「重学Java集合」HashMap全面解析
Java集合:HashMap全面解析
参考学习
- 此处膜拜大佬,五体投地
- https://blog.csdn.net/carson_ho/article/details/79373026
写在前面
本文是对于HashMap类的源码分析学习 : ),完全属于个人对于知识点的整理,其中HashMap在jdk1.7和1.8中存在区别,本文主要针对于1.7版进行讲解,1.8版的更新内容正在整理,如有错误,不吝赐教
Map
在说HashMap前,有必要聊聊Java世界中非常重要的一个接口类Map,Map可不是地图哦,它是所谓的”映射“
映射直接听中文理解起来会有点奇怪,举个例子就能理解:学号对应学生!要是找这个学生,知道他的学号就行了:)学号与学生是一一对应的关系,学号不能重复!那么所谓的映射其实就是这个意思,说的高大上点就是,有两个非空集合A、B,A集合中必有一个元素a,在B集合中有唯一一个元素b与之对应
所以Map就是这么个玩意,它可以同时存放多个k-v键值对,每个键值对就是上面说的学生和学号的关系
通过这么一个描述,可以很明显的看出Map和Collection是有很大区别的,Map存的元素是成对出现的,而Collection存的元素是单独出现的
Map和Collection一样是一个庞大的体系,想要完全100%的读懂需要花费巨大的精力,但是学习我们要讲究策略,所以我们只需要重点去掌握几个核心的且非常常用的几个类:HashMap,LinkedHashMap,TreeMap以及ConcurrentHashMap,所以接下来我会写几篇文章重点研究这几个Map的核心类,本文则是对于HashMap哈希表的详解。
哈希表
什么是哈希表?在大学课堂上第一次听到这个词从老师的嘴里说出来,我就被吸引了,因为这个词有点新奇有点奇怪
首先,哈希是中文的音译,英文是Hash,它更常被我们称为散列表。
对于哈希表的具体定义,在网络上有着很多回答,以下来自百度百科:
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
那么说的通俗点就是:对于普通的map,我们查找一个k-v,需要遍历所有,比较k值,取得k-v键值对。散列表就是在这个基础上做了一个扩展,引入一个叫做哈希函数的东东,随便输入一个值,这个哈希函数就可以给你返回一个固定长度的输出,称为哈希编码,利用这个哈希函数,我们就能计算每一个k对应的哈希编码,因为哈希码它是固定格式的输出,所以不用担心它们之间出现叛徒的情况。利用这个哈希码将k-v存到对应的位置上,那么我们下次要查询的时候,直接拿着k值算出哈希码,然后直接就能找到具体的k-v。
