Spring启动过程详解
Spring启动过程详解
- 前言
- spring容器启动过程
-
- AnnotationConfigApplicationContext
-
- 有参数构造方法
- 无参数构造
- AnnotatedBeanDefinitionReader构造
- 配置类解析register(解析我们的配置类Appconfig)
- refresh
-
- 启动准备prepareRefresh
- prepareBeanFactory(beanFactory)
- registerBeanPostProcessors(beanFactory)
- initMessageSource
- initApplicationEventMulticaster
- registerListeners
- finishBeanFactoryInitialization(beanFactory)
- finishRefresh
前言
Spring作为一款比较优秀的IOC容器,它的启动过程是怎么的呢?在前面的笔记中我们已经将它创建bean的生命周期已经说的很清楚了,可能还有些比较细的地方没有说的很清楚,但是也不影响我们理解spring的bean生命周期,在spring的生命周期中,有一个比较重要也是使用非常广泛的扩展点就是bean的后置处理器,bean的后置处理器分为了实例化前、实例化后、初始化前、初始化后以及MergedBeanDefinitionPostProcessor后置处理器,spring的依赖注入@AutoWired以及@Resouce、@PostConstruct、@PreDestory都是使用了MergedBeanDefinitionPostProcessor的后置处理器来实现的;而我们在看spring的生命周期的时候都有很大的疑问,就是这些后置处理器是什么添加到缓存中去的,还有我们的定义的业务bean,也就是加了@Component注解的一些普通类是如何进入到beanDefinitionMap中的,而bean的生命周期只是从beanDefinitionMap中取出来然后如果是非懒加载的,单例的,那么就会创建对象放入单例池中,这些的这些我们都存有疑问,所以从这篇笔记开始,我们就来分析下spring在生命周期中使用的这些后置处理器已经BeanDefinition是什么时候加进去的。
spring容器启动过程
spring的启动入口有很多,在xml中有xml的方式,在注解中有注解的方式,现在在web的方式中也有web的注解启动方式,AnnotationConfigApplicationContext是以注解的配置类的方式启动,就是传入一个配置类,这个配置类包含了你需要注册的到容器中的bean的一些信息,比如扫描类路径信息,但是这个启动入口类是不支持容器的重复刷新的,也就是refresh只能调用一次,而使用AnnotationWebConfigApplicationContext这个是支持容器的重复刷新的,今天我们就以AnnotationConfigApplicationContext来讲解下spring的启动过程;下面的启动过程,我们以一段程序来开始:
public class Client {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(AppConfig.class);
ac.registerShutdownHook();
System.out.println(ac.getBean(UserService.class));
}
}
AnnotationConfigApplicationContext
AnnotationConfigApplicationContext 是以注解的方式启动,设置一个配置类,比如AppConfig,然后这个AppConfig可以配置@Bean,可以设置@Compoentscan,注解里面可以配置要扫描的类路径信息;
有参数构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
//调用自己的另外一个无参数的构造方法,去初始化BeanFactory,创建配置类读取对象AnnotatedBeanDefinitionReader以及
//classpath扫描对象
this();
/**
* 注册配置类信息,这register就是调用reader将我们定义的配置类扫描成一个配置类,配置类中有@CompoentScan配置的扫描路径
* 都会解析成一个BeanDefinition,然后在bean工厂后置处理器中会读取这个配置类,然后进行扫描,将路径下的所有符合条件的普通类
* 都扫描成一个BeanDefinition对象然后放入到beanDefinitionMap中,其中包括了factoryBean、我们自己定义了beanFactory后置处理器
* bean的后置处理器
*/
register(componentClasses);
/**
* 刷新工厂,目前所在的这个类AnnotationConfigApplicationContext是不支持重复刷新的
* 这里理解是刷新工厂,其实就是spring的一个启动过程,在前面将bean工厂的后置处理器和后面的一些bean的后置处理器都加到了
* beanFactory这种,下面的refresh就是开始对spring的容器进行启动,扫描、注册、创建单例池、国际化已经事件的监听的相关操作
*/
refresh();
}
无参数构造
public AnnotationConfigApplicationContext() {
/**
* 1.调用父类GenericApplicationContext的构造方法实例化一个bean工厂DefaultListableBeanFactory
* 2.调用父类初始化ASM 读取class的相关对象
* 3.在IOC容器中初始化一个 注解bean读取器AnnotatedBeanDefinitionReader
* 3.1初始化注解读取器的时候将spring的原生态的一些系统处理类放入工厂(DefaultListableBeanFactory)的一个map里面
* 3.2 初始化的spring原生类是作为spring的默认后置处理器
* AnnotatedBeanDefinitionReader是可以将我们的一个普通类注册成一个BeanDefinition
* AnnotatedBeanDefinitionReader还将一些bean的后置处理器放入到bean后置处理器列表中
*/
this.reader = new AnnotatedBeanDefinitionReader(this);
/**
* 在IOC容器中初始化一个 按类路径扫描注解bean的 扫描器
* 请注意,这里的扫描器是我们在外层给定一个包路径,它来扫描,
* 如果我们仅仅是通过register()和refresh()方法的话,是不会用到scanner来扫描的
* 而spring底层在refresh容器的时候读取CommponetnScan中包路径的时候扫描是通过自己构建一个新的
* ClassPathBeanDefinitionScanner来扫描的
* 所以ClassPathBeanDefinitionScanner是可以将我们的一个类路径下的所有的符合条件的普通类扫描成一个一个的BeanDefinition
* 然后注册到beanDefintionMap中
*/
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
上面的两个构造方法其实都可以使用,使用无参数的构造,那么你要手动注册一个配置类,也就是我们上面的AppConfig,如果调用有参数的构造,那么spirng会默认调用无参数的构造进行spring的容器初始化,比如工厂的创建,扫描器对象的创建、配置类读取器对象的创建已经一些工具类、beanfactory的后置处理器已经bean的一些后置处理器的创建,都是在无参数的构造里面创建了,说的简单点都是在AnnotatedBeanDefinitionReader中创建的;而Bean工厂的创建是在父类中创建的GenericApplicationContext。
AnnotatedBeanDefinitionReader构造
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
/**
* 扫描spring 原生的后置处理器放入工厂的bd map中(bean工厂的beanDefinitionMap)
* spring底层的bd都是RootBeanDefinition
* 1.添加ConfigurationClassPostProcessor成一个BeanDefinition;
* 2.添加AutowiredAnnotationBeanPostProcessor成一个BeanDefinition;
* 3.添加CommonAnnotationBeanPostProcessor成一个BeanDefinition;
* 4.添加EventListenerMethodProcessor成一个BeanDefinition;
* 5.添加DefaultEventListenerFactory成一个BeanDefinition;
*/
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
/**
* Register all relevant annotation post processors in the given registry.
