如何使用预训练模型优雅的生成sentence embedding
前言
预训练语言模型在目前的大部分nlp任务中做个微调都能取得不错的一个结果,但是很多场景下,我们可能没办法微调,例如文本聚类,我们更需要的是文本的向量表示;又亦如文本匹配,特别是实时搜索场景,当候选集数量较多时,直接使用ptm做匹配速度较慢。那么如何优雅的使用预训练模型生成文本embedding呢?本文将会从不同的预训练模型与不同的优化方法去介绍文本embedding的生成方式,如有理解错误,欢迎大家指正。
本文所有的测试结果基于哈工大开源的LCQMC数据集,共20+w条数据,测试方法是计算两个句子的Spearman Rank Correlation与Pearsonr Rank Correlation,从测量的相关关系上区分,Pearson主要是用来测试线性关系,而Spearman主要是用来测试单调关系,因此建议大家以Spearman的结果为主要参考
word2vec与elmo
baseline还是需要的,word2vec使用了Tencent AI Lab提供的word2vec取了前50w个词(一共16G加载太慢,感觉也没必要全部加载),维度是200维,句向量采用结巴分词后取均值。elmo使用的是哈工大的ELMoForManyLangs,句向量采用的是embedding层的输出值,两层BiLSTM的输出值取均值作为句向量,对比结果如下。
| model | pool | pearson | spearman |
|---|---|---|---|
| word2vec | avg | 0.5221449680785076 | 0.608919562764869 |
| elmo | all layers avg | 0.509483629327993 | 0.5385281534683071 |
bert类模型的基操
bert类模型输出句向量的方式主要有两种方式,取cls表示句向量或者对所有的token值做一个pool操作。pool又有很多种,有取均值,最大值,用哪一层的结果又有很多讲究,有取最后一层的,取后两层的,甚至取第一层与最后一层。这里采用了均值的方式,对比了bert与roberta。
| model | pool | pearson | spearman |
|---|---|---|---|
| bert | pool cls | 0.27871322472395693 | 0.3310821317298972 |
| bert | last layer avg | 0.5772801258273837 | 0.6064618026402799 |
| bert | last two layers avg | 0.5800012472780051 | 0.6059884888103338 |
| bert | first and last layer avg | 0.6127307061481112 | 0.649701785152543 |
| roberta | pool cls | 0.6014500036464623 | 0.6750408040822591 |
| roberta | last layer avg | 0.6248498038899556 | 0.6769580860060049 |
| roberta | last two layers avg | 0.6278031589954911 | 0.6770390647187172 |
| roberta | first and last layer avg | 0.6398432770277978 | 0.691869016734878 |
可以看到bert的cls可以说是完全用不了的,甚至被word2vec无情碾压。但是反观roberta的cls表现还不错。个人认为应该是因为roberta取消了nsp任务没有segment embedding,cls更能代表句向量。反观bert因为有nsp的任务,两个句子可能对cls的结果有一定的影响。当然也不排除是因为roberta本身效果就优于bert。效果最理想的方案是取第一层与最后一层的输出值做平均池化操作,个人想法,最后一层的值会有些“过拟合”,而第一层的值又较为“欠拟合”,中和一下选个折中的方案。
