python中的xpath爬虫实例,新人处女作!!!
首先声明,自己算是小白,还是偏感性女性思维,刚接触python没有多久,所以以下文字中有不专业的地方,请多多指出,不吝赐教。我是学了正则和bs4然后学的xpath,其实我开始并不想做笔记,但是发现自己学完了之后就全忘记了,特意做一下笔记。我着重讲实例。
求点赞、评论、关注!!!!!!
可以先看一下xpath的基本逻辑:
#xpath解析原理:
-1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
-2.调用etree对象的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
#环境的安装:
-pip install lxml
#如何实例化一个etree对象 :from lxml import etree
-1.将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
-2.可以将从互联网上获取的源码数据加载到该对象中:
etree.parse(filePath)
#xpath表达式
-/:表示从根节点开始定位,表示的是一个层级
-//表示多个层级,可以表示从任意位置开始定位
-属性定位://div[@class='song'] tag[@attrName='attrValue']
-索引定位://div[@class='song']/p[3] 索引是从1开始的
-取文本:/text()
-取属性:/@attrName ==>img/@src
1.第一个案例:爬取链家的二手房信息,要求能输出二手房页面的二手房标题和价钱
--先导入模块,发起网络请求,得到这种二手房列表界面,然后把网页etree对象化,再调用xpath方法
import requests
from lxml import etree
if __name__=='__main__':
# 需求:爬取链家的二手房信息
# 1.爬取页面源码数据
url1='https://sh.lianjia.com/ershoufang/pudong/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
response=requests.get(url1,headers)
lianjia_text=response.text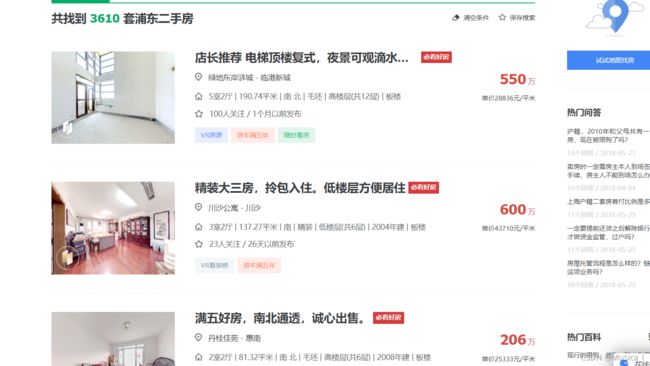
--注意看xpath里面怎么写的,你看一下网页的源代码,会发现这些二手房的一套信息全都以li标签的形式存储,放在了ul的标签里面 。
# 数据解析
tree=etree.HTML(lianjia_text)
print(lianjia_text)
li_list=tree.xpath('//ul[@class="sellListContent"]/li') 这是一个列表,里面存放着所有的li标签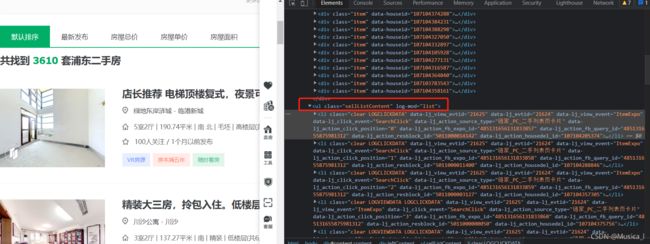
--后面我们想获得二手房的名称,我们其实只需要在li标签里面找就可以了,先遍历这些li标签, 在li标签里再次调用这个xpath方法(老实说,其实我也不是很明白为什么能直接调用这个方法,如果你可以解释,记得留言,如果你不会,你可以问问会的,记住就可以了),注意加个' ./ ',这样就表示进入下一级了,然后依次找,就能发现二手房名称在a标签里面,同理找到价格,索引是从1开始。
# 存储的就是li标签对象
with open('.lianjia.html','w',encoding='utf-8') as hp:
hp.write(lianjia_text)
fp=open('./lianjia.txt','w',encoding='utf-8')