* @param registry the registry to operate on
* @param source the configuration source element (already extracted)
* that this registration was triggered from. May be {@code null}.
* @return a Set of BeanDefinitionHolders, containing all bean definitions
* that have actually been registered by this call
* 这个方法主要是根据当前的bean工厂做一些设置:
* 1.添加一个默认的比较器
* 2.设置一个上下文的筛选器(蛀牙对ban的查找进行筛选的类)
* 3.添加ConfigurationClassPostProcessor成一个BeanDefinition;
* 4.添加AutowiredAnnotationBeanPostProcessor成一个BeanDefinition;
* 5.添加CommonAnnotationBeanPostProcessor成一个BeanDefinition;
* 6.添加EventListenerMethodProcessor成一个BeanDefinition;
* 7.添加DefaultEventListenerFactory成一个BeanDefinition;
* 在没有启用JPA的情况下,胡添加5个BeanDefinition(后置处理器),一个比较器BeanDefinition,一个bean筛选器(BeanDefinition)
*/
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) {
//先得到一个工厂Bean工厂,这个Bean工厂是之前初始化好的,是一个DefaultListableBeanFactory
DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null) {
//这里的Bean工厂肯定不能为空,这里是设置比较器的,如果说你没有设置比较器之类的,这里设置一个默认的比较器,这个比较器
//可以在使用BeanDefinition排序的时候使用,比如说你实现了Order接口或者PriorityOrdered的时候,BeanDefinition的执行
//顺序可以使用它来进行排序
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);
}
//这里就是之前我们看的bean中的依赖注入的时候,先byType的时候,对找到的多个bean有筛选,比如先byType,再进行是否启用了
//自动注入候选者,泛型的判断以及Qualifier的筛选
/**
* ContextAnnotationAutowireCandidateResolver中的父类是QualifierAnnotationAutowireCandidateResolver
* QualifierAnnotationAutowireCandidateResolver主要是对泛型的筛选和Qualifier的bean进行筛选,而ContextAnnotationAutowireCandidateResolver
* 是QualifierAnnotationAutowireCandidateResolver它的子类,主要提供了一些代理工厂的创建,延迟加载的一些判断
*/
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());
}
}
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
//这里添加一个ConfigurationClass的后置处理器到bd中
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
/**
* 这里添加的是ConfigurationClassPostProcessor这个BeanDefinition,这个BeanDefinition很重要
* 它本身也是一个beanFactory的后置处理器,这里添加进去的意思就是说后面spring启动扫描的时候就是用这个后置处理器来
* 扫描我们的配置类,比如我的配置类是Appconfig,那么这个后置处理器就是专门处理这个配置类配置的类路径信息
* 所以说这个beanFactory后置处理器非常重要,简单来说就是对我们配置类路径进行扫描,扫描成一个一个的BeanDefinition
* 然后放入beanDefinitonMap中,就是这个ConfigurationClassPostProcessor后置处理器来做的事情
*
* 这里生成的是一个RootBeanDefinition,看了spring的生命周期都知道,spring中的扫描成的BeanDefinition最后都会合并成
* RootBeanDefiniton,意思就是它没有父类的bd了
*/
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
//这里添加一个AutowiredAnnotationBeanPostProcessor,这个AutowiredAnnotationBeanPostProcessor在spring的生命周期中
//非常重要,主要是处理依赖注入的@AutoWired
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
/**
* 下面这个注册是CommonAnnotationBeanPostProcessor,这个bean的后置处理器主要处理@Resource、@PostConstruct
* @PreDestory注解,也是依赖注入的一部分,这里先把这个bean的后置处理器加入到beanDefinitionMap中
*/
// Check for JSR-250 support, and if present add the CommonAnnotationBeanPostProcessor.
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// Check for JPA support, and if present add the PersistenceAnnotationBeanPostProcessor.
