c++ 不插入重复元素但也不排序_面试时写不出排序算法?看这篇就够了
小Hub领读:
本文主要详细讲述常见的八种排序算法的思想、实现以及复杂度。包括冒泡排序、快速排序、插入排序、希尔排序等等,文章讲解非常详细!
作者:静默虚空
https://juejin.im/post/5cb6b8f551882532c334bcf2
本文已归档到:「blog」:https://github.com/dunwu/blog/tree/master/source/_posts/algorithm
本文中的示例代码已归档到:「algorithm-tutorial」:https://github.com/dunwu/algorithm-tutorial/blob/master/codes/algorithm/src/test/java/io/github/dunwu/algorithm/sort/SortStrategyTest.java
冒泡排序
要点
冒泡排序是一种交换排序。
什么是交换排序呢?
交换排序:两两比较待排序的关键字,并交换不满足次序要求的那对数,直到整个表都满足次序要求为止。
算法思想
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢 “浮” 到数列的顶端,故名。
假设有一个大小为 N 的无序序列。冒泡排序就是要每趟排序过程中通过两两比较,找到第 i 个小(大)的元素,将其往上排。

以上图为例,演示一下冒泡排序的实际流程:
假设有一个无序序列 {4. 3. 1. 2, 5}
第一趟排序:通过两两比较,找到第一小的数值 1 ,将其放在序列的第一位。
第二趟排序:通过两两比较,找到第二小的数值 2 ,将其放在序列的第二位。
第三趟排序:通过两两比较,找到第三小的数值 3 ,将其放在序列的第三位。
至此,所有元素已经有序,排序结束。
要将以上流程转化为代码,我们需要像机器一样去思考,不然编译器可看不懂。
假设要对一个大小为 N 的无序序列进行升序排序(即从小到大)。
每趟排序过程中需要通过比较找到第 i 个小的元素。
所以,我们需要一个外部循环,从数组首端 (下标 0) 开始,一直扫描到倒数第二个元素(即下标 N - 2) ,剩下最后一个元素,必然为最大。
假设是第 i 趟排序,可知,前 i-1 个元素已经有序。现在要找第 i 个元素,只需从数组末端开始,扫描到第 i 个元素,将它们两两比较即可。
所以,需要一个内部循环,从数组末端开始(下标 N - 1),扫描到 (下标 i + 1)。
核心代码
public void bubbleSort(int[] list) {
算法分析
冒泡排序算法的性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 交换排序 |
| 排序方法 | 冒泡排序 |
| 时间复杂度平均情况 | O(N2) |
| 时间复杂度最坏情况 | O(N3) |
| 时间复杂度最好情况 | O(N) |
| 空间复杂度 | O(1) |
| 稳定性 | 稳定 |
| 复杂性 | 简单 |
时间复杂度
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数 C 和记录移动次数 M 均达到最小值:Cmin = N - 1, Mmin = 0。所以,冒泡排序最好时间复杂度为 O(N)。
若初始文件是反序的,需要进行 N -1 趟排序。每趟排序要进行 N - i 次关键字的比较 (1 ≤ i ≤ N - 1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
Cmax = N(N-1)/2 = O(N2)
Mmax = 3N(N-1)/2 = O(N2)
冒泡排序的最坏时间复杂度为 O(N2)。
因此,冒泡排序的平均时间复杂度为 O(N2)。
总结起来,其实就是一句话:当数据越接近正序时,冒泡排序性能越好。
算法稳定性
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。
所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
优化
对冒泡排序常见的改进方法是加入标志性变量 exchange,用于标志某一趟排序过程中是否有数据交换。
如果进行某一趟排序时并没有进行数据交换,则说明所有数据已经有序,可立即结束排序,避免不必要的比较过程。
核心代码
// 对 bubbleSort 的优化算法示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
快速排序
要点
快速排序是一种交换排序。
快速排序由 C. A. R. Hoare 在 1962 年提出。
算法思想
它的基本思想是:
通过一趟排序将要排序的数据分割成独立的两部分:分割点左边都是比它小的数,右边都是比它大的数。
然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
详细的图解往往比大堆的文字更有说明力,所以直接上图:

