【爬虫高阶】精通requests库爬虫
精通requests库爬虫
- 1. 最基本使用范例
- 2. 搜索参数
- 3. post使用示范
- 4. json数据请求
- 5. 图片下载
- 6. session会话
- 7. 忽略HTTPS证书
- 8. ip代理
- 9. 上传
- 10. 下载
- 11. urllib库补充
1. 最基本使用范例
也是爬虫第一步的试探网页
import requests
def get_html(url):
html = requests.get(url)
if html.status_code == 200:
html.encoding = 'utf-8'
print(html.text)
else:
print('ERROR',url)
if __name__ == '__main__':
url = 'http://www.baidu.com/s'
get_html(url)
2. 搜索参数
比如打开百度搜索相关的信息(这里以python为例),可以发现搜索结果出来后对应的网址如下:
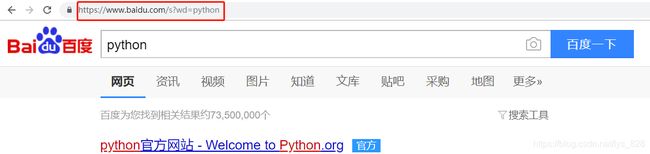
可以发现要搜索的结果会直接反应在网址上面,后面内容组成的形式为?wd=python,其中等号后面的内容就是我们要搜索的。在进行爬虫过程中,为了保持url整体的美观(不要长度过长),可以将后面的内容以字典的方式进行存储并传递给params参数(往往这个字典的名称也是叫params)
params = {
'wd':'python'}
html = requests.get(url,params=params)
3. post使用示范
post通常用于请求表单,不过传递的参数是data,不是params要和上面的参数进行区别开。可以拿python官网的测试网址进行post请求的测试,如下
import requests
def post_html(url):
data = {
'name':'python','pwd':123}
html = requests.post(url,data = data)
if html.status_code == 200:
html.encoding = 'utf-8'
print(html.text)
else:
print('ERROR',url)
if __name__ == '__main__':
url = 'http://httpbin.org/post'
post_html(url)
4. json数据请求
这种网页就是通过ajax交互的,里面的信息直接使用get请求是无法获得其中的有效信息。可以通过检查发现所有的数据都是在资源url的接口中,只需要请求这个url获取其中的数据即可
import requests
def get_html(url):
html = requests.get(url)
if html.status_code == 200:
html.encoding = 'utf-8'
#print(html.text)
content = html.json()
for c in content:
print(c['id'],c['title'])
else:
print('ERROR',url)
if __name__ == '__main__':
url = 'https://news.qq.com/ext2020/apub/json/prevent.new.json'
get_html(url)
5. 图片下载
以百度图片为例,该网页中的信息也是以ajax交互的形式(url不变,但是内容可以增加)。比如下载哪吒之魔童降世的图片,具体代码如下
import os
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Referer':'http://image.baidu.com/search/index?',
'Cookie':'BIDUPSID=82508FD9E8C7F366210EB75A638DF308; PSTM=1567074841; MCITY=-%3A; BDUSS=40RFJRR09CLU85ejZHU1FSRHNWdmhaN1ZyQTlwMlo5MUZIUnlxdEtMU09hSUZlRVFBQUFBJCQAAAAAAAAAAAEAAABQontKTWlzc2Fst-gAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI7bWV6O21leaW; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=0F2472E83269C89F55EFE0E6B0FEF5A9:FG=1; indexPageSugList=%5B%22%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96%22%2C%22%E7%99%BE%E5%BA%A6%22%2C%22%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96%E5%9B%BE%E7%89%87%22%2C%22%E5%93%AA%E5%90%92%22%2C%22%E9%9D%92%E7%94%B0%22%2C%22%E6%99%B4%E5%A4%A9%22%5D; H_PS_PSSID=30963_1442_21087_30791_30998_30823_22158; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=1; ___wk_scode_token=tcQ51Zf6S5pU%2B1DDHYelwpmVyt6gUicizYCUXOTEJis%3D; session_id=1583653459699; session_name=www.baidu.com; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=null; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm'
}
def get_img(url):
html = requests.get(url,headers =headers)
if html.status_code == 200:
html.encoding = html.apparent_encoding
content = html.json()['data']
count = 1
for c in content[:-1]:
download_img(c['middleURL'], count)
count += 1
