你知道TCP的重传机制、滑动窗口、流量控制、拥塞控制吗?
TCP的四大机制
- 一、重传机制
-
- 超时重传
-
- TCP以下两种情况会发生超时重传
- 超时时间的设置
- 连续发生超时重传
- 快速重传
-
- SACK
- Duplicate SACK
-
- D-SACK的好处
- 二、滑动窗口
-
- 累计应答模式
- 窗口大小决定方
- 发送方的窗口
- 接收方的窗口
- 三、流量控制
-
- 操作系统缓冲区与滑动窗口的关系
- 窗口关闭
-
- 窗口关闭存在的问题
-
- 死锁
-
- 窗口探测
- 糊涂窗口综合症
-
- 避免小窗口通知
-
- 接收方策略
- 发送方策略
- 四、拥塞控制
-
- 拥塞窗口
- 拥塞控制算法
-
- 慢启动
- 拥塞避免算法
- 拥塞发生算法
-
- 发生超时重传的拥塞发生算法
- 发生快速重传的拥塞发生算法
- 快速恢复
- 五、TCP延迟确认
一、重传机制
TCP针对数据包丢失的情况,会用重传机制解决。
超时重传
超时重传:就是在发送数据时,设定⼀个定时器,当超过指定的时间后,没有收到对方的ACK确认应答报文,就会重发该数据。

TCP以下两种情况会发生超时重传
- 数据包丢失
- ACK应答报文丢失
超时时间的设置
RTT:包的往返时间。
超时重传时间是以RTO (Retransmission Timeout 超时重传时间)表示。
- 当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差
- 当超时时间RTO较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
超时重传时间RTO的值应该略大于报文往返RTT的值。
但是实际上,网络是波动的,所以RTT也是在变化的,那么也意味着RTO也应该是动态变化的。为此TCP通过采用数据进行处理
- 采样RTT的时间,加权平均,算出一个平滑的RTT的值,这个值也在不断变化
- 采样RTT的波动范围。
连续发生超时重传
如果超时重发的数据,再次超时的时候,⼜需要重传的时候,TCP的策略是超时间隔加倍。 也就是每当遇到⼀次超时重传的时候,都会将下⼀次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
快速重传
快速重传的工作方式是当收到三个相同的ACK报文时,会在定时器过期之前,重传丢失的报文段。
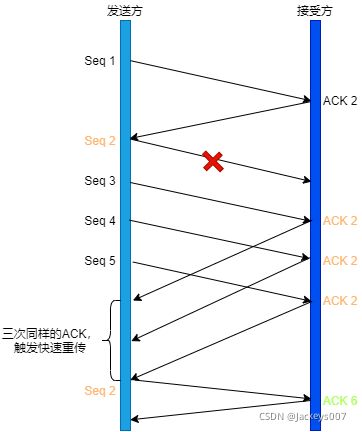
SACK
在TCP头部选项字段里加⼀个SACK的东西,它可以将缓存的地图发送给发送方,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。

如果要支持SACK ,必须双⽅都要支持。在 Linux 下,可以通过 net.ipv4.tcp_sack参数打开这个功能(Linux 2.4 后默认打开)。
Duplicate SACK
Duplicate SACK称D-SACK ,其主要使用了SACK来告诉发送方有哪些数据被重复接收了。

D-SACK的好处
- 可以方发送方知道,是发出的包丢了,还是接受方回应的ACK的包丢了
- 可以知道发送方的数据包被网络延迟了
- 可以知道网络中是不是把发送方的数据包给复制了
在 Linux 下可以通过 net.ipv4.tcp_dsack 参数开启/关闭这个功能(Linux 2.4 后默认打开)
二、滑动窗口
数据包的往返时间越长,通信的效率就越低。那么有了窗口,就可以指定窗口大小,窗口大小就是指无需等待确认应答,而可以继续发送数据的最⼤值。
累计应答模式