上图中,演示了快速排序的处理过程:
初始状态为一组无序的数组:2、4、5、1、3。
经过以上操作步骤后,完成了第一次的排序,得到新的数组:1、2、5、4、3。
新的数组中,以 2 为分割点,左边都是比 2 小的数,右边都是比 2 大的数。
因为 2 已经在数组中找到了合适的位置,所以不用再动。
2 左边的数组只有一个元素 1,所以显然不用再排序,位置也被确定。(注:这种情况时,left 指针和 right 指针显然是重合的。因此在代码中,我们可以通过设置判定条件 left 必须小于 right,如果不满足,则不用排序了)。
而对于 2 右边的数组 5、4、3,设置 left 指向 5,right 指向 3,开始继续重复图中的一、二、三、四步骤,对新的数组进行排序。
核心代码
public int division(int[] list, int left, int right) {
算法分析
快速排序算法的性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 交换排序 |
| 排序方法 | 快速排序 |
| 时间复杂度平均情况 | O(Nlog2N) |
| 时间复杂度最坏情况 | O(N2) |
| 时间复杂度最好情况 | O(Nlog2N) |
| 空间复杂度 | O(Nlog2N) |
| 稳定性 | 不稳定 |
| 复杂性 | 较复杂 |
时间复杂度
当数据有序时,以第一个关键字为基准分为两个子序列,前一个子序列为空,此时执行效率最差。
而当数据随机分布时,以第一个关键字为基准分为两个子序列,两个子序列的元素个数接近相等,此时执行效率最好。
所以,数据越随机分布时,快速排序性能越好;数据越接近有序,快速排序性能越差。
空间复杂度
快速排序在每次分割的过程中,需要 1 个空间存储基准值。而快速排序的大概需要 Nlog2N 次的分割处理,所以占用空间也是 Nlog2N 个。
算法稳定性
在快速排序中,相等元素可能会因为分区而交换顺序,所以它是不稳定的算法。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
插入排序
要点
直接插入排序是一种最简单的插入排序。
插入排序:每一趟将一个待排序的记录,按照其关键字的大小插入到有序队列的合适位置里,知道全部插入完成。
算法思想
在讲解直接插入排序之前,先让我们脑补一下我们打牌的过程。

先拿一张 5 在手里,
再摸到一张 4,比 5 小,插到 5 前面,
摸到一张 6,嗯,比 5 大,插到 5 后面,
摸到一张 8,比 6 大,插到 6 后面,
。。。
最后一看,我靠,凑到的居然是同花顺,这下牛逼大了。
以上的过程,其实就是典型的直接插入排序,每次将一个新数据插入到有序队列中的合适位置里。
很简单吧,接下来,我们要将这个算法转化为编程语言。
假设有一组无序序列 R0, R1, ... , RN-1。
我们先将这个序列中下标为 0 的元素视为元素个数为 1 的有序序列。
然后,我们要依次把 R1, R2, ... , RN-1 插入到这个有序序列中。所以,我们需要一个外部循环,从下标 1 扫描到 N-1 。
接下来描述插入过程。假设这是要将 Ri 插入到前面有序的序列中。由前面所述,我们可知,插入 Ri 时,前 i-1 个数肯定已经是有序了。
所以我们需要将 Ri 和 R0 ~ Ri-1 进行比较,确定要插入的合适位置。这就需要一个内部循环,我们一般是从后往前比较,即从下标 i-1 开始向 0 进行扫描。
核心代码
public void insertSort(int[] list) {
算法分析
直接插入排序的算法性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 插入排序 |
| 排序方法 | 直接插入排序 |
| 时间复杂度平均情况 | O(N2) |
| 时间复杂度最坏情况 | O(N2) |
| 时间复杂度最好情况 | O(N) |
| 空间复杂度 | O(1) |
| 稳定性 | 稳定 |
| 复杂性 | 简单 |
时间复杂度
当数据正序时,执行效率最好,每次插入都不用移动前面的元素,时间复杂度为 O(N)。
当数据反序时,执行效率最差,每次插入都要前面的元素后移,时间复杂度为 O(N2)。
所以,数据越接近正序,直接插入排序的算法性能越好。
空间复杂度
由直接插入排序算法可知,我们在排序过程中,需要一个临时变量存储要插入的值,所以空间复杂度为 1 。
算法稳定性
直接插入排序的过程中,不需要改变相等数值元素的位置,所以它是稳定的算法。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
希尔排序
要点
希尔 (Shell) 排序又称为缩小增量排序,它是一种插入排序。它是直接插入排序算法的一种威力加强版。
该方法因 DL.Shell 于 1959 年提出而得名。
算法思想
希尔排序的基本思想是:
把记录按步长 gap 分组,对每组记录采用直接插入排序方法进行排序。随着步长逐渐减小,所分成的组包含的记录越来越多,当步长的值减小到 1 时,整个数据合成为一组,构成一组有序记录,则完成排序。
我们来通过演示图,更深入的理解一下这个过程。

