毕业设计:基于YOLO目标检测算法的安全帽/口罩/汽车/行人/交通标志...检测
本文将详细介绍YOLO目标检测算法,该算法支持各种目标检测,包括:安全帽、汽车、造价、交通标志......等。
代做、辅导、答疑、技术支持:
代做/辅导/答疑:毕业设计:<博主qq:914406940>
资料下载/学习交流群:436609296本文以本人的毕业设计题目《基于YOLOv4的安全帽检测算法》为例详细介绍实现过程。
首先,放上最终的实验数据和检测效果对比图:

算法检测的目标区域



图4-12 中午检测结果示例

图4-13 傍晚检测结果示例

图4-14 晴天检测结果示例

图4-15 阴天检测结果示例
第三章 YOLO-Hel安全帽佩戴情况检测算法
3.1 YOLO系列算法介绍
YOLO是英文“You only look once”的缩写,表示目标检测算法只需要对目标图片作一次卷积就能完成目标检测,简单快速,而不需要使用滑动窗口移动一次检测一次,从而导致检测速度非常慢。YOLO系列算法是单阶段(one-stage)目标检测算法的代表,单阶段表示目标检测算法能够同时生成目标边界框以及对目标进行分类,使得整个检测过程简单快速,此外,还有两阶段(two-stage)以及多阶段(muti-stage)的目标检测算法,其中RCNN系列算法是两阶段目标检测算法的代表,该系列算法主要特点是生成目标边界框以及对目标进行分类分成两个阶段完成,整个过程需要先经过候选框生成网络再经过分类网络,检测速度相对较慢,但检测精度相对较高。本文基于YOLOv4算法解决安全帽佩戴情况检测问题。
3.1.1 YOLOv1算法
YOLOv1算法由Joseph Redmon等人提出,YOLOv1通过一个卷积神经网络同时预测目标的外界框以及所属的类别,其检测过程如图3-1所示。

