深度学习与推荐系统(十五)——LS-PLM(MLR)模型
CTR预估的发展过程中,LR模型是比较常用的方法,因为其计算量小容易并行,工业上应用非常广泛,同时也引发了各位大佬基于LR模型的优化改进,这一改进通常有两个方向,一个是走融合路,即GBDT+LR样式,将LR模型与其他的模型算法结合,达到优势互补的效果;另一个就是因子分解,即FM系列探索,它们的主要思想就是构造交叉特征或者是二阶的特征来一起进行训练。
除此之外也会有一些大佬给出一些新的思路,比如本文中介绍的LS-PLM模型(又叫MLR模型),这一模型是用传统的机器学习方法模仿了深度学习的结构,采用divide-and-conquer策略,将特征空间分割成若干个子区域,在每个子区域采用线性模型,最后用weighted-linear-predictions组合结果。
首先我们需要先看一个图片:

我们在使用LR模型的时候,往往最容易处理图2样式,因为数据集线型可分,刚好是LR的特长,但是,对于图3样式就未必了,图3是非线性数据集,需要用非线性模型来处理,因此有了我们今天讲述的LS-PLM模型。
LS-PLM模型解决这一模型的方法即为将图3中的数据分成多个子区域,然后针对子区域单独建模,再用函数将模型融合成一个,如图:

那么,如何将上面的图片分切成多块呢?切分成几块比较合适的?每块的数据该用什么模型训练呢?
问题就变的很清晰了:有效切片和分组训练。
好在阿里的大佬给出了答案:

我们仔细观察这一模型,发现公式中有两个函数:
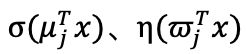
第一个即为分割函数σ(x),这一函数将原数据集分成m份,m为超参数;
第二个即为预测函数η(x),这一函数各自模拟每一小块数据集,形成上图中的Func_n函数。
将softmax函数作为分割函数σ(x),将sigmoid函数作为拟合函数η(x)的时候,该模型为:
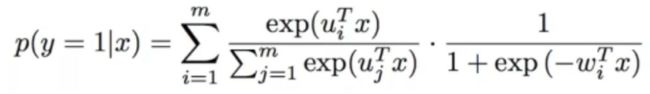
用概率的形式整理出对应的函数公式为:
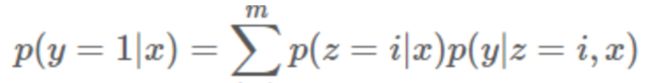
而对应的损失函数为:

理论上来说,增大m可以带来无限制的非线性拟合能力,但是同样会增加计算、存储的开销,同时会带来过拟合的风险。
具体如何选取m要结合实际情况取舍。
同时MLR还引入了结构化先验、分组稀疏、线性偏置、模型级联、增量训练、Common Feature Trick来提升模型性能。
我们看一下这些细节:
1)结构化先验:使用用户特征来划分特征空间,使用广告特征来进行基分类器的训练,减小了模型的探索空间,收敛更容易,这一模型本质上更符合我们对数据的认知。
2)线型偏置:针对CTR预估问题中存在的两种偏置:
Position Bias:排名第1位和第5位的样本,点击率天然存在差异。商品展示的页面、位置影响点击率
Sample Bias:PC和Mobile上的样本,点击率天然存在差异。
LS-PLM中提出了对应的解决方案:
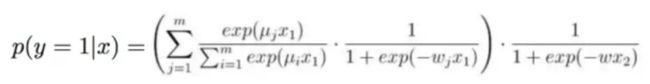
在原来商品特征x的基础上,增加偏移向量 (场景、页数、位置等),如上图。
3)模型级联:在模型训练过程中MLR只是对某一个场景的拟合,对于复杂场景时,也需要用到级联的效果,如图:

4)增量训练: MLR利用结构先验(用户特征进行聚类,广告特征进行分类)进行预训练,然后再增量进行全空间参数寻优训练,会使得收敛步数更少,收敛更稳定,类似于迭代了一次的EM算法,如下公式:

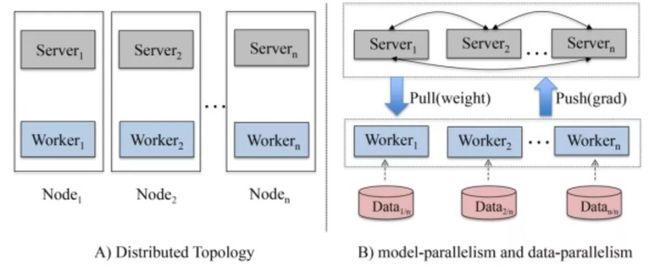
5)并行化:模型实现基于分布式,包括两个维度的并行化,模型并行化,数据并行化。每一个计算节点中都包含两种角色:Server Node, Worker Node,这样做的好处有两点:
其一:最大化利用CPU计算资源。之前大多数Server Node单独放到一台服务器上,造成CPU资源的极大浪费。
其二:最大化利用Memory资源。
6)Common Feature Trick:
一个用户在一次pageview中会看到多个广告,每个广告都组成一条样本。所以这些样本之间很多特征都是重复的。这些特征包括:用户特征(年龄、性别等)、用户的历史访问信息(之前购买的物品、喜欢的店铺等)。那么我们对于向量内积的计算分成两部分:common和non-common parts:

对应的公式为:

利用Common Feature Trick可以从三个方面来优化并行化:
其一:对于有Common Feature的样本作为一组一起训练,并保证在存储在一个worker上
其二:对于Common Feature仅仅保存一次,以便来节省内存
其三:对于Common Feature的loss和梯度更新只需要一次即可
这一模型的优势为:
1)端到端的非线性学习: 从模型端自动挖掘数据中蕴藏的非线性模式,省去了大量的人工特征设计,这使得MLR算法可以端到端地完成训练,在不同场景中的迁移和应用非常轻松,通过分区来达到拟合非线性函数的效果。
2)可伸缩性(scalability):与逻辑回归模型相似,都可以很好的处理复杂的样本与高维的特征,并且做到了分布式并行;
3)稀疏性: 对于在线学习系统,模型的稀疏性较为重要,所以采用了$L_{1}$和(L_{2,1})正则化,模型的学习和在线预测性能更好。当然,目标函数非凸非光滑为算法优带来了新的挑战。
但其自身的缺点也非常明显:
1)初值问题、非凸问题的局部极值等方面虽然MLR比LR好,但不知道和全局最优相比还有多远;
2)在初值的Pre-train方面需要改进和优化模型函数;
3)目前规模化能力方面也需要能够吞吐更多特征和数据,比如采用更快的收敛算法等等;
4)整体的MLR算法的抽象能力也需进一步得到强化。