在上面这幅图中:
初始时,有一个大小为 10 的无序序列。
在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。
接下来,按照直接插入排序的方法对每个组进行排序。
在 ** 第二趟排序中 **,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。
按照直接插入排序的方法对每个组进行排序。
在第三趟排序中,再次把 gap 缩小一半,即 gap3 = gap2 / 2 = 1。这样相隔距离为 1 的元素组成一组,即只有一组。
按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
需要注意一下的是,图中有两个相等数值的元素 5 和 5 。我们可以清楚的看到,在排序过程中,两个元素位置交换了。
所以,希尔排序是不稳定的算法。
核心代码
public void shellSort(int[] list) {
算法分析
希尔排序的算法性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 插入排序 |
| 排序方法 | 希尔排序 |
| 时间复杂度平均情况 | O(Nlog2N) |
| 时间复杂度最坏情况 | O(N1.5) |
| 时间复杂度最好情况 | |
| 空间复杂度 | O(1) |
| 稳定性 | 不稳定 |
| 复杂性 | 较复杂 |
时间复杂度
步长的选择是希尔排序的重要部分。只要最终步长为 1 任何步长序列都可以工作。
算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为 1 进行排序。当步长为 1 时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell 最初建议步长选择为 N/2 并且对步长取半直到步长达到 1。虽然这样取可以比 O(N2) 类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长 5 进行了排序然后再以步长 3 进行排序,那么该数列不仅是以步长 3 有序,而且是以步长 5 有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。
已知的最好步长序列是由 Sedgewick 提出的 (1, 5, 19, 41, 109,...),该序列的项来自这两个算式。
这项研究也表明 “比较在希尔排序中是最主要的操作,而不是交换。” 用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
算法稳定性
由上文的希尔排序算法演示图即可知,希尔排序中相等数据可能会交换位置,所以希尔排序是不稳定的算法。
直接插入排序和希尔排序的比较
直接插入排序是稳定的;而希尔排序是不稳定的。
直接插入排序更适合于原始记录基本有序的集合。
希尔排序的比较次数和移动次数都要比直接插入排序少,当 N 越大时,效果越明显。
在希尔排序中,增量序列 gap 的取法必须满足:** 最后一个步长必须是 1 。**
直接插入排序也适用于链式存储结构;希尔排序不适用于链式结构。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
简单选择排序
要点
简单选择排序是一种选择排序。
选择排序:每趟从待排序的记录中选出关键字最小的记录,顺序放在已排序的记录序列末尾,直到全部排序结束为止。
算法思想
从待排序序列中,找到关键字最小的元素;
如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
从余下的 N - 1 个元素中,找出关键字最小的元素,重复 1、2 步,直到排序结束。
如图所示,每趟排序中,将当前 ** 第 i 小的元素放在位置 i ** 上。
核心代码