图3-1 YOLOv1检测过程
YOLOv1的检测原理是限定最后特征图的大小是S×S![]() ,根据感受野的原理,特征图中每一个元素都对应着原图的一块区域,所以这就相当于把原图分成了S×S
,根据感受野的原理,特征图中每一个元素都对应着原图的一块区域,所以这就相当于把原图分成了S×S![]() 个小块,若目标的中心落某一块,那么这一块就负责检测该目标,具体就是预测目标的边界框以及属于各个类别的概率,最后通过非最大值抑制( Non-maximal suppression,NMS)算法将大量冗余或得分低的预测框抑制掉,将剩下的预测框作为最终结果,该过程如图3-2所示。
个小块,若目标的中心落某一块,那么这一块就负责检测该目标,具体就是预测目标的边界框以及属于各个类别的概率,最后通过非最大值抑制( Non-maximal suppression,NMS)算法将大量冗余或得分低的预测框抑制掉,将剩下的预测框作为最终结果,该过程如图3-2所示。
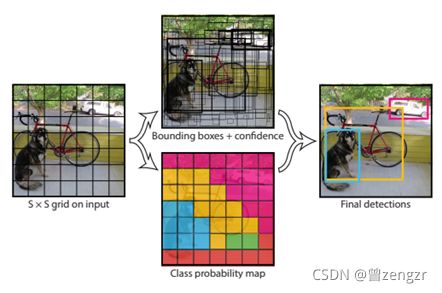
图3-2 YOLOv1算法原理
3.1.2 YOLOv2算法
YOLOv1检测速度很快,但是缺点也比较明显,那就是容易出现定位错误问题,而且相对于Fast R-CNN等两阶段的目标检测算法,YOLOv1的召回率比较低,容易出现漏检的情况,这是因为YOLOv1最终的特征图尺寸是7×7,特征图中每个位置虽然包含两个检测器但是只能检测一个目标,所以导致其检测的粒度不够细,在目标比较小或者目标分布密集的情况下很容易导致漏检。YOLOv2针对YOLOv1的不足作出了多方面的改进,主要包括以下几个方面。
- 采用了新的网络结构,摒弃了全连接,使用了全卷积的结构,因此允许输入任意大小的图片,此外引入了批量正则化(Batch Normalization,BN),可以有效防止过拟合。受到ResNet的启发,使用了跨层的连接,使得梯度传播更加容易,加快训练速度。
- 借鉴faster RCNN,引入了锚框(anchor boxes),并且最终的特征图的尺寸为13×13,特征图中的每个位置都对应着5个不同的锚框,每个锚框都可以单独检测物体,从而使得网络的检测能力大大增强,提高了召回率。与faster RCNN所不同的是,YOLOv2的anchor不是手动指定,而是使用kmeans算法对数据集聚类得到,所以更加符合数据的实际情况,也使得预测边界框位置更加准确。
- 改变了边界框相关参数的预测方式,不再像YOLOv1那样直接预测边界框的宽、高以及中心点坐标,而是先预测tx 、ty 、tw 和th ,然后再算出边界框的大小和位置信息,计算过程如图3-3所示。其中bx,by,bw,bh 分别表示目标边界框的中心横坐标、中心纵坐标、宽和高,tx 、ty 、tw 和th 表示网络的输出,pw 和ph 分别表示锚框的框高,cx,cy 表示特征所在格子的左上角横、纵坐标。
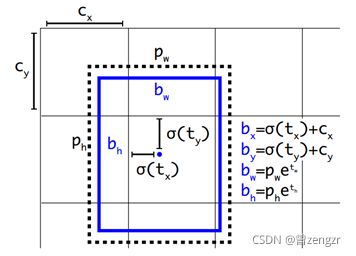
图3-3 YOLOv2中边界框位置计算过程
3.1.3 YOLOv3算法
YOLOv2用于最终检测的特征图尺寸是13×13,同时引入了锚框(anchor),所以相对于YOLOv1,YOLOv2在召回率方面有了很大的提高,但由于YOLOv2依然只在最后的尺度特征图进行检测,导致检测尺度范围小、检测粒度不够细,在目标密集或目标面积小的情况下效果不好,YOLOv3针对YOLOv2的缺点,在其基础上做出了一些改进,检测精度有了很大的提高,其主要贡献如下。
- 设计了新的特征提取网络Darknet53,该网络使用了连续的3×3以及1×1的卷积核,同时受到ResNet网络结构的启发使用了一些短连接,有利于梯度的传播以及特征的融合。
- 引入了特征金字塔网络FPN(Feature Pyramid Network),既可以将不同尺度的特征进行融合,又实现了多尺度检测,FPN的结构如图3-4所示,它形成了一个自上而下的通路(Top-bottom pathway),可以将高层特征及低层特征结合起来,提高特征的表征能力,从而有效提高算法的检测性能。如果输入图片的尺寸是608×608,那么最后YOLOv3分别在19×19、38×38以及76×76三种尺寸的特征图上进行检测,如图3-5所示,并且每个特征图上的各个栅格都对应三种不同的锚框(anchor),所以大大提高了召回率,同时使得网络更加适用于目标尺度范围变化大的情况。

图3-4 特征金字塔网络(FPN)
图3-5 YOLOv3网络结构示意图 - 在分类过程环节中舍弃了softmax,改用二元交叉熵损失,使得网络适用于多标签分类。
3.1.4 YOLOv4算法
在卷积神经网络方面,目前已经产生了大量能够提高准确率的方法,有一些方法只用于某些模型或者某些任务上,但有些方法(如批量正则化、残差连接)已经广泛应用卷积神经网络模型、不同的数据集或任务上。YOLOv4[67] 的主要贡献在于将那些由不同研究人员在不同论文上提出的方法进行整合起来,并通过实验证明其对于提高目标检测性能的有效性,最终得到了一个新的、具有强劲性能的目标检测算法,在速度方面不输YOLOv3,在精度方面该算法却全面超越YOLOv3,与EfficinetDet、ATSS等算法相比YOLOv4在速度方面有着巨大的优势,精度也能与其相提并论,如图3-6所示。

图3-6 YOLOv4与其他检测算法对比
YOLOv4的主要包含了以下创新点:
- 使用了CSPDarkNet53作为特征提取的网络,如图3-7所示,CSPDarkNet53使用了Mish激活函数,更有利于网络的训练,同时使用了CSP(Cross-Stage-Partial-connections,跨阶段部分连接)结构,该结构可以有效地防止不同地层使用重复的梯度信息,提升卷积神经网络的学习能力。此外,YOLOv4在特征融合以及多尺度检测网络方面结合了FPN和PAN(Path aggregation network,路径汇聚网络)两种结构,如图3-8所示,使得多尺度该网络同时具有从上往下的路径以及从下网上的路径,更加有利于特征的融合,能有效提高检测性能。