//如果你的系统中启用了JPA的方式,那么这里添加一个JPA的后置处理器
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition();
try {
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,
AnnotationConfigUtils.class.getClassLoader()));
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);
}
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 事件方法的监听器BeanFactoryPostProcessor,是一个bean工厂的后置处理器
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
//这里添加的是一个默认的事件监听工厂
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
}
return beanDefs;
}
这读取器的构造器法主要是根据当前的bean工厂做一些设置:
1.添加一个默认的比较器
2.设置一个上下文的筛选器(蛀牙对ban的查找进行筛选的类)
3.添加ConfigurationClassPostProcessor成一个BeanDefinition(配置类解析器);
4.添加AutowiredAnnotationBeanPostProcessor成一个BeanDefinition(依赖注入);
5.添加CommonAnnotationBeanPostProcessor成一个BeanDefinition(依赖注入、生命周期);
6.添加EventListenerMethodProcessor成一个BeanDefinition;
7.添加DefaultEventListenerFactory成一个BeanDefinition;
在没有启用JPA的情况下,胡添加5个BeanDefinition(后置处理器),一个比较器BeanDefinition,一个bean筛选器(BeanDefinition);
配置类解析register(解析我们的配置类Appconfig)
register方法将我们的配置类Appconfig解析成一个BeanDefinition,然后放入到beanDefinitionMap中,AppConfig配置类包含了我们的系统的类扫描路径;
public void register(Class<?>... componentClasses) {
Assert.notEmpty(componentClasses, "At least one component class must be specified");
/**
* 这里开始注册我们的Bean,这个Bean是配置类的Bean,这个配置类的Bean
* 是配置了告诉spring,我们需要扫那些包,而本身这个配置类的bean最终也会成为一个BeanDefinition
*/
this.reader.register(componentClasses);
}
private <T> void doRegisterBean(Class<T> beanClass, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, @Nullable Supplier<T> supplier,
@Nullable BeanDefinitionCustomizer[] customizers) {
/**
* 将Bean配置类信息转成容器中AnnotatedGenericBeanDefinition数据结构, AnnotatedGenericBeanDefinition继承自BeanDefinition作用是定义一个bean的数据结构,
* 下面的getMetadata可以获取到该bean上的注解信息
* 下面的构造方法spring通过手段读取我们配置的配置类比如Appconfig这个类
* 他会把这个类上的所有注解信息都读取到abd中
*/
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(beanClass);
//@Conditional装配条件判断是否需要跳过注册
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
//设置回调
abd.setInstanceSupplier(supplier);
//解析bean作用域(单例或者原型),如果有@Scope注解,则解析@Scope,没有则默认为singleton
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
//作用域写回BeanDefinition数据结构, abd中缺损的情况下为空,将默认值singleton重新赋值到abd
abd.setScope(scopeMetadata.getScopeName());
//生成bean配置类beanName
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
//通用注解解析到abd结构中,主要是处理Lazy, primary DependsOn, Role ,Description这五个注解
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
// @Qualifier特殊限定符处理,一般用这个注解的扫描类,是没有这些东西的,我猜其他子类的扫描器可能会有这些东西
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
if (Primary.class == qualifier) {
// 如果配置@Primary注解,则设置当前Bean为自动装配autowire时首选bean
abd.setPrimary(true);
}
else if (Lazy.class == qualifier) {
//设置当前bean为延迟加载
abd.setLazyInit(true);
}
else {
//其他注解,则添加到abd结构中
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
if (customizers != null) {
for (BeanDefinitionCustomizer customizer : customizers) {
customizer.customize(abd);
}
}
//根据beanName和bean定义信息封装一个beanhold,heanhold其实就是一个 beanname和BeanDefinition的封装
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
上面的代码就是将配置类解析成一个BeanDefinition,其他没有什么可分析的。
spring执行到配置类解析完成,beanDefinitionMap中一共有6个BeanDefinition,有5个是spring开天辟地的内置BeanDefinition,有一个是我们的配置类,我们启动来看下:

我们把断点打在refresh方法前,看到beanDefinitionMap中只有6个BeanDefinition,有5个是spring内置的,上面已经说了,有一个是调用register将配置类注册进去的BeanDefinition;这5个BeanDefinition分别是:
ConfigurationClassPostProcessor:配置类解析器,后面扫描类
EventListenerMethodProcessor、DefaultEventListenerFactory:事件监听器
AutowiredAnnotationBeanPostProcessor:@AutoWired依赖注入
CommonAnnotationBeanPostProcessor:@Resource依赖注入,生命周期回调。
refresh
refresh这个方法必须要开一个一级标题来说,这个方法是spring的核心启动过程都在里面,当然了,这篇笔记讲不完spring的启动过程,除了扫描那个过程,其他过程在这篇笔记中记录,扫描过程太复杂了, 需要单独开一遍笔记来分析。这里简单将refresh的过程分析下。
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
//容器启动前准备工作,也就是设置容器当前的状态和记录启动开始时间以及初始化资源数据以及验证下我们需要验证的一些资源key是否存在
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
/**获取一个默认的工厂,这个工厂在我们的构造实例化的时候就一个创建了一个默认的工厂
* 这个工厂非常重要,我们spring的执行的开始阶段是先暴露一个工厂,这个工厂里面包括了spring
* 之后执行的所有东西,其中我们的加了组件注解的,比如@Component @Reponsity等都会被扫描到
* 而扫描到的类,目前还不是Bean,spring扫描到过后将它们变成Bd,一般是AnnotatedBeanDefinition
* 也就是注解BD,然后将这个BD放入 默认工厂DefaultListableBeanFactory中的bdmap
*/
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
/**
* 这里是准备工厂:
* 1.设置BeanDefinition的类加载器
* 2.设置spring容器默认的类型转换器
* 3.设置spring解析el表达式的解析器
* 4.添加一个Bean的后置处理器ApplicationContextAwareProcessor
* 5.将bean工厂的一些类,比如ApplicationContext直接注册到单例池中
* 6.去除一些在byType或者byName的时候需要过滤掉的一些bean(spring在依赖注入的时候会先在这些默认注册的bean中进行byType找
* 如果找到了,就加入到列表中,简单来说就是比如你在bean中依赖注入了ApplicationContext context,那么spring会把默认注册的这些bean
* 中找到然后进行注册)。
* 7.将系统的环境信息、spring容器的启动环境信息、操作系统的环境信息直接注册成一个单例的bean
*/
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
//这里是一个空壳方法,spring目前还没有对他进行实现,但是我们通过名字postProcessBeanFactory
//其实后续可以添加一些用户自定义的或者默认的一些特殊的后置处理器工程到beanFactory中去
//这个方法是留给子类去实现的
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
//这里就是调用后置处理器,程序执行到这里为止,还没有添加的有我们用户自定义的后置处理器,但是
//spring添加了自己默认的后置处理器,比如ConfigurationClassBeanFactory,这个类用来解析和扫描
//应用组件,比如加了@Compent或者相对的其他组件的类,将它们转成bd放入工厂的bdmap中
//这里做的事情有:
// 1.将我们标记为容器单例类扫描成bd放入bdmap
// 2.处理@Import注解
//3.如果我们的配置类是@Configuration的,那么会生成这个配置类的CGLIB代理类,如果没有加@Configuration,则就是一个普通Bean
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
/**
* 上面的一个方法invokeBeanFactoryPostProcessors是将我们系统中所有符合条件的普通类都扫描成了一个BeanDefinition
* 并且放入到了beanDefinitionMap中,包括业务的bean,ban的后置处理器、bean工厂的后置处理器等等
* 也就是说所有的BeanDefinition都已经扫描完成了,下面这个方法做的事情就是从beanDefinitionMap中
* 取出bean的后置处理器然后 放入到后置处理器的缓存列表中
* 当然了,这里不仅仅去取出后置处理器,还进行了一些排序,具体怎么排序,可以看下里面的操作
*/
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
//初始化国际化资源信息
initMessageSource();
// Initialize event multicaster for this context.