虽然roberta的效果有所提升,但是依旧有进步空间,我们还是需要考虑下为啥bert类模型生成的句向量效果不够理想,我这里有两种解释,先看第一种

上述表格第一行表示词频,数值越大表示词频越小。第二行表示的是bert生成的每个词的embedding到原点的 l 2 l_2 l2距离,可以发现,词频高的词距离原点距离更近。第三到五行表示的是词embedding的k个邻居词的 l 2 l_2 l2距离,可知词频越高的词,周围的词越多,词频越高周围的词也约稀疏。
从表格中得出的结论,可以发现在bert的embedding空间内,只要词频低的词,其附近会有很多“空洞”,即无意义的空间,而我们在计算sentence embedding时通常都是取均值,取了均值后就有一定的概率落在“空洞”的位置,或者说是语义不平滑的,这就对最终的的相似度计算造成了一定的影响。其次,高低频词的分布特性,导致在计算相似度时会出现相似度过高或者过低的情况,当句子都是由高频词组成,相似度就会很高,相反当句子中低频次很多,相似度就会很低。
再看第二种解释,一般用于计算文本相似度的方法是cosine similarity,其优点在于值域在[0,1]区间内,便于选择阈值,bert的输出是一个高维空间的向量,假设这个向量已经能充分的表示文本的语义,但cosine similarity计算较为简单,可能没办法把这么复杂的值用这么简单的方法计算出其相似度。其次,cosine similarity的计算公式是两个向量的內积除以各自的模长。
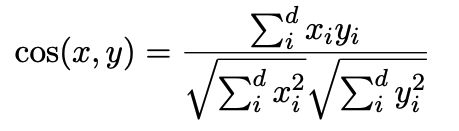
但是上式要成立需要保证我们的向量的基底是标准正交基,基底如果不同,那么內积的计算公式就不一样,cosine similarity的计算自然也就不一样了,bert生成的embedding的坐标系是否是标准正交基我们不得而知了,但是既然效果不理想我们完全可以猜测大概率不是。
知道了为啥效果不好,那么我们就来针对其缺点进行改进,下文会为大家介绍监督学习与非监督学习的两种改进方法。
基于监督学习的bert类模型embedding
既然直接使用bert生成的句向量效果不够理想,那么能不能先做一个微调再来使用bert生成句向量呢?通常我们微调都是最小化cross entropy,我们的目标并不是cosine similarity,既然如此,我们何不直接把目标修改为cosine similarity,让cls的值就是为计算cosine similarity来服务的,这就是sentence bert(下文简称sbert)的思路。
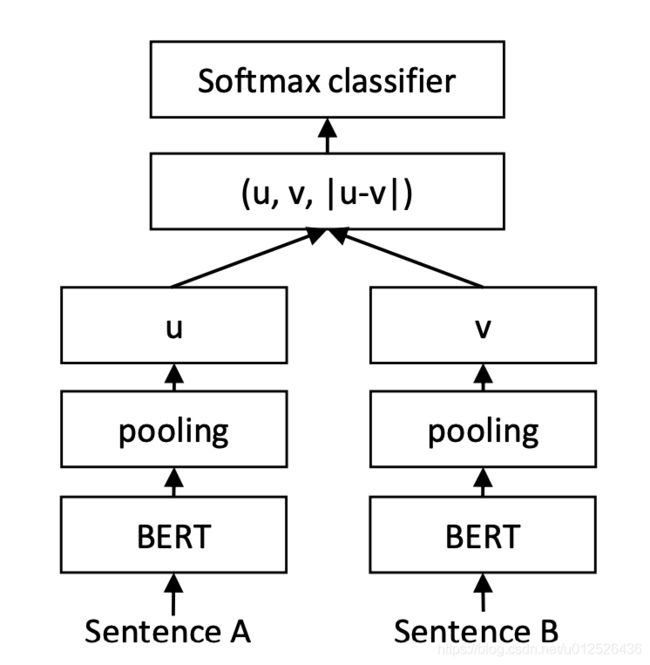
如上图所示,我们需要使用NLI或者STS的数据集对模型进行微调,把单个bert改成孪生网络的结构,这里虽然是两个部分,但是权重是共享的,首先使用NLI的数据训练模型,分别输入两个句子,得到对应的cls的值,及上图的u与v,然后把u,v与|u-v|进行拼接,再进行分类。
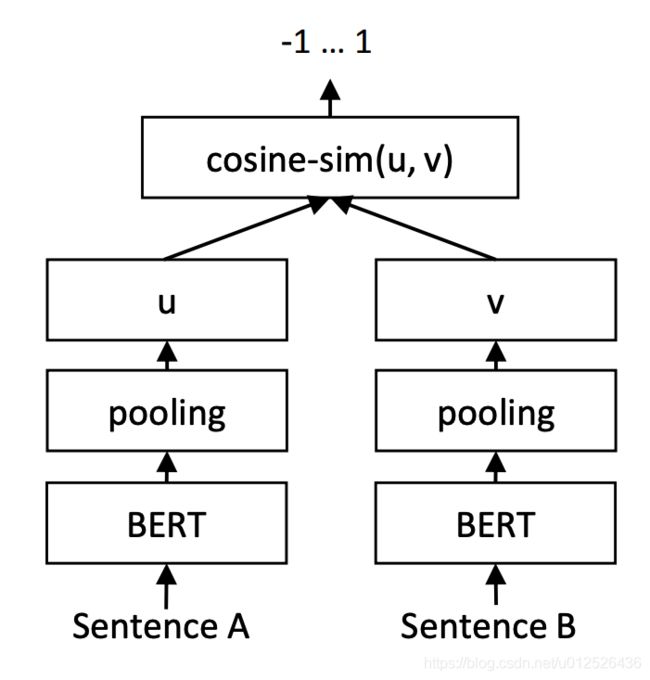
然后使用STS的数据再进行训练,结构还是一样的,只不过输出的u与v这个时候需要计算cosine similarity,最后损失函数换成了平方损失函数。
sbert中还提到了一种替换成hinge loss的方法
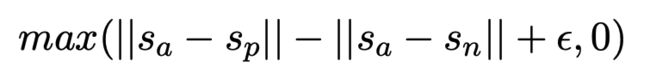
a是原句,p是正例,n是负例,目标是要让原句与正例的差别要比原句与负例的差别大 ϵ \epsilon ϵ
最后我们看下sbert的效果,使用的论文作者提供的一个多语言版本的sbert
| model | pool | pearson | spearman |
|---|---|---|---|
| sbert-multilingual-v1 | pool cls | 0.6947266935364882 | 0.7500983592620584 |
