Pytorch基础操作学习笔记分享——基础篇
目录
- 前言
- 一、Pytorch基本数据类型
-
- 1、Python与pytorch数据类型对比
- 2、怎样去表达字符(string)
- 3、在Pytorch中Tensor数据类型的表示
- 4、查看数据类型
- 5、检查Tensor在GPU上还是在CPU上
- 6、按Tensor的维度对Tensor进行分类
- 二、创建Tensor
-
- 1、第一种方式从numpy中导入Tensor(生成的Tensor已被初始化)
- 2、第二种方式在List中导入Tensor(生成的Tensor已被初始化)
- 3、第三种方式包括以下方法(生成的Tensor未被初始化)
- 4、第四种方式生成0-1均匀分布的Tensor
- 5、第五种方式生成正态分布的Tensor
- 6、第六种方式生成一个全部为相同元素的Tensor
- 7、第七种方式生成递增/减得等差数列的Tensor
- 8、第八种方式生成等分的Tensor
- 9、第九种方式生成全部为0、1、单位矩阵的Tensor
- 10、设置默认的Tensor类型
- 11、随机打散
- 三、索引与切片
-
- 1、索引
- 2、取连续的一个片断
- 3、取连续有一定间隔的片断
- 4、取指定维度指定行/列的Tensor
- 5、取所有的维度
- 6、使用掩码来索引
- 7、先把Tensor打平后再做索引
- 四、维度变换
-
- 1、常见的维度变换API
- 2、改变维度
- 3、增加维度
- 4、删减维度
- 5、维度扩展(将维度的shape(形状)改变)
- 6、矩阵转置
- 7、维度交换
- 总结
前言
最近一直在改自己的代码,发现自己有很多pytorch的基础操作还不是很熟,所以就整理了pytorch基础操作的笔记,我的研究方向是基于深度学习的海马与全脑配准,自己还是个医学图像配准的小白,希望能跟大家一起交流学习,所以我自己新建立了一个医学图像配准交流群,群号:142608634,有什么问题大家可以在群里交流,希望大家能一起学习一起进步。这一篇博客是基础篇,后面我会再给大家分享进阶篇。我写博客的原因有以下几点:
1、给自己整理笔记,形成一个好的知识体系,便于以后翻笔记的时候直接看博客就可以了,这样就比较清晰。
2、记录自己的学习过程。
3、因为我在CSDN博客上也学习了好多的知识,就想把自己的笔记也分享给大家来回馈之前在CSDN博客上的学习。
一、Pytorch基本数据类型
1、Python与pytorch数据类型对比

说明:
(1):左边的是python的数据类型,右边的是pytorch的数据类型
(2):pytorch的数据类型都是以Tensor结尾的
(3):pytorch是面向数据计算的GOU加速库,不是语言库,所以没有string类型。将在第二节介绍怎样表示String类型。
2、怎样去表达字符(string)
(数值—>字符),用数字的形式去表达文字
(1):One-hot(独热编码) 例如:[0, 1, 0, 0, …]
缺点:A:数据量大导致维度过大。B:单词与单词之间的语义相关性没有了
(2):Embedding(词嵌入) 例如:A:Word2 B:glove(这两个是已经预训练好的词嵌入库)
这种词嵌入形式就是为了解决独热编码提出来的,在深度学习中使用Embeddding Layer来解决,词嵌入就是用一个数字组成的向量去表达一个单词。
3、在Pytorch中Tensor数据类型的表示

说明:
(1)图片中被标注出来的是平常使用比较多的
(2)其中被标注的第三个Torch.ByteTensor表示两个Tensor元素是否相等,相等返回1,不相等返回0。
4、查看数据类型

说明:查看Tensor的数据类型只有两种形式
(1)Tensor.type pytorch的方法来返回Tensor数据类型
(2)Type(Tensor) python的方法来返回Tensor数据类型
5、检查Tensor在GPU上还是在CPU上

说明:
(1)使用Tensor.cuda()的方法将Tensor搬运到GPU上
(2)使用isinstance(Tensor, cuda的数据类型)就可以查看Tensor是否在GPU上
6、按Tensor的维度对Tensor进行分类
(1)Dim=0的Tensor(标量scalar,没有轴的概念)

说明:
A:标量一般用来表示loss,因为loss打印出来就是一个标量
B:这里要注意加[]和不加[]的区别
怎样得到dim=0的shape(形状)

(2)Dim=1的Tensor(向量vector,只有一个轴)

说明:
A:Vector向量一般用来表示偏置值
B:适合单张图片的线性层的输入(相当于batch等于1的输入),线性层的输入就是一个dim=1的Tensor
怎样得到dim=1的shape(形状):

说明:
A:dim=2可以理解为有2个轴,x轴与y轴,dim才是平时所说的维度。
B:size/shape[2,2]:表示形状,几行几列。大部分人这里会混淆,就会觉得dim是维度,shape也是维度,这是错误的,dim才是维度,shape只是形状,为了好区分,以后统一叫dim维度、shape形状。
C:Tensor[1, 2]:这里表示一个具体的数值,不是维度也不是形状。
(3)Dim=2的Tensor(可以理解为矩阵,有两个轴,X轴和Y轴)
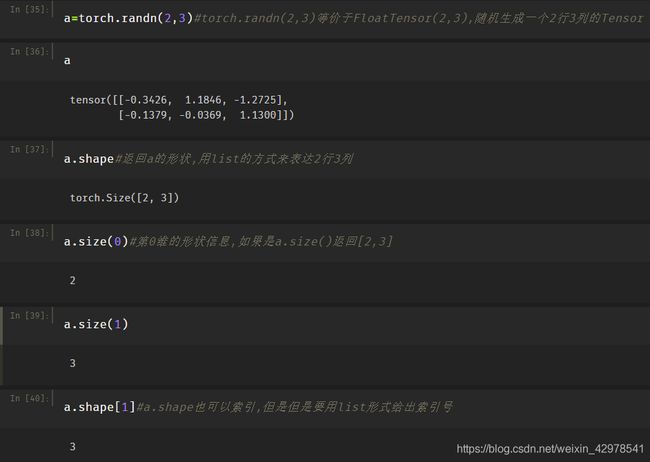
说明:
适合多张图片线性层的输入(也就是batch大于1的输入)
(4)Dim=3的Tensor(有三个轴,为了好理解,可以理解为X轴、Y轴、Z轴)