else:
print('Error',url)
def download_img(img_url,count):
img = requests.get(img_url,headers = headers)
if not os.path.exists('picture_mv'):
os.mkdir('picture_mv')
print('正在下载第{}张图片...'.format(count))
with open('./picture_mv/{}.jpg'.format(count),'wb') as f:
for chunk in img.iter_content(225):#这里是按照块进行写入,对于下载大型的视频或者音乐比较友好
f.write(chunk)
if __name__ == '__main__':
url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=0&ic=&hd=&latest=©right=&word=%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96&s=&se=&tab=&width=&height=&face=&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1583656519626='
get_img(url)
→ 输出的结果为:(在当前目录下会自动创建文件夹并写入图片文件)
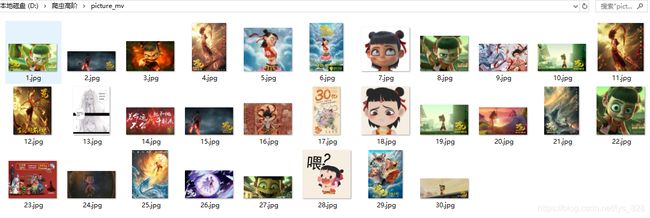
6. session会话
首先创建一个session,然后传入相关的参数即可,可以减少程序运行时间,提高爬虫效率,以上面的代码为例只需要修改三处代码即可
import os
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Referer':'http://image.baidu.com/search/index?',
'Cookie':'BIDUPSID=82508FD9E8C7F366210EB75A638DF308; PSTM=1567074841; MCITY=-%3A; BDUSS=40RFJRR09CLU85ejZHU1FSRHNWdmhaN1ZyQTlwMlo5MUZIUnlxdEtMU09hSUZlRVFBQUFBJCQAAAAAAAAAAAEAAABQontKTWlzc2Fst-gAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI7bWV6O21leaW; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=0F2472E83269C89F55EFE0E6B0FEF5A9:FG=1; indexPageSugList=%5B%22%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96%22%2C%22%E7%99%BE%E5%BA%A6%22%2C%22%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96%E5%9B%BE%E7%89%87%22%2C%22%E5%93%AA%E5%90%92%22%2C%22%E9%9D%92%E7%94%B0%22%2C%22%E6%99%B4%E5%A4%A9%22%5D; H_PS_PSSID=30963_1442_21087_30791_30998_30823_22158; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=1; ___wk_scode_token=tcQ51Zf6S5pU%2B1DDHYelwpmVyt6gUicizYCUXOTEJis%3D; session_id=1583653459699; session_name=www.baidu.com; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=null; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm'
}
session = requests.session() #第一行
session.headers = headers #第二行
def get_img(url):
html = session.get(url) #第三行
if html.status_code == 200:
html.encoding = html.apparent_encoding
content = html.json()['data']
count = 1
for c in content[:-1]:
download_img(c['middleURL'], count)
count += 1
else:
print('Error',url)
def download_img(img_url,count):
img = requests.get(img_url,headers = headers)
if not os.path.exists('picture_mv'):
os.mkdir('picture_mv')
print('正在下载第{}张图片...'.format(count))
with open('./picture_mv/{}.jpg'.format(count),'wb') as f:
for chunk in img.iter_content(225):
f.write(chunk)
if __name__ == '__main__':
url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=0&ic=&hd=&latest=©right=&word=%E5%93%AA%E5%90%92%E4%B9%8B%E9%AD%94%E7%AB%A5%E9%99%8D%E4%B8%96&s=&se=&tab=&width=&height=&face=&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1583656519626='
get_img(url)
7. 忽略HTTPS证书
在get(url)的括号中添加verify=False即可,这种情况是应对爬虫过程中显示SSL安全连接的问题
import requests
def get_html(url):
html = requests.get(url,verify=False)
print(html.text)