假设窗口大小为3个TCP 段,那么发送方就可以连续发送3个TCP段,并且中途若有ACK丢失,可以通过下⼀个确认应答进行确认。
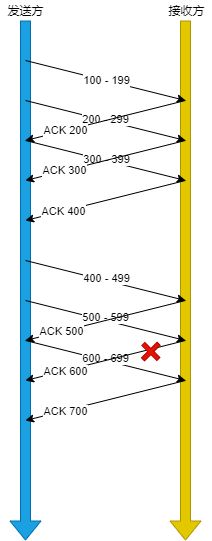
图中即使ACK 600丢失了也没关系,因为可以通过下⼀个确认应答进行确认,只要发送方收到了ACK 700 确认应答,就意味着 700 之前的所有数据接收方都收到了。这个模式就叫累计确认或者累计应答。
窗口大小决定方
TCP头里有⼀个字段叫Window ,也就是窗口大小。
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
所以,通常窗口的大小是由接收方的窗口大小来决定的。 发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。
发送方的窗口
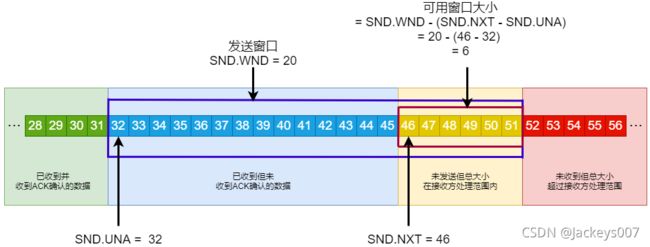
接收方的窗口

三、流量控制
流量控制主要是通过对窗口的大小的控制实现的。
操作系统缓冲区与滑动窗口的关系
假定了发送窗口和接收窗口是不变的,但是实际上,发送窗口和接收窗口中所存放的字节数,都是放在操作系统内存缓冲区中的,而操作系统的缓冲区,会被操作系统调整。
TCP规定是不允许同时减少缓存又收缩窗口的,而是采用先收缩窗口,过段时间再减少缓存,这样就可以避免了丢包情况。
窗口关闭
TCP 通过让接收方指明希望从发送方接收的数据大小(窗口大小)来进行流量控制。 如果窗口大小为 0 时,就会阻止发送方给接收方传递数据,直到窗口变为非 0 为止,这就是窗口关闭。
窗口关闭存在的问题
死锁
当发生窗口关闭时,接收方处理完数据后,会向发送方通告⼀个窗口非0的ACK报文,如果这个通告窗口的ACK报文在网络中丢失了,那麻烦就大了。这会导致发送方⼀直等待接收方的非0窗口通知,接收方也⼀直等待发送方的数据,如不采取措施,这种相互等待的过程,会造成了死锁的现象。
窗口探测
为了解决这个问题,TCP为每个连接设有⼀个持续定时器,只要TCP连接一方收到对方的零窗口通知,就启动持续计时器。 如果持续计时器超时,就会发送窗⼝探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
- 如果接收窗口仍然为0,那么收到这个报文的一方就会重新启动持续计时器
- 如果接收窗口不是0,那么死锁的局⾯就可以被打破了
窗口探测的次数⼀般为3次,每次大约 30-60 秒(不同的实现可能会不⼀样)。如果3次过后接收窗口还是0的话,有的 TCP 实现就会发 RST 报文来中断连接。这些窗口探测报文以 3.4s、6.5s、13.5s 的间隔出现,说明超时时间会翻倍递增。
糊涂窗口综合症
如果接收方太忙了,来不及取走接收窗口里的数据,那么就会导致发送方的发送窗口越来越小。 到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节, 这就是糊涂窗口综合症。
要知道,我们的TCP + IP头有40个字节,为了传输那几个字节的数据,要达上这么⼤的开销,这太不经济了。
避免小窗口通知
接收方策略
当窗口大小于min( MSS,缓存空间/2 ) ,也就是小于MSS与1/2缓存中的最小值时,就会向发送方通告窗口为0 ,也就阻止了发送方再发数据过来。等到接收方处理了⼀些数据后,窗口大小 >= MSS,或者接收方缓存空间有⼀半可以使用,就可以把窗口打开让发送方发送数据过来。
发送方策略
Nagle算法:延时处理
- 等到窗口大小 >= MSS 或者数据大小 >= MSS
- 没有已发送未确认报文时,立刻发送数据
只要没满足上面条件中的⼀条,发送方⼀直在囤积数据,直到满足上面的发送条件。