但是哈希函数由于是一个固定的算法,那么可能会存在不同的输入,计算出的哈希码结果是相同的,那么这个情况被称为哈希冲突。其他还有具体哈希冲突的解决方法有很多,有兴趣可以自行查找,我们还是回到我们研究的问题主体来,继续学习HashMap的源码。
JDK1.7底层实现
为什么这里单独挑出1.7来呢,因为jdk1.8对于HashMap有很大的优化,所以我认为有必要先看看原理老版本的HashMap是如何实现的,再去学习1.8的优化部分
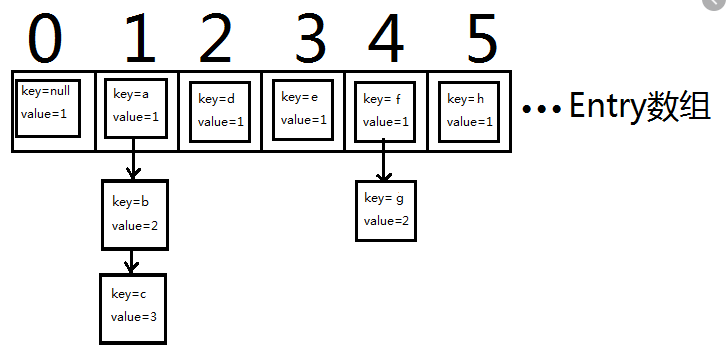
jdk1.7中的,HashMap的实现是通过数组+链表的形式完成的(图是网上随便找的,帮助理解)
上面说了,散列表有个哈希函数可以算出哈希值,通过哈希值计算出元素存储的具体位置(哈希值%数组长度,取模),然后插入到相应的位置
那么代码层面是如何呢?看下HashMap内的代码
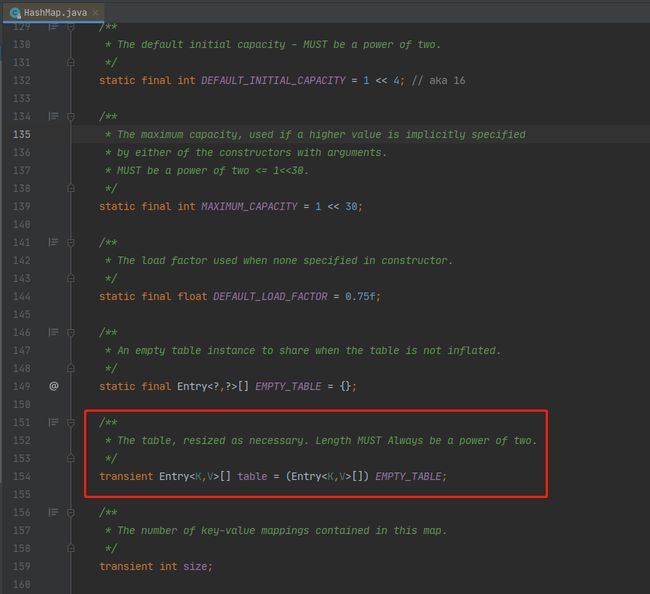
点开HashMap的源码,可以看到HashMap得成员变量中有这个table,是一个Entry
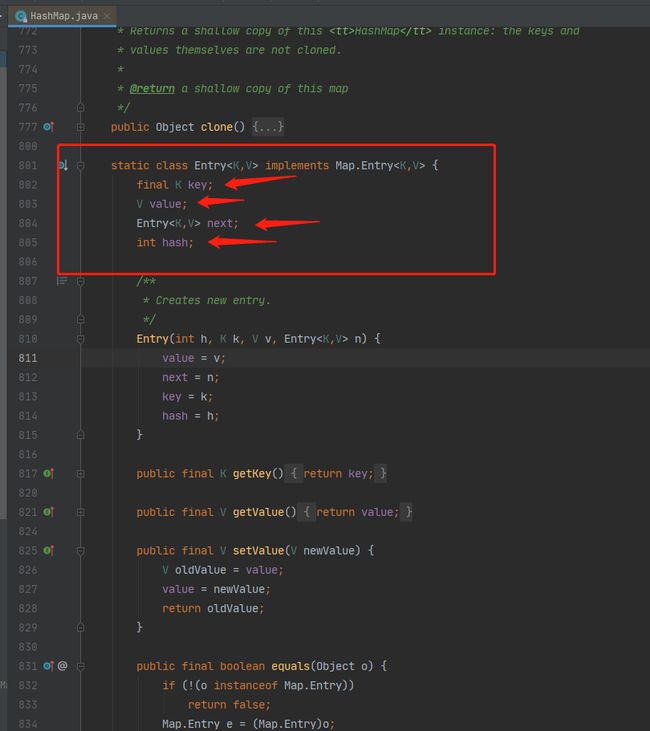
啊哈,Entry是HashMap的一个内部类,它是对于Map中Entry接口的实现!仔细看下这个Entry,熟悉吗?没错,这不就是个单向链表么,ok,所以你现在明白HashMap在1.7中的结果了吗 :)
那么看到这里有的**小(面)朋(试)友(官)**就要问了:**为什么HashMap要用数据+链表这样的结构呢?**这里我特意去Google了一下,网上的回答的有很多,但是感觉很多没到点上,但是也有回答的非常nice的,贴一下链接:https://cloud.tencent.com/developer/article/1491634
用数组是因为可以快速的确定K所在链表的位置,由于存在hash冲突,会出现不同k值,相同hash值得情况,这样会出现多个k-v在同一个数组位上,所以引入链表来解决hash冲突,链式存储hash值相同的k-v,此方法也被称为“拉链法”,因其结构形似拉链而得名,是一种常见的解决hash冲突的方法
然后这个时候**小(面)朋(试)友(官)**露出了邪魅的笑容,继续问:那数组可以被代替吗?比如LinkedList或者ArrayList?
可以,但是没必要!