for li in li_list:
title=li.xpath('./div[1]/div[1]/a/text()')[0]
price=li.xpath('./div[1]/div[6]/div[1]/span/text()')[0]
print(title)
fp.write(title+price+' 万 '+'\n')--最后进行持久化存储即可,打出这个,就完成了,这个是初级的,也很简单,可以照着做一下。关于持久化存储,代码可以记一下,理解了最好。

2.第二个案例:爬取网站上美女的图片https://pic.netbian.com/4kmeinv/,并且下载到文件夹
--同上,先网络请求,然后对请求好的页面进行etree对象实例化,用以调用xpath方法
import requests
from lxml import etree
import os
# 需求:爬取https://pic.netbian.com/4kmeinv/的图片
if __name__=='__main__':
url1='https://pic.netbian.com/4kmeinv/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
response = requests.get(url1, headers)
# 手动设定响应数据的编码格式,处理中文乱码
response.encoding='gbk'
meinv_text = response.text
# 数据解析:src的属性值,alt属性
tree=etree.HTML(meinv_text)
--其实你会发现代码不是'utf-8',因为会出现乱码,把它换成''gbk试一试
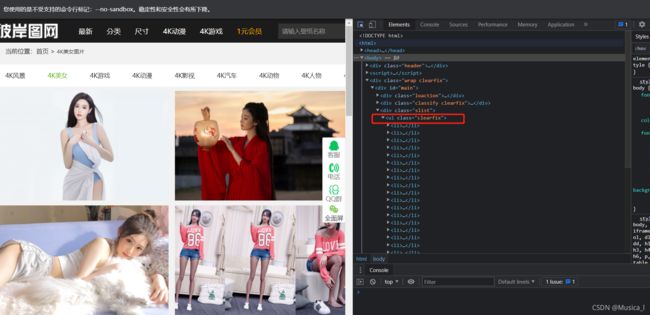
--接着你会发现这些个图片全都独立在li标签里面,又是在ul下面,所以按照之前的操作,先调用xpath方法生成个列表,然后遍历列表元素,然后列表里面再去定位图片的网址(img)(注意是不完整的,你得自己加上‘http’那些,以便后面发起请求)以及图片名称(alt)
--其实重点在于,我们还需要发起第二次请求,去得到这个图片的数据。
在遍历下再起发起请求,可以获得图片数据,既然得到了图片的数据内容,知道了图片的名称,接下来就是存储啦。由于图片是二进制格式,所以是content,写入是‘wb’,文本的话就是html,写入是‘w’。存储就是创个文件夹,然后图片保存是通过文件夹的路径+图片名称,然后把图片数据写进去,就成功啦!
li_list=tree.xpath('//div[@class="slist"]/ul/li')
# 创建一个文件夹
if not os.path.exists('./meinv_piclibs'):
os.mkdir('./meinv_piclibs')
for li in li_list:
img_url='https://pic.netbian.com'+li.xpath('./a/img/@src')[0] 如果不加这个索引,它其实是一个列表,你可以试一下
img_name=li.xpath('./a/img/@alt')[0]+'.jpg'
response2=requests.get(img_url,headers)
# 请求图片持久化存储
img_data=response2.content
img_path='meinv_piclibs/'+img_name
with open(img_path,'wb')as fp:
fp.write(img_data)
print(img_name,'下载成功!')
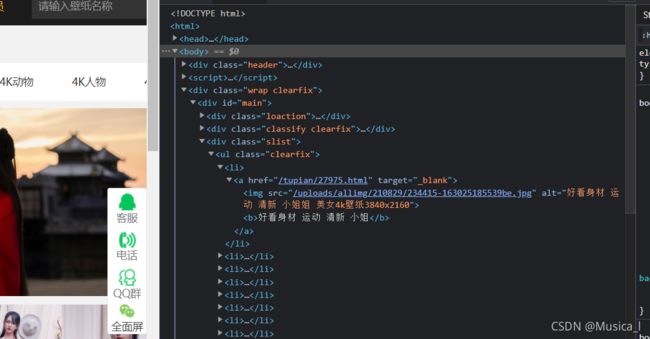
--最后效果是这个亚子

--我也喜欢美女!!!!!!!!!!!!