图3-7 YOLOv4的网络结构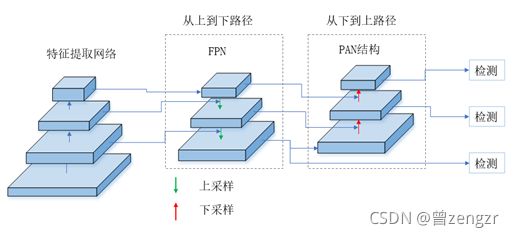
图3-8 YOLOv4特征融合与多尺度检测网络 - 使用了CutMix以及Mosaic数据增强方法,同时使用了DropBlock正则化和类标签平滑方法,大大增强了模型的鲁棒性。
第四章 实验过程与结果分析
4.1 实验平台及实验方案
4.1.1 实验平台介绍
本文的所有实验都在一台炫龙毁灭者KP2个人电脑上完成,该个人电脑搭载了标准版的英特尔i5-8400处理器,16GB的运行内存以及显存容量为6GB的NVIDIA GetForce GTX 1060显卡。在软件方面,本文的所有实验都在Windows操作系统下完成,安全帽佩戴情况检测算法都在PyCharm软件上使用Python语言实现,其中深度学习框架使用了PyTorch。
4.1.2 实验方案
本文的主要目的是通过安全帽佩戴情况检测算法检测施工场地中相关人员的安全帽佩戴情况,能够准确定位并分辨出相关的工作人员是否正确佩戴安全帽。为了验证本文算法的有效性和鲁棒性,本文利用Canon相机在某一具体施工场地采用大致相同的角度采集的一系列包含不同时间段、不同天气情况的视频来进行实验,具体的实验方案为:
- 采用早上、中午以及傍晚三个时间段的视频测试并比较算法在不同时间段、不同光照情况下的检测性能。
- 采用阴天、晴天以及雾霾天三种天气环境下的视频测试并比较算法在不同天气情况下的检测性能。
- 对于改进前后的算法分别进行前面两个实验,综合分析实验结果,比较算法改进前后的性能。
4.2 数据集采集与处理
4.2.1 安全帽佩戴情况数据集收集
训练深度学习模型需要比较多高质量、具有多样性的数据,因为这样能够让网络能够学习到足够信息,使得的模型具有鲁棒性以及泛化性。目前GitHub上以及Kaggle等平台都有与安全帽检测相关的数据集可以免费下载,但是这些不符合本文的实验要求,所以必须重新采集数据。本文在一个具体的施工场地中使用Canon相机以大致相同的角度采集了上午、中午和晚上三个不同时段以及阴天、晴天和雾霾天气三种不同天气情况下共35个视频,每个视频时长十几秒到数分钟不等,所有视频的分辨率均为1280×720。最后将视频分为两部分,每部分均包含上述不同时间段以及不同天气情况下的视频,其中第一部分用作训练集和验证集,第二部分数据用作测试集,在实验过程中用来比较算法的性能。为了制作训练集和验证集,将第一部分的所有视频都拆分成帧,由于同一个视频里面包含大量内容非常接近的帧,如果全部采用这些图片作为训练集或验证集,不仅大大增加标注的工作量而且不太利于模型的学习,所以使用了脚本对各个视频所产生的帧进行抽样,具体就是每隔60帧或者100帧采集一帧加入最终的训练集或者验证集,最终得到了3100多张图片,按8:2的比例分为训练集和验证集。而第二部分视频则全部拆分成帧,共1800张图片,全部标注完成后留到后面算法测试时使用。
部分图片如图4-1所示:

图4-1 部分图片示例
4.2.2 训练数据的预处理
为了得到训练数据,这里需要将4.2.1节中经过拆分视频以及采样步骤后得到的图片进行标注。首先使用脚本将所有图片以数字的形式进行重命名,如“000000.jpg”、“000001.jpg”等,且名字不能重复,然后使用图像标注软件LabelImg对所有图片进行标注,得到安全帽佩戴情况检测所需要的数据集。LabelImg的操作界面如图4.2所示,在标注过程中使用方框将需要检测的区域框住,并指定类型,为了方便算法判断施工人员是否佩戴安全帽,这里将从肩膀开始一直到头顶的这一块区域作为检测的目标,如果施工人员佩戴了安全帽则把其归为“wearing”一类,如果没有佩戴安全帽则把其归为“non_wearing”一类。