因为在HashMap中key值定位使用的是Hash值对数组长度取模,然后根据结果查找到目标位置再进行插入,这里如果用数组根据下标可以直接就能找到位置,换成LinkedList,那就要遍历了,遍历可就有点不太聪明的样子了。再说说为什么不用ArrayList,虽然ArrayList的底层用的也是数组,但是,但是!直接使用ArrayList就存在一个局限性的问题,因为ArrayList它已经固定好了它的自动扩容机制在一般情况下是扩容1.5倍,这种扩容机制会很容易让数组的长度不满足2的幂次方,从而导致后续的运算效率出现很大的问题。(在HashMap中,对于数组的长度要求是2的幂次方,为什么要2的幂次方这个问题的答案在下面的讲解中会有详细聊到),而直接使用数组,则可以自定义它的扩容机制,使其满足我们的需求
综上所说,数组可以被替代,但是没必要,因为各方面对比下来数组的效率最高:)
听完了我的回答,**小(面)朋(试)友(官)**露出了欣慰的笑容:)
okok,经过上面的介绍,我们已经知道了HashMap的底层结构**(划重点:在jdk1.7中)**,接下来开始正式学习HashMap的源码,探索下它不为人知的秘密(滑稽)
构造器
翻翻1.7的源代码,可以看到HashMap提供了四个构造函数,简单的阅读一下
// 初始容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 00 无参构造函数,可以看到本质上调用的是#02带两个参数的那个构造函数
// 传递的参数是HashMap两个自带的成员变量DEFAULT_INITIAL_CAPACITY和DEFAULT_LOAD_FACTOR
// DEFAULT_INITIAL_CAPACITY中文翻译=默认初始化容量,然后他的值是 1<<4 AKA 16 :)
// DEFAULT_LOAD_FACTOR则是默认加载因子,这玩意咱先有个印象,后面我会细说,先知道有这么个东西,初始值是0.75
// 所以默认情况下,会创建一个长度为16的数组,且初始加载因子为0.75
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
// 01 单参构造,可以看到这里和无参的区别是传入了一个initialCapacity代替了默认的初始容量
// 通过此方法可以自定义HashMap的初始容量,确切的说是初始数组的大小,后面可以看到具体的代码
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 02 核心构造方法,可以看到上面的构造本质上都是调用的这个方法
// 有两个参数initialCapacity和loadFactor,分别对应初始容量和加载因子大小
public HashMap(int initialCapacity, float loadFactor) {
// 这里先对initialCapacity和loadFactor做好基础的数值大小的判断
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// MAXIMUM_CAPACITY = 1<<30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 设置loadFactor的值
this.loadFactor = loadFactor;
// 这里第一次出现了threshold,和loadFactor一样留一个印象
// 它的含义是阈值,至于是什么阈值,别急慢慢看
threshold = initialCapacity;
// init()空方法,留着扩展使用
init();
}
// 03 和其他集合框架中的类一样,HashMap也提供了一个此类型的构造函数
// 使用它可以直接将其他Map接口类型的类快速的转换为HashMap类型
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 这两个方法放到后面讲
inflateTable(threshold);
putAllForCreate(m);
}
对四个构造方法进行了学习之后,可以看到整体的复杂度很低,就是一些简单的判断和赋值操作,看到这里不免有的小兄弟会产生疑问:
- 说好的数组+链表呢?
- 加载因子又是什么鬼?
- 阈值???
没事小问题,刚开始学习的时候我也不清楚这到底是做什么的,不过不着急,带着疑问继续向下学习,很快就能知道他的作用。
常用API源码分析
按照惯例先从添加方法开始学习 put!!!
put(K key, V value)
// put包含两个参数,也就是我们上面说到的key和value,键值对
public V put(K key, V value) {
// 出现了!真正的初始化在这里!