3.第三个案例:令我头秃的案例 去站长之家下载免费PPT素材
在网址https://sc.chinaz.com/ppt/free.html中下载免费PPT
嗯哼,看到这个,你是不是觉得很简单,没那么难,其实你会发现,涉及到下面3个页面,三次网络请求。看到这里,你也觉得没这么难,于是开开心心打算十分钟搞定。呵呵,幼稚!
#1

#2

#3
--其实,万变不离其宗,还是一样的方法,然而,实操的时候我遇到很多问题。
--我的思路就是和上面一样的思路,还是调用xpath方法,然后找到这些素材被封装的标签,然后我就找到了下图这个,它其实和上面的ul是同一个功能,所以我把它写下来并且打印了一下,div_list=tree.xpath('//div[@class="ppt-list masonry"]/div') 结果居然是个空列表,后来问人说是class有空格容易识别不出来,所以干脆从祖宗一代代传下来,这个耽误我好长时间,而且它和别的不一样,就是索引它不认!!!!!!!而且开始到现在我都不知道什么原因,是一步步调试出来的。

import requests
from lxml import etree
import os
from keras.utils.data_utils import get_file
import zipfile
import os
第一次网络请求
if __name__=='__main__':
url1='https://sc.chinaz.com/ppt/free.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
response = requests.get(url1, headers)
response.encoding='utf-8'
page_text=response.text
tree=etree.HTML(page_text)
div_list=tree.xpath('/html/body/div[3]/div[4]/div')此时得到了div的列表
if not os.path.exists('./ppt_piclibs'):
os.mkdir('./ppt_piclibs')
if not os.path.exists('./ppt2_piclibs'):
os.mkdir('./ppt2_piclibs')
遍历一下列表
for div in div_list:
a和b是我用来调试的,放在这里希望给你思路
a= div.xpath('./div')
b= div.xpath('./div/a')
我得到了新的url地址,为了做第二次网络请求;得到了名称
new_url='https://sc.chinaz.com'+div.xpath('./div/a/@href')[0]
name=div.xpath('./div/a/@title')[0]
print(new_url)
print(name)
response2 = requests.get(new_url, headers)
response2.encoding='utf-8'