//事件注册器初始化
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
//空壳方法,留给子类实现
onRefresh();
// Check for listener beans and register them.
//将容器中和BeanDefinitionMap中的监听器添加到事件监听器中
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
/**
* 创建单例池,将容器中非懒加载的Bean,单例bean创建对象放入单例池中,包括容器的依赖注入
*/
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
//容器启动过后,发布事件
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
上面额过程总体来说就是:
这个是工厂刷新的实现,在这个Applicationcontext中是不支持一个工厂的重复刷新
这里面所做的事情就比较多了,spring的容器启动也就是调用了refresh
1.容器启动的准备工作;
2.准备工厂,初始化bean工厂,设置一些后置处理器还有一些参数设置;
3.通过bean工厂的后置处理器去处理配置类信息,将配置类配置的路径下的所有普 通类扫描成BeanDefinition。
4.注册系统中的bean工厂后置处理器到后置处理器列表中。
5.初始化资源;
6.事件和监听的发布处理;
7.最后创建spirng的核心单例池;
8.容器启动完成,发布事件。
启动准备prepareRefresh
protected void prepareRefresh() {
// Switch to active.
//记录启动时间
this.startupDate = System.currentTimeMillis();
//设置当前容器时激活状态
this.closed.set(false);
this.active.set(true);
if (logger.isDebugEnabled()) {
if (logger.isTraceEnabled()) {
logger.trace("Refreshing " + this);
}
else {
logger.debug("Refreshing " + getDisplayName());
}
}
// Initialize any placeholder property sources in the context environment.
//初始化property资源文件,spring这里没有实现,是留给子类去实现了,如果你定义了一个启动器,那么你可以去实现自己的加载资源的逻辑
initPropertySources();
// Validate that all properties marked as required are resolvable:
// see ConfigurablePropertyResolver#setRequiredProperties
//这里是验证现在系统资源中必须要存在哪些资源key,也就是说现在的环境中,必须要存在哪些key才能进行启动容器的意思
// 就是验证资源的key是否在环境中存在的意思
getEnvironment().validateRequiredProperties();
//初始化监听器,如果这个监听器不为空,然后清空监听器
// Store pre-refresh ApplicationListeners...
if (this.earlyApplicationListeners == null) {
this.earlyApplicationListeners = new LinkedHashSet<>(this.applicationListeners);
}
else {
// Reset local application listeners to pre-refresh state.
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
// Allow for the collection of early ApplicationEvents,
// to be published once the multicaster is available...
this.earlyApplicationEvents = new LinkedHashSet<>();
}
getEnvironment().validateRequiredProperties()这个简单来说就是你可以设置一个你认为在系统必须要存在的参数,比如你在-D参数中新增了一个参数bmlxx,那么你需要检查它必须存在,否则启动失败,所以我们看下面的例子:
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(AppConfig.class);
ac.getEnvironment().setRequiredProperties("bmlxx");
ac.refresh();
ac.registerShutdownHook();
//System.out.println(ac.getBean(UserService.class));
while(true);
在启动参数中加入:
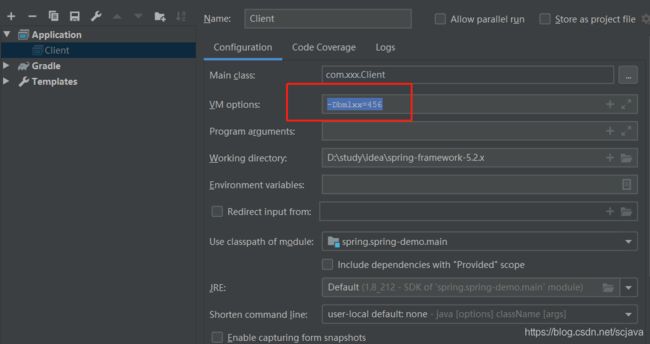
那么启动是正常,如果你ac.getEnvironment().setRequiredProperties(“bmlxx”);设置一个没有的参数,就会报错,容器启动失败,但是要注意的是不一定是hi在启动参数,在系统的几个环境变量中增加都可以。
prepareBeanFactory(beanFactory)
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
// Tell the internal bean factory to use the context's class loader etc.
//添加一个类加载器,这个类加载器的用处在那里呢?spring扫描类的时候是通过ASM字节码技术扫描的,这个时候这个class是没有被加载的
//只是在硬盘上的一个class文件而已,扫描到过后是放入了BeanDefinition的beanclass属性中,只是一个类的全限定名,
//这里设置类加载器的意思就是后面初始化bean的时候会将这个beanclass的全限定名拿出来然后加载到jvm,这个时候就需要一个类加载器
//所以这里设置一个了加载器
beanFactory.setBeanClassLoader(getClassLoader());
//添加一个处理el表达式的解析器,比如我们的@Value()中就有可能是表达式,需要解析$和#,$是一个上下文参数的占位符
//而#是el表达式
beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader()));
//注册一些类型的转换器,比如我们在类中定义了
/**
* @Value("c://xxx/tt.file")
* private File file;
* 那么这里设置的类型转换器就是讲@Value中的字符串直接生成一个File,还有类似于Integer xxx一样的意思
*/
beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this, getEnvironment()));
// Configure the bean factory with context callbacks.