if (table == EMPTY_TABLE) {
// inflate 中文翻译为 膨胀
// 简单理解就是对于数组的初始化,具体看下面的分析
// 注意这里传入了threshold,就是我们上面说到的阈值
inflateTable(threshold);
// 通过上面这一步,数组可以说是正式被初始化了,其长度是2的幂次方数
// ok 继续向下看
}
if (key == null)
return putForNullKey(value);
// 利用哈希函数计算哈希值,并计算出插入的数组脚标位置
// 这里是重点!!hash()和indexFor()这两个方法
// 具体翻到下面逐行进行学习
int hash = hash(key);
int i = indexFor(hash, table.length);
// 计算好了index的值之后,就是插入操作了
// 我们已经介绍过了1.7中hashmap的底层结构是数组加链表
// 所以计算出在数组中的位置之后需要遍历此位置上的链表,因为可能存在多个值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 这一步有个判断,如果key值存在就覆盖原值,并返回
// 1. hash值不同一定不同,hash值相同可能相同(有冲突的可能)
// 2. key值地址和值都要相同,才回去覆盖
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
// hashmap中recordAccess是个空方法
e.recordAccess(this);
// 覆盖并返回旧值
return oldValue;
}
}
// 老朋友了,modCount,看到他就知道有iterator
modCount++;
// 如果不存在可以被覆盖的k-v,那么链表新增一个节点
addEntry(hash, key, value, i);
return null;
}
// 数组膨胀
private void inflateTable(int toSize) {
// round up to power of 2 这个方法的作用是求出小于等于当前toSize的最大的2的幂次方数
// roundUpToPowerOf2这个方法大有讲头,底下单独细讲这个方法的内部原理
int capacity = roundUpToPowerOf2(toSize);
// 这里对于阈值进行了重新的复制,新的阈值=计算出来的新容量*负载因子
// 这里虽然是min比较,但是基本上是不可能出现取值为MAXIMUM_CAPACITY + 1的情况,因为这个值太大了
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// ok,熟悉的代码,数组初始化,长度为计算出来的capacity,注意注意再注意,capacity是2的幂次方
table = new Entry[capacity];
// 根据需要初始化哈希种子,方法名起的有点奇怪,至少作为一个中国人直接看方法名我是不能直接明白这个方法的作用
initHashSeedAsNeeded(capacity);
}
// 下面这个方法比较难以理解
// 但是在put方法的初始化过程中,它其实没做什么事
// 具体看解释
final boolean initHashSeedAsNeeded(int capacity) {
// 首先hashSeed作为int类型成员变量,初始化是0,所以currentAltHashing=fasle
boolean currentAltHashing = hashSeed != 0;
// 下面这个就比较难理解了
// 首先sun.misc.VM.isBooted()深入源码可以发现返回的是false,但是看到VM.isBooted就知道事情没这么简单
// 实测启动项目,执行put时,打上断点,sun.misc.VM.isBooted()返回true
// 然后再是Holder.ALTERNATIVE_HASHING_THRESHOLD,也一样在启动过程中最终被赋值为Integer.MAX_VALUE
// 而capacity初始为16必然小于Integer.MAX_VALUE,所以useAltHashing=true&false=false
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
// switching=fasle^fasle=fasle
boolean switching = currentAltHashing ^ useAltHashing;
// 所以下面的if不执行
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
// 所以直接返回switching=fasle
return switching;
// 所以可以看到这个方法目前看来屁用么有
}
final int hash(Object k) {
// 到目前为止可以看到hashSeed没有被任何地方赋值过,所以这里就是0
int h = hashSeed;
// 所以根本不会进下面的if
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
// hash方法的真正执行的代码就是下面三行,别看就三行却大有玄机
// 首先这里先获取了k的hashCode,然后注意,做了一个异或操作,所以结果还是hashCode的值这没什么问题
h ^= k.hashCode();
// 重点在于下面这两个,请看下面的详解 --- 1.7的hash函数增强扰动
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 这里传入的h和length分别是上一步计算出的hash值(加了扰动)和数组的长度
static int indexFor(int h, int length) {
// 这个方法和hash方法一样都值得单独挑出来聊聊,看下面详解 ------ hashmap如何计算插入的数组位置
return h & (length-1);
}
// 向链表中添加新的节点
void addEntry(int hash, K key, V value, int bucketIndex) {
// 重点又又又来了!!!这里是hashmap自动扩容的判断条件,有两个!!