除了sentence bert我们再看一种方法,来自苏剑林的simbert,其思路是让模型不再简单的判断两个句子是否相似,而是提高了任务难度,让模型选择哪个句子和当前的句子相似度最大,其结构如下

模型使用的是微软提出的unilm,即半编码半回归模型,输入是两个句子,与nsp任务类似,然后把两个句子的顺序颠倒再输入一次,这样的输入我们称为一组数据,每个batch需要n组这样的数据,n取决于你的显存大小。然后把整个batch内的cls向量都拿出来,得到一个句向量矩阵 V ∈ R b × d V \in R^{b×d} V∈Rb×d( b b b是batch_size, d d d是hidden_size),然后对 d d d维度做 l 2 l_2 l2归一化,得到 V ~ \tilde V V~,然后两两做内积,得到 b × b b×b b×b的相似度矩阵 V ~ V ~ T \tilde V \tilde V^T V~V~T,接着乘以一个scale simbert中取了30,并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。simbert因为使用的是unilm的结构,除了可以计算相似度,还可以用于生成同义句。当然也可以把unilm替换成bert,如果使用bert就只输入一个句子即可。
最后来看结果吧
| model | pool | pearson | spearman |
|---|---|---|---|
| simbert | pool cls | 0.7057674570559229 | 0.7611765158950129 |
sbert效果略逊于simbert,simbert算是目前我尝试过的模型中的SOTA,但也不排除如果有充足的中文语料,sbert也可能超越simbert。
基于非监督学习的bert类模型embedding
这部分我们来介绍下非监督学习的方法来改善embedding的方法
上文提到想要计算余弦相似度,首先需要向量所属的坐标系是标准正交基。既然正交则所属向量必不相关,那么其协方差就为0,对应的向量则应该表现出各向同性(各向同性是指协方差矩阵为单位阵乘以一个正的常数),所以,我们应该想办法把让bert的embedding的值变得或者说趋近于各向同性。
这里依旧是介绍两种方法,第一种方法是bert-flow,bert-flow的思路是把数据转变到标准的高斯分布,标准高斯分布是各向同性的,并且高斯分布是凸的,或者说是没有"空洞"的,因此语义分布也会更加的光滑。
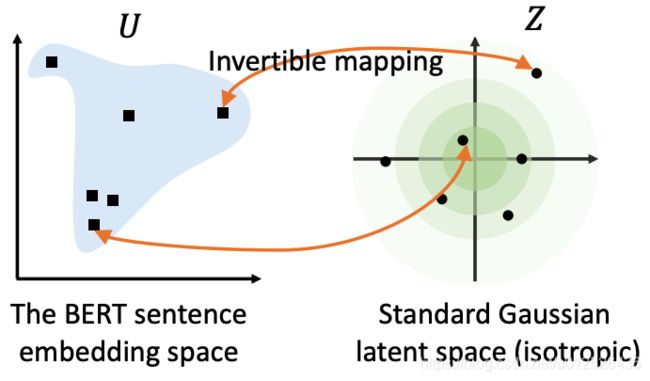
bert-flow采用了基于流的生成模型来做这个数据分布的转变,flow是一个google提出来的用于做图像生成的模型,其思路是将服从高斯分布的随机变量 z z z经过 f f f函数映射到bert的编码 u u u, 其中 f f f需要是可逆的,这样 u u u即可通过 f − 1 f^{-1} f−1映射到高斯分布上。
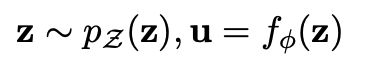
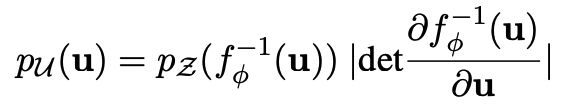
训练的过程只更新flow模型的参数,优化目标为最大化从高斯分布到bert分布的概率即

bert-flow中的流模型实际使用的是flow的改进版本glow模型,具体细节这里就不展开说明了,感兴趣的童鞋可以参考源码,这里也提供一篇讲解flow的博客
除了bert-flow转变成正态分布的方法,我们再看另一种方法bert-whitening,标准正态分布的均值为0,协方差矩阵为单位阵,那我们能不能想办法把bert的embedding的均值转为0,协方差矩阵变为单位阵,实际上,这就是机器学习中常用的白化操作(whitening是指不同特征间相关性最小,接近0即协方差是0,并且所有特征的方差相等)。
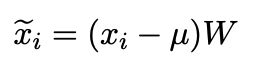
上式就是whitening操作,那我们的目标就很明确了,求解 μ \mu μ与 W W W
