hivesql中使用join 关联表时where 和 on、join 的执行先后顺序
在hive sql 中,总会遇到表关联的同时还需要对左右表进行过滤数据,但是where ,on,join之间的先后顺序是怎么的呢?下面我们来一一探讨一下。
环境:hive 0.13.1版本
- 首先我们看一下t1表全表扫描的num rows 是多少:
select t1.cust_pty_no
,t2.amt
from a t1
left join b t2
on t1.cust_pty_no = t2.cust_pty_no
执行计划如下:
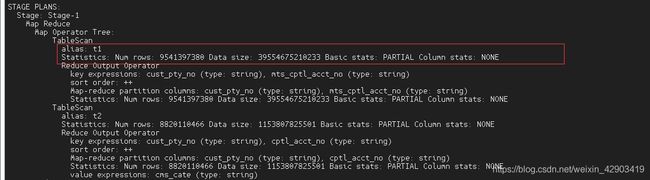
- 如果使用在on 条件后使用where 对t1表进行过滤,如下
select t1.cust_pty_no
,t2.amt
from a t1
left join b t2
on t1.cust_pty_no = t2.cust_pty_no and t2.busi_date='2020-04-17'
where t1.busi_date='2020-04-17'
使用expalin 查看执行计划如下:
看红色圈住部分,numrows 实际上在map阶段已经对t1表的busi_date进行过滤了
 图1
图1
对比一下这个sql
EXPLAIN
select t1.cust_pty_no,t2.amt
from a t1 where t1.busi_date=='2020-04-17'
看该sql执行计划:
和上面sql第一步扫描表的rows num 是一致的,这就说明了上面的sql 先对t1表where过滤了busi_date.
 图2
图2
- 那么问题来了,t2 表的busi_date 条件放在where 会不会也被首先过滤掉呢?
EXPLAIN
select t1.cust_pty_no
,t2.amt
from a t1
left join b t2
on t1.cust_pty_no = t2.cust_pty_no
where t1.busi_date='2020-04-17' and t2.busi_date='2020-04-17'
查看执行计划如下:
 图3
图3
再看一单独执行t2表扫描rows :
EXPALIN
select * from b t2 where t2.busi_date='2020-04-17'
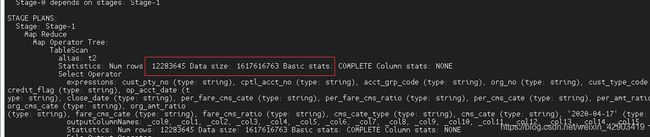
图4
对比图3和图4 的执行计划,对T2表扫描rows ,可以得出结论:
当两个表join 时,写在where 的过滤条件:
a. 如果是左表t1 则会先对busi_date 先进行过滤数据,然后再进行join 操作;
b. 但是对于右表 t2 表并没有对busi_date 进行过滤,即join操作后才对t2的busi_date 进行过滤,这样如果t2表数据非常大的话,效率就会很低。
那么如果要对T2表进行先过滤的话,除了写子查询的模式,如下:
EXPLAIN
select t1.cust_pty_no
,t2.amt
from a t1
left join (select * from b where busi_date='2020-04-17') t2
on t1.cust_pty_no = t2.cust_pty_no
where t1.busi_date='2020-04-17'
执行计划:
先对表T2进行了busi_date 过滤
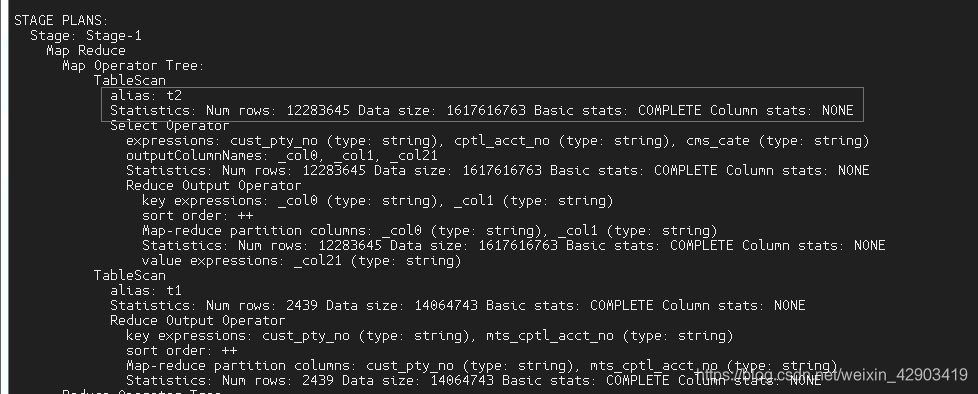
但是这种写法不够简洁,易读性不够强,可以换一种写法
EXPLAIN
select t1.cust_pty_no
,t2.amt
from a t1
left join b t2
on t1.cust_pty_no = t2.cust_pty_no