if __name__ == '__main__':
url = 'https://www.baidu.com'
get_html(url)
8. ip代理
对于某些网站,如果爬取信息过于频繁,就会导致被封ip,如果在使用自己的本地ip就无法继续访问网页了。(建议购买ip,免费ip你想使用,别人也在使用,使用的人多了自然就被封了,也就访问无效了,白嫖虽然很舒服,但是体验感极差)
设置代理ip的格式:(为了避免ip无效等待时间过长,可以关闭证书验证和设置请求时间限制timeout)
如果是购买的ip的话,不存在timeout的现象,这也涉及了体验感的问题
import requests
proxies = {
'http':'http://171.13.202.161:9999',
'https':'http://171.13.202.161:9999'
}
def get_html(url):
html = requests.get(url,proxies = proxies,verify=False,timeout=3)
print(html.text)
if __name__ == '__main__':
url = 'https://www.baidu.com'
get_html(url)
9. 上传
向网站上传入信息
import requests
files = {
'file':
('render',open('render.html','rb'), #第一个参数是文件名 + 文件(核心)
'application/html', #第二个参数是文件格式如果是图片的话就是image
{
'Expires':'0'}) #第三个参数是额外添加的参数,这里是代表文件不过期的意思
}
def get_html(url):
html = requests.post(url,files = files)
if html.status_code == 200:
print(html.text)
else:
print('get error:'+ html.url)
if __name__ == '__main__':
url = 'http://httpbin.org/post'
get_html(url)
10. 下载
上面的百度图片的下载中已经使用到了,这里直接将代码复制下面,为了可视化输出结果,建议传入一个count参数进行计数和文件的命名
def download_img(img_url,count):
img = requests.get(img_url,headers = headers)
if not os.path.exists('picture_mv'):
os.mkdir('picture_mv')
print('正在下载第{}张图片...'.format(count))
with open('./picture_mv/{}.jpg'.format(count),'wb') as f:
for chunk in img.iter_content(225):
if chunk:
f.write(chunk)
11. urllib库补充
① urllib.parse.urljoin 该方法有点类似os库下的路径拼接方法os.path.join()
from urllib import parse
url_1 = 'http://www.baidu.com'
url_2 = 'http://www.baidu.com/'
url_3 = 'http://www.baidu.com//'
content_url = '/img1.jpg'
print(url_1 + content_url)
print(parse.urljoin(url_1,content_url))
print('------------------')
print(parse.urljoin(url_2,content_url))
print(parse.urljoin(url_3,content_url))
→ 输出的结果为:(注意这三个url的区别)
http://www.baidu.com/img1.jpg
http://www.baidu.com/img1.jpg
------------------
http://www.baidu.com/img1.jpg
http://www.baidu.com/img1.jpg
② urllib.parse.quote和 urllib.parse.unquote 数据转码,转变成为计算机真正输入的字符和编码再转回成为正常的汉字,比如这里拿小米手机为例,进行百度的搜索
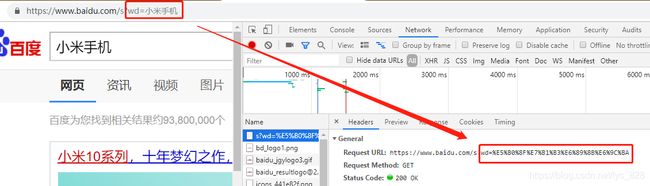
wd = '小米手机'
print(parse.quote(wd))
print(parse.unquote(parse.quote(wd)))
url = 'http://www.baidu.com/s?wd=/'
print(url+parse.quote(wd))
→ 输出的结果为:(可以发现编码之间可以正常转换,最后的url也和上面的url地址最后的内容是一致的,在结合第一个方法就可以正确的构造完整的url了)
%E5%B0%8F%E7%B1%B3%E6%89%8B%E6%9C%BA
小米手机
http://www.baidu.com/s?wd=/%E5%B0%8F%E7%B1%B3%E6%89%8B%E6%9C%BA
③ urllib.parse.urlsplit 和urllib.parse.urlparse 分割url内容,进行解析
url = 'http://www.baidu.com/s?wd=/%E5%B0%8F%E7%B1%B3%E6%89%8B%E6%9C%BA'
print(parse.urlsplit(url)) #没有的话就不需要进行切分(split函数在分割的时候,path和params属性是在一起的)
print(parse.urlparse(url)) #即使没有也切分,比如这里的params(这种方式更加细致,把path和params拆开了)
→ 输出的结果为:(结果几乎是一致的)
SplitResult(scheme='http', netloc='www.baidu.com', path='/s', query='wd=/%E5%B0%8F%E7%B1%B3%E6%89%8B%E6%9C%BA', fragment='')
ParseResult(scheme='http', netloc='www.baidu.com', path='/s', params='', query='wd=/%E5%B0%8F%E7%B1%B3%E6%89%8B%E6%9C%BA', fragment='')