// 1. 当前hashmap的总的节点数要大于阈值(这种情况下,hash冲突已经非常大了)
// 2. 当前要插入的位置上没有节点
// 一定要满足这两个条件才会触发扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// resize,非常重要,非常关键,看详解 ------ 1.7的hashmap扩容
resize(2 * table.length);
// key不变,hash也不会变
hash = (null != key) ? hash(key) : 0;
// 重新计算新的数组下标
bucketIndex = indexFor(hash, table.length);
}
// 创建一个新的节点,此处使用的是头插法进行链表的插入
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
// 获取链表顶端的元素
Entry<K,V> e = table[bucketIndex];
// 新建一个节点,并把原来index位置上的那个节点设置为当前节点的next节点,就相当于头插
// 新建完了之后,在index上的节点进行覆盖
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
roundUpToPowerOf2(int number)
上面说过这个方法的作用是求出比当前传入值(int类型)小(确切的说是小于等于)的最大的2的幂次方数
举个例子:传入15返回8,2的3次;传入16返回16,2的4次;传入17返回16,2的4次
下面来慢慢分析它是如何巧妙的做到的:)
private static int roundUpToPowerOf2(int number) {
// 简单的分析,可以看出核心代码调用的就是Integer.highestOneBit((number - 1) << 1)
// 因为number基本上不可能大于MAXIMUM_CAPACITY
// 这里有两个重点 1是highestOneBit方法 2是传入值是 (number-1)<<1
// 看下面的分析
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
// 核心代码,此方法Integer类提供的静态方法
// 打字想说的很详细有点难,我在本子上做了一个草稿,描述下这个过程
public static int highestOneBit(int i) {
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
(抱歉,字确实丑,但我尽力了,不知道这样好不好懂,不懂得话可以看看下面这个博文,讲的特别特别清楚)
博文:https://juejin.im/post/6844903927402479629 大佬写的好呀
回归正题,注意下i的值必然小于等于MAXIMUM_CAPACITY = 2 << 30
看上面的草稿,可以看到每次的右移都是把i在不停的右移,每次右移的结果就是移动的那几位变成了1,举例子
0001 XXXX 经过 i |= (i >> 1) 就变成了 0001 1XXX
0001 1XXX 经过 i |= (i >> 2) 就变成了 0001 111X
…
最后一共移动了 1 + 2 + 4 + 8 +16 = 31位,保证了X所在的位数都变成了1,可以简化写为 0001 111X,X代表很多个1
最后 i - (i >>> 1) 就是:
0001 111X
0000 111X
= 0001 0000 … (n个0)
OHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH !!!!
这就得到了小于等于i的最大的2的幂次方数
看到这里不得不感叹,写出 这个方法的人对于位运算可以说是出神入化了,我跪了大佬
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
1.7的hash函数增强扰动
这个问题对于新人来学习也是有点抽象的,我开始学习的时候完全不能理解这段代码的用意,为什么有这么多的右移和异或操作???
final int hash(Object k) {
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
正当我百思不得其解的时候,我在知乎看到了大佬的一个回答,看完之后茅塞顿开,附上链接:https://www.zhihu.com/question/51784530
简单说明下,理解这个地方的代码之前需要先回到外面的源码,计算完hash值之后下一步操作就是根据hash值计算在数组中插入的位置,就是indexFor这个方法
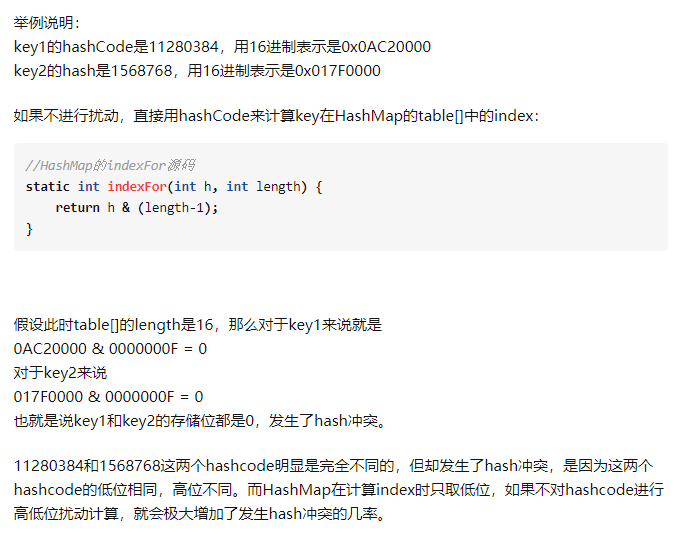
看到这里,你明白了吗?加入了扰动之后,可以充分的让hashcode的高位与低位混合,这样就可以大大的降低出现Hash冲突的几率
JDK官方对该方法的描述那样,使用hash()方法对一个对象的hashCode进行重新计算是为了防止质量低下的hashCode()函数实现。由于hashMap的支撑数组长度总是 2 的幂次,通过右移可以使低位的数据尽量的不同,从而使hash值的分布尽量均匀。
hashmap如何计算插入的数组位置
我们知道在hashmap中数组的长度被规定为了2的幂次方数,这样做的好处,在这里可以提现,举个例子如果长度为16,那么二进制位1 0000,length-1的二进制就是0 1111,就相当于做了一个低位掩码,然后0 1111再与计算出的hash值进行与操作,就恰好可以计算出一个index的值,且这个值得大小一定是小于数组长度的,这就保证了不会出现数组越位的问题,同时配合hash函数中的扰动,还降低了hash冲突,使元素分布的更加均匀
1.7的hashmap扩容
// 首先参数传入的是原数组长度的两倍
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 上面的没啥好讲的,这里直接new了一个长度等于原数组两倍长的数组
Entry[] newTable = new Entry[newCapacity];
// 然后就是最核心的transfer操作,将原数组的内容一模一样搬到新数组
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 覆盖原数组
table = newTable;