μ \mu μ很简单,计算均值即可
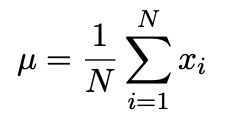
关键点在于求解 W W W,协方差矩阵的计算如下
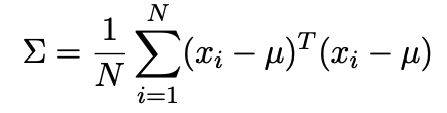
根据上面的公式,我们可以得到 x ~ \tilde x x~的协方差矩阵为
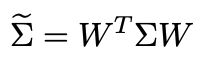
whitening需要协方差矩阵是单位阵,所以有
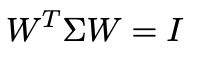
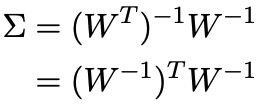
协方差矩阵 Σ \Sigma Σ是一个正定对称阵,因此做SVD分解得到
![]()
这里的 U U U是正交阵, Λ \Lambda Λ是对角阵且对角线是正数,因此可以得到
![]()
![]()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I3ws0XME-1618487449589)(/Users/joezhao/Library/Application Support/typora-user-images/image-20210401172944204.png)]
有了 μ \mu μ与 W W W即可对embedding做whitening了。初次之外,做SVD分解时, Λ \Lambda Λ是对应的奇异值,这个是按照从大到小排序的,因此,我们可以只取前k维的数据,毕竟奇异值小的特征,保留着意义也不大,这里其实就是做了个pca的处理。
最后我们来看下flow与whitening的效果,两篇论文在英文数据集上测试提升都较为明显,但在本文的中文测试集上提升并不大。
| model | pool | pearson | spearman |
|---|---|---|---|
| bert | first and last layer avg | 0.6127307061481112 | 0.649701785152543 |
| bert-whitening | first and last layer avg | 0.6523656336679565 | 0.6532168453336087 |
| bert-whitening-256 | first and last layer avg | 0.6424918520578062 | 0.659421830463197 |
| bert-flow | first and last layer avg | 0.6117111735647337 | 0.6541951509643525 |
总结
本文介绍了bert类模型的各种文本embedding的生成方式,每种方法各有优缺。如果你有足够多打了标签的同义句,那么采用有监督的方式肯定是最优的选择,没有数据,不妨尝试下两种无监督的方法,毕竟聊胜于无嘛~,除了bert自身的embedding,也可以考虑去融合其它模型生成的embedding,或者静态的词向量。
如果你有其它更有意思的embedding方式,欢迎留言,我会根据你提供的方法进行评测。
References
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Whitening Sentence Representations for Better Semantics and Faster Retrieval
On the Sentence Embeddings from Pre-trained Language Models
Combining BERT with Static Word Embeddings for Categorizing Social Media
LCQMC: A Large-scale Chinese Question Matching Corpus
鱼与熊掌兼得:融合检索和生成的SimBERT模型
生成模型——流模型(Flow)