ppt_text = response2.text
为了第三次网络请求能顺利进行,我先看看第二次网络请求有没有问题
ppt_path='ppt_piclibs/'+name+'.html'
with open(ppt_path,'w',encoding='utf-8') as fp:
fp.write(ppt_text)
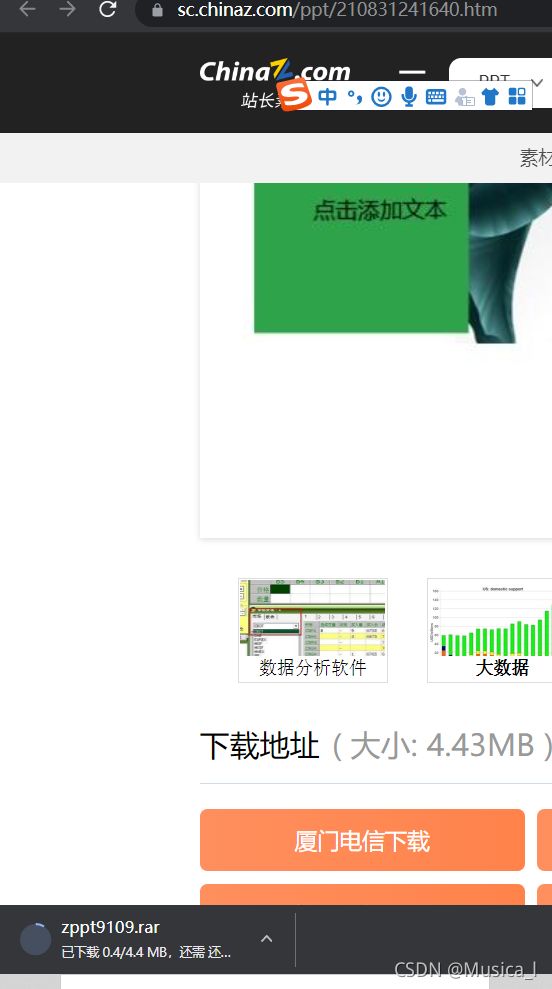
--第二次网络请求的确得到了各个简历点进去的详情页,但是加载的不完整,可是足够看源代码了
#文件夹下的样子
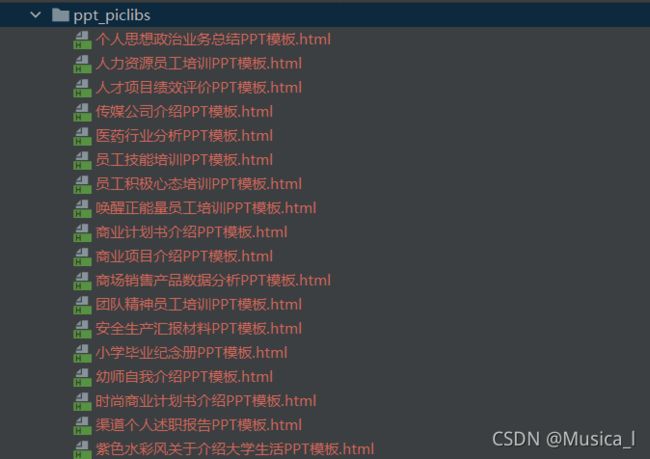
#文件夹运行的样子
#看下源代码
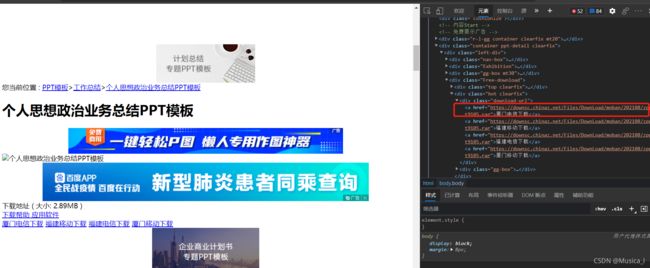
--思路还是一样的呀,再看看上面加载页面的源代码,我再次用xpath定位到‘厦门电信下载’,其实你都不用遍历了,这个直接找到再网络请求就成了。
tree=etree.HTML(ppt_text)
c=tree.xpath('//div[@class="Free-download"]/div[2]/div[1]/a/@href')
final_url=tree.xpath('//div[@class="Free-download"]/div[2]/div[1]/a/@href')[0]
print(final_url)
response3=requests.get(new_url,headers)
final_data=response3.text
final_path = 'ppt2_piclibs/' + name + 'rar'
print(final_path)
dowloadFile(final_url, name + '.rar')
print(name)
--然后就是存储啦,说实话存储是最复杂的,还要调用很麻烦的模块,下载也很慢。你得定义这个函数,实际写代码,这个要定义在前面,因为我发现定义在后面无法调用。这个方法是搜索别人文章看到的,有更好的写法最好。
# 下载代码
def dowloadFile(url,name):
file=name
dir='D:/code/python/star/first/爬虫/ppt2_piclibs'
try:
path = get_file(fname=file,
origin=url, cache_subdir=dir) #
print('download---'+path)
except:
print('Error')
raise
pass
总结:OK就到这里了,我可能讲的不够清晰,但是我就是这么理解的了。其实写爬虫我觉得重要的是思路,要有清晰地思路和运用工具的能力,很多时候你发现为什么和书上讲的不一样,这个时候要会调试,尝试去解决问题。
另外,这个内容是我在B站学习了https://www.bilibili.com/video/BV1ha4y1H7sx?p=28 课程后写的,可以听一下老师的讲解,谢谢!
求点赞啊,新人第一篇文章!!!!!!!!