torch.save({
'state_dict' : self.model.state_dict(), 'use_se':True},
'/home/projects/models/best_checkpoint.pth')