/**
* 这里添加一个ApplicationContextAwareProcessor,这个类就是Application,我们的一个普通类型如果实现了这个接口
* 那么这个接口会提供一个默认的回调方法,会将Application对象给你,你拿到这个对象过后就可以对bean工厂进行操作
* ApplicationContextAwareProcessor是一个bean的后置处理器,是在bena的初始化前进行调用的postProcessBeforeInitialization
* 主要是一些Aware的回调,这个aware不是spring默认的aware,默认的awre是在初始的方法里面调用的
* 这里的ApplicationContextAwareProcessor主要处理了如果实现了
* EnvironmentAware
* EmbeddedValueResolverAware
* ResourceLoaderAware
* ApplicationEventPublisherAware
* MessageSourceAware
* ApplicationContextAware
* 那么它会在bean的实例化前来调用这些awar的回调方法
*/
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
/**
* 下面的ignoreDependencyInterface就是针对上面的添加的bean后置处理器ApplicationContextAwareProcessor的一个补充
* 就是说如果我们定义的bean是单独的byType或者byName的形式,这个在xml中或者@Bean会有设置,一般的使用@Component是不会
* 只有byType或者byName的,@component是先byType,再经过一系列的筛查,再byName,所以在xml中或者@Bean中设置了bytype或者byname的
* 时候,要过滤下面的这些aware的依赖注入的调用,比如
*
* public xxx implements Applicationaware{
*
* @AutoWired
* @Ovvierd
* public void setApplicationContext(Application contet){
*
* }
*
* }
* 首先如果加了@AutoWired,依赖注入的时候会扫描到进行调用,而本身ApplicationContextAwareProcessor又是一个bena的初始化前
* 的后置处理器,所以针对@AutoWired会调用两次,而xml或者@Bean中可能只会调用一次,而真正的实际开发过程中
* 我们不会在一个回调的方法中加一个@AutoWired,只是这里把这个概念说清楚;
* 所以下面的ignoreDependencyInterface将这些aware类添加到ignoredDependencyInterfaces缓存中
* 表示在byname或者bytype的时候自动过滤掉,不需要进行调用,它是bean的一个后置处理器,会在bean的后置处理器中进行调用
* 就是这个意思
*
*/
beanFactory.ignoreDependencyInterface(EnvironmentAware.class);
beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class);
beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class);
beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class);
beanFactory.ignoreDependencyInterface(MessageSourceAware.class);
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
// BeanFactory interface not registered as resolvable type in a plain factory.
// MessageSource registered (and found for autowiring) as a bean.
/**
* spring将
* BeanFactory
* ResourceLoader
* ApplicationEventPublisher
* ApplicationContext
* 都注册到一个依赖的缓存中,其实就是一个单例池一样的,然后我们的依赖注入的核心方法
* findAutowireCandidates,就是在@AutoWired依赖注入的时候筛选bean的时候需要先byType,第一次就是从这个缓存
*resolvableDependencies中先去获取的,也就是说你在普通额bean中注入了一个privae BeanFactory beanFacatory,那么
* spring容器会给你直接从resolvableDependencies中找到然后直接给你注入
*/
beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
// Register early post-processor for detecting inner beans as ApplicationListeners.
/**
* 最后添加一个bean的后置处理器,这个后置处理器在bean初始化后会调用postProcessAfterInitialization
* 这个后置处理器在缓存中是属于最后一个,它的作用就是把实现了ApplicationListener的添加是监听器中
*/
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this));
// Detect a LoadTimeWeaver and prepare for weaving, if found.
if (beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
// Set a temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
// Register default environment beans.
//将environment直接注册成一个单例bean,environment是系统的环境变量信息
if (!beanFactory.containsLocalBean(ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment());
}
//将系统中的属性配置信息注册一个bean,bean的名字就是systemProperties
if (!beanFactory.containsLocalBean(SYSTEM_PROPERTIES_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_PROPERTIES_BEAN_NAME, getEnvironment().getSystemProperties());
}
//将系统的环境变量注册成一个单例bean,systemEnvironment
if (!beanFactory.containsLocalBean(SYSTEM_ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_ENVIRONMENT_BEAN_NAME, getEnvironment().getSystemEnvironment());
}
}
这个方法我在代码里面的注释已经很清楚了,但是需要注意的有两个地方

图(1)
和

图(2)
首先来说图(1)中,是直将spring将
BeanFactory
ResourceLoader
ApplicationEventPublisher
ApplicationContext
都注册到一个依赖的缓存中,其实就是一个单例池一样的,然后我们的依赖注入的核心方法 findAutowireCandidates,就是在@AutoWired依赖注入的时候筛选bean的时候需要先byType,第一次就是从这个缓存 resolvableDependencies中先去获取的,也就是说你在普通额bean中注入了一个privae BeanFactory beanFacatory,那么 spring容器会给你直接从resolvableDependencies中找到然后直接给你注入;
我们看下例子:
public class UserService {
@Autowired
private ApplicationContext applicationContext;
public void test(){
System.out.println(applicationContext);
}
}

可以直接注入,而且注入的缓存是从 resolvableDependencies;我们会议下spring依赖注入的时候找bean的过程的方法findAutowireCandidates,我们去看下

这个就是依赖注入的时候byType找到的bean,先是从spring启动刚开始的缓存中去获取的,所以结合前后来分析spring源码就更清晰点。
我们再来看下图(2)中的处理环境变量的,这里直接把环境变量的相关参数封装到bean,直接注册到单例池中,这里有三个bean:environment、systemProperties、systemEnvironment,这三个bean可以直接注入使用,获取系统的相关参数,比如我们看下面的例子:
比如我们在jvm的启动参数中增加-Dbmlxx=234,那么我们通过下面的例子来取到这个参数:
@Component
public class UserServiceImpl implements BaseService {
@Autowired
private Environment environment;
@Override
public void test() {
System.out.println(environment.getProperty("bmlxx"));
}
}
就可以拿到bmlxx这个参数了
registerBeanPostProcessors(beanFactory)