// 计算新数组的阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
// 搬运的核心代码
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 循环遍历原数组
for (Entry<K,V> e : table) {
// index上存在链表的时候,遍历链表
while(null != e) {
// 此处从原数组的头插法,变成了尾插法插入到新数组中
Entry<K,V> next = e.next;
// 重新插入之前,小伙伴可能又有疑问了,原先数组在插入的时候需要计算出他的hash值,然后再求得数组中的位置
// 那插入到新的数组的时候,数组的长度已经发生变化了,那是否需要重新计算hash值(rehash),并重新计算位置呢?
// 答案是否定的,不需要rehash操作,可以看到rehash的if块根本不会进去,因为rehash=false,是外面传进来的initHashSeedAsNeeded(newCapacity)
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 所以这里的hash值是原来的hash值,但是由于数组长度发生了变化,所以新插入的数组下标会被重新计算
int i = indexFor(e.hash, newCapacity);
// 然后就是核心的头插法,比如原来链表顺序是 1->2->3,transfer后就变成了3->2->1
e.next = newTable[i];
newTable[i] = e;
e = next;
// 但是这个方法其实隐藏了一个很大的问题就是并发环境下会出现的死循环问题
// 就是这个头插过程,假设同时有两个线程对数组进行并发访问,一个线程正常的已经将1和2插入到了新的数组,此时结构为2->1
// 然后第二个线程刚开始第一个循环,取到1,然后找到newTable[i](此时他已经被第一个线程修改为了2),那么执行e.next = newTable[i]
// 就会产生2->1和1->2,这样单向链表的结构就被破坏了,产生了循环,这就埋下了隐患
}
}
}
// 这个方法上面已经介绍过了,再简单看看,此时的参数变成了 原数组的两倍
final boolean initHashSeedAsNeeded(int capacity) {
// hashSeed还是0所以currentAltHashing还是fasle
boolean currentAltHashing = hashSeed != 0;
// 这里没有任何地方对他进行了操作,仅仅变化了capacity的值,但是我们知道只有在capacity极大的情况下才会出现大于Integer.MAX_VALUE的情况
// 所以这里大概率是fasle
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
// 所以结果大概率也是fasle
return switching;
}
putAll(Map m)
此方法可以将map整体添加到当前map中,此方法在之前学习过的List中都存在类似的方法
public void putAll(Map<? extends K, ? extends V> m) {
// 空的map直接就return
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
// 如果当前的数组未初始化,则进行一个初始化操作,这部分在put的时候已经介绍过了
if (table == EMPTY_TABLE) {
inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold));
}
// 如果要插入的map的大小超过了当前map的阈值的话,要考虑进行resize扩容
if (numKeysToBeAdded > threshold) {
// 计算出目标map的容量
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
// 循环比较当前的容量与可能的目标容量
// 如果小于的话翻倍增长当前的容量(不断左移1位=翻倍)
while (newCapacity < targetCapacity)
newCapacity <<= 1;
// 执行扩容操作
if (newCapacity > table.length)
resize(newCapacity);
}
// 循环插入
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
对比putAllForCreate
// 这个方法在构造器中有被调用
// 整体的思路就是将一个map完整的添加进当前map,只是不同和普通的put不同的地方在于不会进行resize操作
// 所以这是一个private方法不允许用户直接操作,在源码中用到此方法的地方也都是已经完成了对于数据的初始化
// 确保不会超出被插入的map的容量才执行的
private void putAllForCreate(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putForCreate(e.getKey(), e.getValue());
}
// 普通的插入,不多说了,上面都有介绍过
private void putForCreate(K key, V value) {
int hash = null == key ? 0 : hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
createEntry(hash, key, value, i);
}
// 这里还需要额外提点一下putForNull
// 所有的null都是put在桶的首位的
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
put类的方法就介绍这几个,主要的关键就是put方法,了解了这一个,那么其他的几个put类的方法就信手拈来了,都比较简单
在整个hashmap的源码中最重要的也就是put,其他的比如get clear这些都是比较简单的,在面试过程中,主要问的也都是围绕着put相关的一些问题
get(Object key)
非常常规的get方法,和put的思路相同,先计算hash值,然后根据脚标遍历目标的桶,即可!