算法分析
简单选择排序算法的性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 选择排序 |
| 排序方法 | 简单选择排序 |
| 时间复杂度平均情况 | O(N2) |
| 时间复杂度最坏情况 | O(N2) |
| 时间复杂度最好情况 | O(N2) |
| 空间复杂度 | O(1) |
| 稳定性 | 不稳定 |
| 复杂性 | 简单 |
时间复杂度
简单选择排序的比较次数与序列的初始排序无关。假设待排序的序列有 N 个元素,则 ** 比较次数总是 N (N - 1) / 2 **。
而移动次数与序列的初始排序有关。当序列正序时,移动次数最少,为 0.
当序列反序时,移动次数最多,为 3N (N - 1) / 2。
所以,综合以上,简单排序的时间复杂度为 O(N2)。
空间复杂度
简单选择排序需要占用一个临时空间,在交换数值时使用。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
堆排序
要点
在介绍堆排序之前,首先需要说明一下,堆是个什么玩意儿。
堆是一棵顺序存储的完全二叉树。
其中每个结点的关键字都不大于其孩子结点的关键字,这样的堆称为小根堆。其中每个结点的关键字都不小于其孩子结点的关键字,这样的堆称为大根堆。举例来说,对于 n 个元素的序列 {R0, R1, ... , Rn} 当且仅当满足下列关系之一时,称之为堆:
Ri <= R2i+1 且 Ri <= R2i+2 (小根堆)
Ri >= R2i+1 且 Ri >= R2i+2 (大根堆)
其中 i=1,2,…,n/2 向下取整;
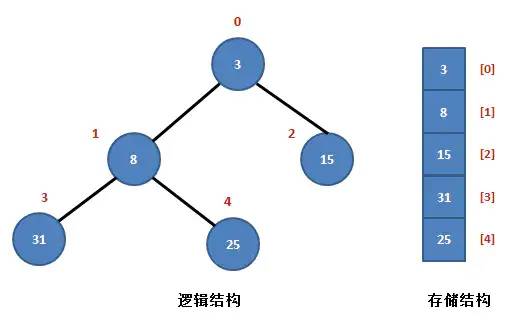
如上图所示,序列 R{3, 8,15, 31, 25} 是一个典型的小根堆。
堆中有两个父结点,元素 3 和元素 8。
元素 3 在数组中以 R[0] 表示,它的左孩子结点是 R[1],右孩子结点是 R[2]。
元素 8 在数组中以 R[1] 表示,它的左孩子结点是 R[3],右孩子结点是 R[4],它的父结点是 R[0]。可以看出,它们满足以下规律:
设当前元素在数组中以 R[i] 表示,那么,
它的左孩子结点是:R[2*i+1];
它的右孩子结点是:R[2*i+2];
它的父结点是:R[(i-1)/2];
R[i] <= R[2*i+1] 且 R[i] <= R[2i+2]。
算法思想
首先,按堆的定义将数组 R[0..n] 调整为堆(这个过程称为创建初始堆),交换 R[0] 和 R[n];
然后,将 R[0..n-1] 调整为堆,交换 R[0] 和 R[n-1];
如此反复,直到交换了 R[0] 和 R[1] 为止。
以上思想可归纳为两个操作:
根据初始数组去构造初始堆(构建一个完全二叉树,保证所有的父结点都比它的孩子结点数值大)。
每次交换第一个和最后一个元素,输出最后一个元素(最大值),然后把剩下元素重新调整为大根堆。
当输出完最后一个元素后,这个数组已经是按照从小到大的顺序排列了。
先通过详细的实例图来看一下,如何构建初始堆。
设有一个无序序列 {1, 3,4, 5, 2, 6, 9, 7, 8, 0}。

构造了初始堆后,我们来看一下完整的堆排序处理:
还是针对前面提到的无序序列 {1,3, 4, 5, 2, 6, 9, 7, 8, 0} 来加以说明。

相信,通过以上两幅图,应该能很直观的演示堆排序的操作处理。
核心代码
public void HeapAdjust(int[] array, int parent, int length) {
算法分析
堆排序算法的总体情况
| 参数 | 结果 |
|---|---|
| 排序类别 | 选择排序 |
| 排序方法 | 堆排序 |
| 时间复杂度平均情况 | O(nlog2n) |
| 时间复杂度最坏情况 | O(nlog2n) |
| 时间复杂度最好情况 | O(nlog2n) |
| 空间复杂度 | O(1) |
| 稳定性 | 不稳定 |
| 复杂性 | 较复杂 |
时间复杂度
堆的存储表示是顺序的。因为堆所对应的二叉树为完全二叉树,而完全二叉树通常采用顺序存储方式。
当想得到一个序列中第 k 个最小的元素之前的部分排序序列,最好采用堆排序。
因为堆排序的时间复杂度是 O(n+klog2n),若 k ≤ n/log2n,则可得到的时间复杂度为 O(n)。
算法稳定性
堆排序是一种不稳定的排序方法。
因为在堆的调整过程中,关键字进行比较和交换所走的是该结点到叶子结点的一条路径,
因此对于相同的关键字就可能出现排在后面的关键字被交换到前面来的情况。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
归并排序
要点
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用 ** 分治法(Divide and Conquer)** 的一个非常典型的应用。
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
算法思想
将待排序序列 R[0...n-1] 看成是 n 个长度为 1 的有序序列,将相邻的有序表成对归并,得到 n/2 个长度为 2 的有序表;将这些有序序列再次归并,得到 n/4 个长度为 4 的有序序列;如此反复进行下去,最后得到一个长度为 n 的有序序列。
综上可知:
归并排序其实要做两件事:
“分解”——将序列每次折半划分。
“合并”——将划分后的序列段两两合并后排序。
我们先来考虑第二步,如何合并?
在每次合并过程中,都是对两个有序的序列段进行合并,然后排序。
这两个有序序列段分别为 R[low, mid] 和 R[mid+1, high]。
先将他们合并到一个局部的暂存数组 R2 中,带合并完成后再将 R2 复制回 R 中。
为了方便描述,我们称 R[low, mid] 第一段,R[mid+1, high] 为第二段。
每次从两个段中取出一个记录进行关键字的比较,将较小者放入 R2 中。最后将各段中余下的部分直接复制到 R2 中。
经过这样的过程,R2 已经是一个有序的序列,再将其复制回 R 中,一次合并排序就完成了。
核心代码
public void Merge(int[] array, int low, int mid, int high) {
掌握了合并的方法,接下来,让我们来了解如何分解。