四、拥塞控制
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时TCP就会重传数据,但是⼀重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进⼊恶性循环被不断地放大…所以,TCP不能忽略网络上发生的事,它被设计成⼀个无私的协议,当网络发送拥塞时,TCP会自我牺牲,降低发送的数据量。 于是,就有了拥塞控制,控制的目的就是避免发送方的数据填满整个网络。
拥塞窗口
拥塞窗口(cwnd)是发送方维护的⼀个的状态变量,它会根据网络的拥塞程度动态变化的。 我们在前面提到过发送窗口(swnd) 和接收窗口(rwnd) 是约等于的关系,那么由于加入了拥塞窗口的概念后,此 时发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值。
拥塞窗口cwnd变化的规则:
- 只要网络中没有出现拥塞, cwnd就会增大
- 但网络中出现了拥塞, cwnd就减少
网络是否拥塞 :只要发送方没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
拥塞控制算法
慢启动
慢启动的算法记住⼀个规则就行:当发送方每收到⼀个ACK,拥塞窗口 cwnd的大下就会加1。
可以看出慢启动算法,发包的个数是指数性的增长
那慢启动涨到什么时候是个头呢?
有⼀个叫慢启动门限 ssthresh (slow start threshold)状态变量。
- 当 cwnd < ssthresh 时,使用慢启动算法。
- 当 cwnd >= ssthresh 时,就会使用拥塞避免算法
⼀般来说 ssthresh 的大小是 65535 字节。
拥塞避免算法
进入拥塞避免算法后,它的规则是:每当收到⼀个 ACK 时,cwnd 增加 1/cwnd。我们可以发现,拥塞避免算法就是将原本慢启动算法的指数增栈变成了线性增栈,还是增长阶段,但是增长速度缓慢了⼀些。 就这么⼀直增⻓着后,网络就会慢慢进⼊了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。 当触发了重传机制,也就进入了拥塞发生算法。
拥塞发生算法
发生超时重传的拥塞发生算法
- ssthresh设为cwnd/2
- cwnd重置为1
发生快速重传的拥塞发生算法
- cwnd = cwnd/2 ,也就是设置为原来的⼀半;
- ssthresh = cwnd,进⼊快速恢复算法
快速恢复
- 拥塞窗口cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了)
- 重传丢失的数据包
- 如果再收到重复的 ACK,那么 cwnd 增加 1
- 如果收到新数据的 ACK 后,把 cwnd 设置为第⼀步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态
五、TCP延迟确认
为了解决 ACK 传输效率低问题,所以就衍⽣出了 TCP 延迟确认
TCP延迟确认的策略
- 当有响应数据要发送时,ACK 会随着响应数据⼀起⽴刻发送给对方
- 当没有响应数据要发送时,ACK 将会延迟⼀段时间,以等待是否有响应数据可以⼀起发送
- 如果在延迟等待发送 ACK期间,对方的第⼆个数据报文又到达了,这时就会立刻发送ACK
- TCP延迟确认可以在 Socket 设置 TCP_QUICKACK 选项来关闭这个算法
当TCP 延迟确认和Nagle算法混合使用时,会导致时耗增长
要解决这个问题,只有两个办法
- 要不发送方关闭Nagle算法
- 要不接收方关闭TCP延迟确认