and b.busi_date='2020-04-17'
where t1.busi_date='2020-04-17'
执行计划

看到没有,把t2表的过滤条件写在on 后面效果是一样的,在读表T2的时候就会过滤掉busi_date 条件的数据了,这样是不是代码要简洁许多呢
综合以上可以得出结论:
1.当过滤条件是分区字段时:
(1)
select * from a
left join b on a.id = b.id
where a.busi_date='2020-04-17' and b.busi_date='2020-04-17'
对于a表不会全扫描,在map 阶段先过滤busi_date=2020-04-17 的数据然后和b表(此时b表是全扫描) join 得到一个临时表,join完之后(在reduce阶段)再对b表busi_date 进行过滤busi_date=‘2020-04-17’
(2)
select * from a
left join b on a.id = b.id and b.busi_date='2020-04-17'
where a.busi_date='2020-04-17'
如上面的sql:
先对a 表进行busi_date 过滤数据,然后对b表进行busi_date 过滤数据,再用a,b表过滤之后的数据进行join操作
这种写法才是简洁高效的,因为在map阶段尽可能将不需要的数据过滤掉,减少后面对资源的占用。
可能有的小伙伴会问了,where过滤的字段与分区和非分区字段是否有区别呢??在这里我的busi_date 其实是表的分区字段,下面看一下是否非分区字段也是一样的:
EXPLAIN
select t1.cust_pty_no
,t2.amt
from a t1
left join b t2
on t1.cust_pty_no = t2.cust_pty_no
where t1.cust_status_name='休眠'
执行计划如下:
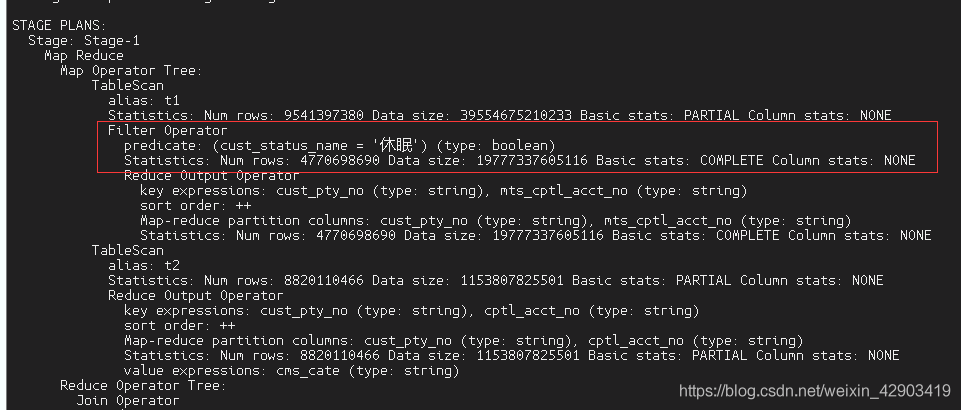
表扫描还是会全表扫描,因为这里并没有对分区进行过滤,但在map 阶段还是会对t1表cust_status_name 条件进行过滤数据
EXPLAIN
select t1.cust_pty_no
,t2.amt
from a t1
left join b t2
on t1.cust_pty_no = t2.cust_pty_no
where t1.busi_date='2020-04-17'
and t2.op_acct_date ='2004-04-22'
查看执行计划
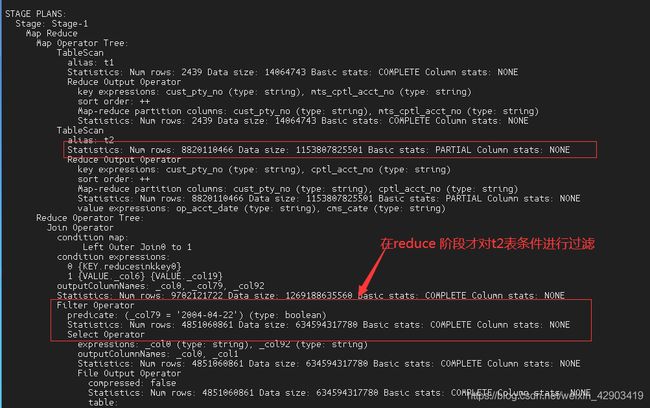
从上图看,对于右表t2的过滤条件放在where 后面过滤,在map 阶段是不会过滤的。
综上所述,得到最终结论:
对于join关联表 如:
select * from a left b on a.id = b.id where 过滤条件
结论:
(1) 如果是对左表(a)字段过滤数据,则可以直接写在where后面,此时执行的顺序是:先对a表的where条件过滤数据然后再join b 表
(2) 如果是对右表(b)字段过滤数据,则应该写在on 条件后面或者单独写个子查询嵌套进去,这样才能实现先过滤b表数据再进行join 操作;
如果直接把b表过滤条件放在where后面,执行顺序是:先对a表数据过滤,然后和b表全部数据关联之后,在reduce 阶段才会对b表过滤条件进行过滤数据,此时如果b表数据量很大的话,效率就会很低。因此对于应该在map 阶段尽可能对右表进行数据过滤。
(3)至于是否全表扫描取决于是否对表的分区字段过滤。这个具体从业务方面考虑是否需要对分区过滤,要想sql 高效那么尽可能在map阶段将不需要的数据过滤,减少后面资源的占用,提高效率