invokeBeanFactoryPostProcessors方法是通过启动设置了一个后置处理器
ConfigurationClassPostProcessor去执行的对配置类进行扫描,注册成一个一个的BeanDefinition,这个方法处理的非常复杂,里面包含了很多spring的扩展点,比如beanFactoryPostProcessor,@Import注解等,这个在另外的笔记中来分析,这里我们先分析启动的整个流程;这里来分析下注册bean的后置处理器,bean的后置处理器分为两部分,第一部分是spring内置的bean后置处理器,比如Spring依赖注入的内置处理器处理@AutoWired、@Resouce以及生命周期回调的方法;第二部分是处理程序员在开发过程中自己定义的后置处理器,第一部分的后置处理器spring是已经加入到了容器中了,但是第二部分的后置处理器还在beanDefinitionMap中,所以这个方法就是讲这些自定义的后置处理器拿出来然后和系统的后置处理器一起进行分组排序,最后放入到了bean后置处理器列表中:
/**
* 从已经扫描成功的beanDefinitionMap中取出bean的后置处理器,也就是说
* 在beanDefinitionMap中实现了BeanPostProcessor的BeanDefinition取出来,然后加入到了bean的后置处理器列表中
* beanPostProcessors中,当然其中还有分类
* @param beanFactory
* @param applicationContext
*/
public static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, AbstractApplicationContext applicationContext) {
/**
* 这里按照BeanPostProcessor的类型从beanDefinitionMap中取出所有的后置处理器名称
*
*/
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanPostProcessor.class, true, false);
// Register BeanPostProcessorChecker that logs an info message when
// a bean is created during BeanPostProcessor instantiation, i.e. when
// a bean is not eligible for getting processed by all BeanPostProcessors.
//计算目前容器中的bean后置处理器的个数
//beanFactory.getBeanPostProcessorCount() 是系统中现在的后置处理器个数
//postProcessorNames.length取出的刚刚从beanDefinitionMap中找到的后置处理器个数
//+1是加的下面的添加的又一个后置处理器器
int beanProcessorTargetCount = beanFactory.getBeanPostProcessorCount() + 1 + postProcessorNames.length;
// 感觉这个后置处理器没干啥事儿
beanFactory.addBeanPostProcessor(new BeanPostProcessorChecker(beanFactory, beanProcessorTargetCount));
// Separate between BeanPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
/**
* 下面就是对后置处理器进行分类,在循环的时候,这里就开始将得到的后置处理器创建出了对象,然后放入到单例池中
* 下面的分类是从实现了PriorityOrdered、Ordered和没有实现的后置处理器进行分类
* 1.首先将实现了PriorityOrdered的分一组 priorityOrderedPostProcessors
* 2.实现了Ordered的分一组 orderedPostProcessorNames
* 3.没有实现上述的两个接口的分一组 nonOrderedPostProcessorNames
* 4.如果实现了MergedBeanDefinitionPostProcessor 分一组 internalPostProcessors
*
*/
List<BeanPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<BeanPostProcessor> internalPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
priorityOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, register the BeanPostProcessors that implement PriorityOrdered.
//对实现了PriorityOrdered的后置处理器列表进行排序,排序的类就是启动的时候设置进去的一个排序比较器dependencyComparator
//就是里面有个属性order,每个后置处理器的order越小,越靠前
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
//然后注册到后置处理器中
registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors);
// Next, register the BeanPostProcessors that implement Ordered.
//下面是对实现了Ordered的进行处理,这里的循环和上面的循环都做了一件相同的事情,就是把实现了MergedBeanDefinitionPostProcessor
//的后置处理器都单独拿出来加入到了internalPostProcessors,我们知道spring的依赖注入,生命周期的回调用法的后置处理器都实现了
//MergedBeanDefinitionPostProcessor,所以这里应该是叫做内部的后置处理器单独拿出来
List<BeanPostProcessor> orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
for (String ppName : orderedPostProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
orderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
//操作同上面
sortPostProcessors(orderedPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, orderedPostProcessors);
// Now, register all regular BeanPostProcessors.
//下面的是没有实现了上面的排序相关的后置处理器拿出来循环,如果实现了MergedBeanDefinitionPostProcessor都放在
//internalPostProcessors中
List<BeanPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
for (String ppName : nonOrderedPostProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
nonOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
//将没有实现排序相关的后置处理器也注册到缓存中
registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors);
// Finally, re-register all internal BeanPostProcessors.
/**
* 这里将内部实现了MergedBeanDefinitionPostProcessor的后置处理器进行排序,排序也是通过order来的
* 如果没有order,那么就是默认的顺序
* 然后又加入到后置处理器列表中,我怎么感觉这里添加和上面的重复了
* 所以这里要理解spring的设计思路,就是说上面虽然添加了internalPostProcessors中的一个或者几个后置处理器
*
* 而这里单独那戳来又添加一次,也就是说最后的顺序就是其他后置处理器,包括程序员自己定义的排在前面,然后最后
* 再添加MergedBeanDefinitionPostProcessor类型的后置处理器,如果前面你添加了,我这里添加的时候先移除
* 然后默认添加到末尾,为什么要怎么做呢?我之前研究了spring的生命周期,spring的依赖注入和生命周期的回调都是通过
* MergedBeanDefinitionPostProcessor来实现的,也就是说依赖注入完成过后,这个bean差不多就只有初始化方法的调用了
* 那么放在最后调用的目的也就是说你前面的后置处理器先把该做的事情做完,等你们都做完该做的事情了,那么MergedBeanDefinitionPostProcessor
* 要开始做事情了,而它要做的是就是依赖注入和生命周期回调的一些处理,所以spring的设计应该是这样想的,这个只是我的个人理解
*
*/
sortPostProcessors(internalPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, internalPostProcessors);
// Re-register post-processor for detecting inner beans as ApplicationListeners,
// moving it to the end of the processor chain (for picking up proxies etc).