在某趟归并中,设各子表的长度为 gap,则归并前 R[0...n-1] 中共有 n/gap 个有序的子表:R[0...gap-1], R[gap...2*gap-1], ... , R[(n/gap)*gap ... n-1]。
调用 Merge 将相邻的子表归并时,必须对表的特殊情况进行特殊处理。
若子表个数为奇数,则最后一个子表无须和其他子表归并(即本趟处理轮空):若子表个数为偶数,则要注意到最后一对子表中后一个子表区间的上限为 n-1。
核心代码
public void MergePass(int[] array, int gap, int length) {
算法分析
归并排序算法的性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 归并排序 |
| 排序方法 | 归并排序 |
| 时间复杂度平均情况 | O(nlog2n) |
| 时间复杂度最坏情况 | O(nlog2n) |
| 时间复杂度最好情况 | O(nlog2n) |
| 空间复杂度 | O(n) |
| 稳定性 | 稳定 |
| 复杂性 | 较复杂 |
时间复杂度
归并排序的形式就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的可以得出它的时间复杂度是 O(n*log2n)。
空间复杂度
由前面的算法说明可知,算法处理过程中,需要一个大小为 n 的临时存储空间用以保存合并序列。
算法稳定性
在归并排序中,相等的元素的顺序不会改变,所以它是稳定的算法。
归并排序和堆排序、快速排序的比较
若从空间复杂度来考虑:首选堆排序,其次是快速排序,最后是归并排序。
若从稳定性来考虑,应选取归并排序,因为堆排序和快速排序都是不稳定的。
若从平均情况下的排序速度考虑,应该选择快速排序。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
基数排序
要点
基数排序与本系列前面讲解的七种排序方法都不同,它不需要比较关键字的大小。
它是根据关键字中各位的值,通过对排序的 N 个元素进行若干趟 “分配” 与“收集”来实现排序的。
不妨通过一个具体的实例来展示一下,基数排序是如何进行的。
设有一个初始序列为: R {50, 123, 543, 187, 49, 30,0, 2, 11, 100}。
我们知道,任何一个阿拉伯数,它的各个位数上的基数都是以 0~9 来表示的。
所以我们不妨把 0~9 视为 10 个桶。
我们先根据序列的个位数的数字来进行分类,将其分到指定的桶中。例如:R[0] = 50,个位数上是 0,将这个数存入编号为 0 的桶中。

分类后,我们在从各个桶中,将这些数按照从编号 0 到编号 9 的顺序依次将所有数取出来。
这时,得到的序列就是个位数上呈递增趋势的序列。
按照个位数排序:{50, 30, 0, 100, 11, 2, 123,543, 187, 49}。
接下来,可以对十位数、百位数也按照这种方法进行排序,最后就能得到排序完成的序列。
算法分析
基数排序的性能
| 参数 | 结果 |
|---|---|
| 排序类别 | 基数排序 |
| 排序方法 | 基数排序 |
| 时间复杂度平均情况 | O(d(n+r)) |
| 时间复杂度最坏情况 | O(d(n+r)) |
| 时间复杂度最好情况 | O(d(n+r)) |
| 空间复杂度 | O(n+r) |
| 稳定性 | 稳定 |
| 复杂性 | 较复杂 |
时间复杂度
通过上文可知,假设在基数排序中,r 为基数,d 为位数。则基数排序的时间复杂度为 O(d(n+r))。
我们可以看出,基数排序的效率和初始序列是否有序没有关联。
空间复杂度
在基数排序过程中,对于任何位数上的基数进行 “装桶” 操作时,都需要 n+r 个临时空间。
算法稳定性
在基数排序过程中,每次都是将当前位数上相同数值的元素统一 “装桶”,并不需要交换位置。所以基数排序是稳定的算法。
示例代码
我的 Github 测试例
样本包含:数组个数为奇数、偶数的情况;元素重复或不重复的情况。且样本均为随机样本,实测有效。
(完)
MarkerHub文章索引:
https://github.com/MarkerHub/JavaIndex
【推荐阅读】
图解Spring解决循环依赖,认清IOC!
是真的猛!SQL 语法速成手册
面试官:BigDecimal一定不会丢失精度吗?
通俗易懂讲布隆过滤器
高并发之API接口,分布式,防刷限流,如何做?