图4-2 LabelImg操作界面
经过LabelImg标注后,每张图片都会对应生成一个.xml文件,该文件存放了该图片所有的标注信息,主要包括图片所属的文件夹、图片的具体路径、图片的尺寸以及每个目标的位置信息和类别信息,如图4.3所示。

图4-3 xml文件内容
4.3 算法性能的评价指标
为了更加科学地衡量算法的性能,这里引进一系列在目标检测领域常用的评价指标,具体包括Precision(精度或者查准率)、Recall(召回率或者查全率)、Average Precison(平均精度,AP)、Average Recall(平均召回率,AR)、F1度量、交并比以及用于衡量算法处理速度的帧率。
为了更好地理解Precision和Recall的计算原理以及计算过程,这里引入如表4-1所示的检测结果混淆矩阵。
表4-1 检测结果混淆矩阵
| 正例 |
TP(真正例) |
FN(假反例) |
| 反例 |
FP(假正例) |
TN(真反例) |
上面的混淆矩阵是相对某一类而言的,检测目标中有多少个类别,那么检测结果就能产生多少个混淆矩阵,那么就能相对应地计算各个类别的Precison以及Recall等指标。在本文的实验中真正例(True Positive,TP)表示那些属于该类并且被目标检测算法正确定位并且正确归类的目标;假反例(False Negative,FN)表示那些属于该类但被目标检测算法错误归类或者漏检的目标;假正例(False Positive,FP)表示那些不属于该类,但是被目标检测算法归为该类的目标;真反例(True Negative,TN)表示那些不属于该类,且目标检测算法也没有把其归为该类的目标。为了更加直观地理解TP、FP以及FN的定义,图4.4给出了一个具体的例子。

图4-4 TP,FP,FN示例
以上为摘抄的部分章节 ,完成论文及相关资料可私信博主。
代做/辅导:毕业设计/课程设计
资料/答疑/学习交流Q群:540219450
完整目录如下:
目录
摘要. I
ABSTRACT III
目录. V
CONTENTS VII
第一章 绪论. 9
1.1本课题研究背景及研究意义... 9
1.2 安全帽检测相关问题的研究现状... 10
1.2.1基于传感器的检测方法... 10
1.2.2基于视觉检测的方法... 10
1.3目标检测算法的研究现状... 13
1.4本文主要内容和章节安排... 15
1.5本章小结... 16
第二章 卷积神经网络基础知识. 17
2.1网络结构... 17
2.2激活函数... 19
2.3损失函数... 22
2.4优化算法... 23
2.5本章小结... 24
第三章 YOLO-Hel安全帽佩戴情况检测算法. 25
3.1YOLO系列算法介绍... 25
3.1.1YOLOv1算法... 25
3.1.2YOLOv2算法... 27
3.1.3YOLOv3算法... 28
3.1.4YOLOv4算法... 29
3.2精简网络结构及聚类优化锚框参数... 31
3.2.1YOLOv4锚框机制... 31
3.2.2聚类分析本文目标的宽、高分布情况... 32
3.2.3精简YOLOv4网络结构及优化锚框参数... 35
3.3引入注意力模块提高算法性能... 37
3.4本章小结... 40
第四章 实验过程与结果分析. 41
4.1实验平台及实验方案... 41
4.1.1实验平台介绍... 41
4.1.2实验方案... 41
4.2数据集采集与处理... 41
4.2.1安全帽佩戴情况数据集收集... 41
4.2.2训练数据的预处理... 43
4.3算法性能的评价指标... 44
4.4基于视频流的安全帽佩戴情况检测实验... 47
4.4.1安全帽佩戴情况检测算法的训练及检测过程... 47
4.4.2实验数据及检测效果对比分析... 50
4.4.3算法鲁棒性分析... 56
4.4.4算法模型大小及检测速度对比分析... 57
4.5本章小结... 58
总结与展望. 59
总结... 59
展望... 60
参考文献. 61