/**
* 这里再添加一个后置处理器ApplicationListenerDetector,这个后置处理器是不是很熟悉,好像在哪儿见过
* 的确,这个后置处理器是在refresh中的prepareBeanFactory初始化工厂的时候添加了一次,那这里为什么又要添加一次
* spring大概是这样设计的,这个后置处理器是获取系统中所有的实现了ApplicationLister的BeanDefinition添加到
* 事件监听器中,前面准备工厂的时候添加了,但是到这里spring已经经过了扫描我们定义的类过程了,那么这个时候所有的类
* 都在BeanDefinition中了,这个时候再添加就是后面调用的时候可以获取到更全的时间监听器类
* 也就是前面添加的时候,可能系统中的事件监听器还真是系统中默认的,而这里添加的就是表示包括而来系统默认的和用户添加的自定义的
* ,所以比较全,反正我这样理解的,而且你仔细看下ApplicationListenerDetector这个类,它重写了equals方法
* 也就是你每次都是new出来的对象,但是其实equals判断是一个对象,在remove的时候,虽然每次都是new的,但是其实
* 就只有一个,也就是bean的后置处理器中只会有一个这么后置处理器ApplicationListenerDetector
*
*/
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(applicationContext));
}
spring对这些后置处理器如何分组,怎么分组,怎么添加在上面的代码中每一行代码中我都写了自己的分析和理解,简单来说就是分为三组:
1.实现了PriorityOrdered一组;
2.实现了Ordered的一组;
3.没有实现上面两个接口的一组;
4.将实现了MergedBeanDefinitionPostProcessor分一组;
然后每一组在根据内部的order大小来排序,最后添加到后置处理器列表中,需要注意的是实现了MergedBeanDefinitionPostProcessor是最后添加,在笔记中已经写清楚了,实现了MergedBeanDefinitionPostProcessor基本上都是对注入或者BeanDefinition的操作,那么放在最后执行的意思就是前面的后置处理器你把自己想要做的事情尽快做完,到我这里我就要开始以来注入或者对BeanDefinition设置一些初始化和销毁方法(只是比喻),所以实现了MergedBeanDefinitionPostProcessor接口的后置处理器是放在最后的,说白了就是一个后置处理器分组然后按照分组放入列表功能。
initMessageSource
/**
* Initialize the MessageSource.
* Use parent's if none defined in this context.
* 这里是初始化国际化资源信息,在单例池中看是否有一个bean是messageSource,如果有
* 判断它是否实现了HierarchicalMessageSource,也就是父类的国际化,如果没有这个bean、
* 就创建一个默认的beanmessageSource,类型是DelegatingMessageSource
*/
protected void initMessageSource() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (beanFactory.containsLocalBean(MESSAGE_SOURCE_BEAN_NAME)) {
this.messageSource = beanFactory.getBean(MESSAGE_SOURCE_BEAN_NAME, MessageSource.class);
// Make MessageSource aware of parent MessageSource.
if (this.parent != null && this.messageSource instanceof HierarchicalMessageSource) {
HierarchicalMessageSource hms = (HierarchicalMessageSource) this.messageSource;
if (hms.getParentMessageSource() == null) {
// Only set parent context as parent MessageSource if no parent MessageSource
// registered already.
hms.setParentMessageSource(getInternalParentMessageSource());
}
}
if (logger.isTraceEnabled()) {
logger.trace("Using MessageSource [" + this.messageSource + "]");
}
}
else {
// Use empty MessageSource to be able to accept getMessage calls.
DelegatingMessageSource dms = new DelegatingMessageSource();
dms.setParentMessageSource(getInternalParentMessageSource());
this.messageSource = dms;
beanFactory.registerSingleton(MESSAGE_SOURCE_BEAN_NAME, this.messageSource);
if (logger.isTraceEnabled()) {
logger.trace("No '" + MESSAGE_SOURCE_BEAN_NAME + "' bean, using [" + this.messageSource + "]");
}
}
}
initApplicationEventMulticaster
/**
* Initialize the ApplicationEventMulticaster.
* Uses SimpleApplicationEventMulticaster if none defined in the context.
* @see org.springframework.context.event.SimpleApplicationEventMulticaster
* 这里看容器中是否有一个applicationEventMulticaster,事件注册器,如果没有
* 注册一个默认的SimpleApplicationEventMulticaster
* 就是初始化事件的发布器
*/
protected void initApplicationEventMulticaster() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (beanFactory.containsLocalBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME)) {
this.applicationEventMulticaster =
beanFactory.getBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, ApplicationEventMulticaster.class);
if (logger.isTraceEnabled()) {
logger.trace("Using ApplicationEventMulticaster [" + this.applicationEventMulticaster + "]");
}
}
else {
this.applicationEventMulticaster = new SimpleApplicationEventMulticaster(beanFactory);
beanFactory.registerSingleton(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, this.applicationEventMulticaster);
if (logger.isTraceEnabled()) {
logger.trace("No '" + APPLICATION_EVENT_MULTICASTER_BEAN_NAME + "' bean, using " +
"[" + this.applicationEventMulticaster.getClass().getSimpleName() + "]");
}
}
}
registerListeners
protected void registerListeners() {
// Register statically specified listeners first.
/**
* 这里是扫描完成过后,注册了时间发布器过后,这里把系统中所有的ApplicationListener添加到时间发布器中
*/
for (ApplicationListener<?> listener : getApplicationListeners()) {
getApplicationEventMulticaster().addApplicationListener(listener);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let post-processors apply to them!