public V get(Object key) {
// null值有专门的get方法
if (key == null)
return getForNullKey();
// 实际调用的就是getEntry
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
// 先做一个基本的判断
if (size == 0) {
return null;
}
// 计算hash值
int hash = (key == null) ? 0 : hash(key);
// 桶遍历
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
// hashmap中的比较都是这个流程先比较hash在比较值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
// 针对null值进行的专门的获取方法
private V getForNullKey() {
if (size == 0) {
return null;
}
// null值得比较就不需要计算hash了
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
remove(Object key)
remove的方法也是比较简单,就是普通的遍历比较加删除
public V remove(Object key) {
// 可以看到,remove实际调用的是removeEntryForKey
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
// 根据key值进行删除,删除就是简单的链表删除操作
// 相信有好好学习过链表操作的同学这部分理解起来非常简单
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
// 计算目标hash值
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 遍历桶
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
// 常规链表删除操作,不多说了
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
clear()
清空map的操作,此处的清空,调用的是Arrays类的静态方法fill,实际就是将table用null进行填充,从而达到清空数组的效果
public void clear() {
modCount++;
// 实质方法,就是用null来填充数组
Arrays.fill(table, null);
size = 0;
}
public static void fill(Object[] a, Object val) {
for (int i = 0, len = a.length; i < len; i++)
a[i] = val;
}
containsNullValue()
完整的遍历数组+链表,查找是否存在null值,注意这里是值value=null
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
clone()
老朋友了,clone,在ArrayList时专门的介绍过clone,看了下网上别人写的,说是浅拷贝
先复习下浅拷贝,浅拷贝就是创建一个新的对象,所有的基本数据类型的值进行复制,所有引用类型的值进行地址的复制,这个引用类型的属性还是指向原对象的引用属性内存,对新的对象或原对象的引用属性做出改变的时候,两方的引用属性类型的值同时做出改变
public Object clone() {
HashMap<K,V> result = null;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
}
// 可以看到此处重新创建了一个数组,所以原数组和新数组是互不干扰的
if (result.table != EMPTY_TABLE) {
result.inflateTable(Math.min(
(int) Math.min(
size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY),
table.length));
}
result.entrySet = null;
result.modCount = 0;
result.size = 0;
result.init();
// 此处执行的是putAllCreate,上面介绍过再快速说一遍
result.putAllForCreate(this);
return result;
}
//遍历原HashMap
private void putAllForCreate(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putForCreate(e.getKey(), e.getValue());
}
private void putForCreate(K key, V value) {
int hash = null == key ? 0 : hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
createEntry(hash, key, value, i);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 浅拷贝的关键点在这里,直接用的是value,所以如果是引用类型,那么就是直接把地址复制过来了
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
对于常用的api源码分析就到这里,接下来结合面试题做个小结,同时还留了几个小问题,一并做出解释
疑惑?!