/**
* 上面是添加了已经实现了ApplicationListener接口的bean添加到事件发布器中
* 但是下面又在获取ApplicationListener,是byType获取的,为什么这里还要去获取
* 因为容器中可能有FactoryBean,我们知道FactoryBean中的bean是需要真正调用的时候也就是getObject
* 才会返回具体的对象,估factoryBean默认是懒加载的,所以这里的ByType是获取BeanDefinition中facatorybean
* 类型是ApplicationListener的取出来然后添加到事件发布器的applicationListenerBeans中
*/
String[] listenerBeanNames = getBeanNamesForType(ApplicationListener.class, true, false);
for (String listenerBeanName : listenerBeanNames) {
getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName);
}
// Publish early application events now that we finally have a multicaster...
Set<ApplicationEvent> earlyEventsToProcess = this.earlyApplicationEvents;
this.earlyApplicationEvents = null;
if (!CollectionUtils.isEmpty(earlyEventsToProcess)) {
for (ApplicationEvent earlyEvent : earlyEventsToProcess) {
getApplicationEventMulticaster().multicastEvent(earlyEvent);
}
}
}
finishBeanFactoryInitialization(beanFactory)
这个就是创建容器的单例池,在BeanDefinition中如果处于非懒加载的,单例的bean会在这里创建,这个就是spring的bean的生命周期,在前面讲spring的生命周期已经分析的很详细了,这里就不在分析了。
finishRefresh
容器启动的最后一步,启动完成了,发布事件
protected void finishRefresh() {
// Clear context-level resource caches (such as ASM metadata from scanning).
clearResourceCaches();
// Initialize lifecycle processor for this context.
/**
* 初始化容器上下文生命周期,
* 也就是说容器启动完毕过后,提供了一个扩展点,就是在容器初始化完毕过后,会获取容器中是LiftCycle的类型bean
* 然后取出来执行里面的start方法,容器停止的时候会调用lifeCycle的stop方法
*/
initLifecycleProcessor();
// Propagate refresh to lifecycle processor first.
//初始化完成容器的LifeCycle过后,开始调用onRefresh
getLifecycleProcessor().onRefresh();
// Publish the final event.
//发布一个容器刷新完毕的事件
publishEvent(new ContextRefreshedEvent(this));
// Participate in LiveBeansView MBean, if active.
LiveBeansView.registerApplicationContext(this);
}
/**
* Initialize the LifecycleProcessor.
* Uses DefaultLifecycleProcessor if none defined in the context.
* @see org.springframework.context.support.DefaultLifecycleProcessor
* 判断容器中是否有个一个bean lifecycleProcessor,如果没有,就添加一个默认的lifecycleProcessor bean
* DefaultLifecycleProcessor
*/
protected void initLifecycleProcessor() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (beanFactory.containsLocalBean(LIFECYCLE_PROCESSOR_BEAN_NAME)) {
this.lifecycleProcessor =
beanFactory.getBean(LIFECYCLE_PROCESSOR_BEAN_NAME, LifecycleProcessor.class);
if (logger.isTraceEnabled()) {
logger.trace("Using LifecycleProcessor [" + this.lifecycleProcessor + "]");
}
}
else {
DefaultLifecycleProcessor defaultProcessor = new DefaultLifecycleProcessor();
defaultProcessor.setBeanFactory(beanFactory);
this.lifecycleProcessor = defaultProcessor;
beanFactory.registerSingleton(LIFECYCLE_PROCESSOR_BEAN_NAME, this.lifecycleProcessor);
if (logger.isTraceEnabled()) {
logger.trace("No '" + LIFECYCLE_PROCESSOR_BEAN_NAME + "' bean, using " +
"[" + this.lifecycleProcessor.getClass().getSimpleName() + "]");
}
}
}
@Override
public void onRefresh() {
startBeans(true);
this.running = true;
}
private void startBeans(boolean autoStartupOnly) {
//获取系统中实现了LifeCycle的bean,得到一个map,然后调用里面的start方法
Map<String, Lifecycle> lifecycleBeans = getLifecycleBeans();
Map<Integer, LifecycleGroup> phases = new HashMap<>();
//然后分组,搞那么复杂干嘛呀,取出来执行不就得行了,而且实现了LifeCycle还不得行,还必须是要实现SmartLifecycle才行
lifecycleBeans.forEach((beanName, bean) -> {
if (!autoStartupOnly || (bean instanceof SmartLifecycle && ((SmartLifecycle) bean).isAutoStartup())) {
int phase = getPhase(bean);
LifecycleGroup group = phases.get(phase);
if (group == null) {
group = new LifecycleGroup(phase, this.timeoutPerShutdownPhase, lifecycleBeans, autoStartupOnly);
phases.put(phase, group);
}
group.add(beanName, bean);
}
});
if (!phases.isEmpty()) {
List<Integer> keys = new ArrayList<>(phases.keySet());
Collections.sort(keys);
for (Integer key : keys) {
//调用LifeCycle中的start、方法
phases.get(key).start();
}
}
}
/**\
*调用实现了LifeCycle类的中的star方法
*/
public void start() {
if (this.members.isEmpty()) {
return;
}
if (logger.isDebugEnabled()) {
logger.debug("Starting beans in phase " + this.phase);
}
Collections.sort(this.members);
for (LifecycleGroupMember member : this.members) {
//调用
doStart(this.lifecycleBeans, member.name, this.autoStartupOnly);
}
}
上面只有一个地方可以说下就是容器的生命周期开始的一些处理,就是说容器启动完成了,可以创建一个生命周期的处理类来高速你容器启动完毕了,所以简单来说就是可以创建一个类来监听容器启动完成通知你的操作,比如:
@Component
public class Beanfinish implements SmartLifecycle {
@Override
public void start() {
System.out.println("容器启动完成通知...");
}
@Override
public void stop() {
}
@Override
public boolean isRunning() {
return false;
}
@Override
public boolean isAutoStartup() {
return true;
}
}

上面就是spring大概的启动过程,非常枯燥,启动过程就是一个流程化的东西
最后附上spring容器启动的整体过程