loadFactory加载因子到底是做什么的,它为什么是0.75
首先**加载因子是表示Hsah表中元素的填满的程度。**加载因子越大,填满的元素越多,空间利用率越高,但冲突的机会加大了。反之,加载因子越小,填满的元素越少,冲突的机会减小,但空间浪费多了。所以在设计上需要尽量的去在空间利用率和冲突上做一个平衡。
经过对于源码的学习,我们已经可以知道hashmap的size超过容量*加载因子时会进行resize扩容操作
首先如果这个值取得特别小,比如0.5,那么假设一个初始化的map在size超过8的时候就进行了扩容,这可不太妙啊,取得越小扩容的越早,大量的空间没有被利用。
其次如果这个值取得比较大,比如1,那么假设一个初始化的map在size只有等于数组实际容量的时候才扩容,此时虽然空间利用的满满的,但是就会存在大量的hash冲突,依旧会降低效率。
然后为什么是0.75???我查阅了大量的博文,总结出如下:
JDK7源码中有这样一段:
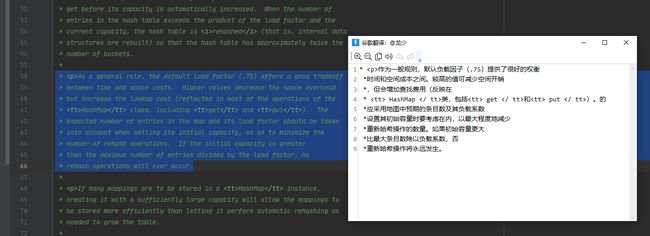
谷歌机翻的不好,附上别人的翻译:
作为一般规则,默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。
这段只是做了一个简单的解释,但是还是没有说明为什么取0.75,答案在JDK8中的一段注释
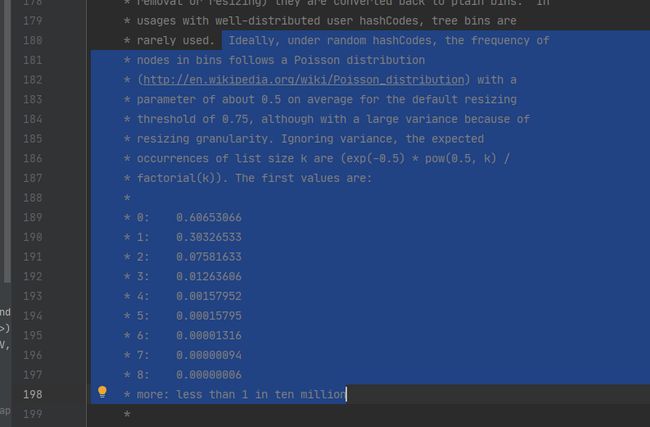
再附上大佬的一段解释:原链接https://zhuanlan.zhihu.com/p/149687607


所以最终的答案是:可以不一定是0.75,0.75是一个折中的选择,为什么是0.75其实也没什么充分的理由,有牛顿法计算得到的是,只要大于0.68就是可以了,0.75可能就是定的一个中间值。选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。
为什么length是2的幂次方?
为了加快哈希计算以及减少哈希冲突
还记得indexFor这个方法吗
static int indexFor(int h, int length) {
return h & (length-1);
}
我们都知道为了找到 KEY 的位置在哈希表的哪个槽里面,需要计算 hash(KEY) % 数组长度
但是!% 计算比 & 慢很多
所以用 & 代替 %,为了保证 & 的计算结果等于 % 的结果需要把 length 减 1
也就是 hash(KEY) & (length - 1),这是对于老方法的一种优化
为什么能减少冲突呢,如果是2的幂次方,那么length-1,必然是全1,比如length=16,二进制位 1 0000;length-1就是15,二进制就是0 1111,全1的情况可以充分的将低位置入运算;相反,如果是2的幂次方,比如10,length-1=9,二进制为 1001,这种情况,进行h & (length-1)运算,只有两位参与到运算中,产生hash冲突的情况会大大提高
所以,HashMap的长度为2的幂次方的原因是为了减少Hash碰撞,尽量使Hash算法的结果均匀分布。
剩下的注入,并发环境下可能存在的问题?resize的过程分析,put方法的过程分析等等都在上面的源码分析中有提到。
小结
以上就是对于JDK1.7版本的HashMap底层的一次解析,HashMap的源码不止于这些,我挑选了其中我认为最重要的地方进行了学习,记录。
要建立一个思维,那就是:源码其实并没有那么遥不可及,并没有难得看不懂,我们需要的是明白脉络,学习思想,特别喜欢马士兵老师曾在视频中说的一句话 "不识庐山真面目,只缘身在此山中。想要明白整个庐山的真面目,我们要看的是他的脉络,而不是蹲在庐山中的一棵大树下研究那一根根的小草"
对于源码的学习也是如此,脉络才是关键,不要上来就去纠结某个方法是如何实现的,要是这样,路走不远,至少我个人是这么认为的:)共勉,加油!