说明:
适合处理NLP循环神经网络RNN,例如[10,20,100]代表20个句子、每个句子10个单词、每个单词用一个100维的向量来表示。
(5)Dim=4的Tensor(可以理解为有四个轴)


说明:
A:适合卷积神经网络,例如[b,c,h,w] b代表batch,C代表通道,h代表高,w代表宽。

二、创建Tensor
1、第一种方式从numpy中导入Tensor(生成的Tensor已被初始化)

说明:
A:从numpy中导入的Float其实是Double类型
B:torch.from_numpy(numpy矩阵)方法可以从numpy中导入Tensor
2、第二种方式在List中导入Tensor(生成的Tensor已被初始化)
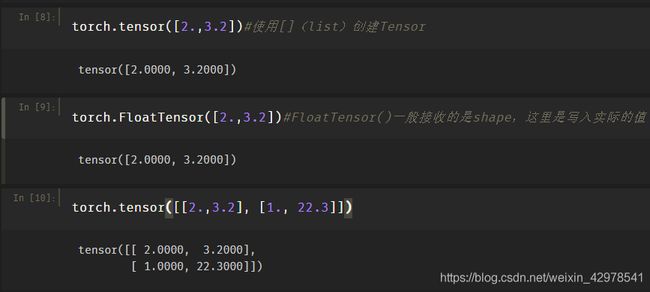
说明:
A:这里一定要注意torch.tensor()只能接收具体的数值,可以用list和numpy的形式给出,不能接收shape(形状)
B:torch.FloatTensor()和torch.IntTensor()接收的是shape(形状),也可以接收具体数值(要少用这种方法容易混淆),还要注意的是F和T要大写。
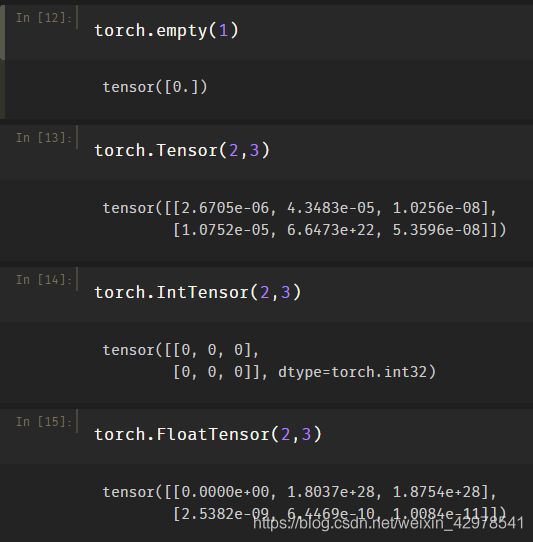
3、第三种方式包括以下方法(生成的Tensor未被初始化)
一般有以下三种方法(这三种方法生成的Tensor数据未被初始化):
(1)torch.empty() 接收的shape(形状)
(2)torch.FloatTensor()接收的shape(形状)
(3)torch.IntTensor()接收的shape(形状)
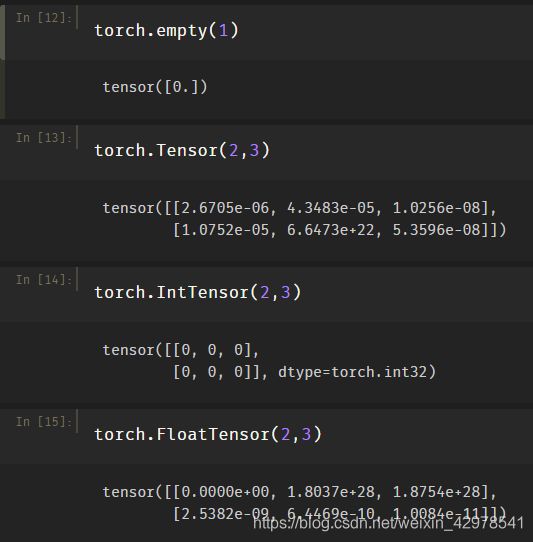
注:未被初始化API生成的Tensor尽量把未被初始化数据覆盖掉。
4、第四种方式生成0-1均匀分布的Tensor
一般有以下三种方法(这三种方法生成的Tensor数据已经被初始化):
(1)torch.rand() 生成0-1均匀分布的Tensor,接收的shape(形状)
(2)torch.rand_like()接收的不是shape(形状),是一个Tensor
(3)torch.randint(起始位置,结束位置,Tensor形状shape)从1-10均匀采样整数
5、第五种方式生成正态分布的Tensor
一般有以下三种方法(这三种方法生成的Tensor数据已经被初始化):
(1)torch.randn() 生成随机正态分布的Tensor,接收的shape(形状)
(2)torch.normal()自定义均值和方差去生成一个随机正态分布的Tensor
(3)N(0,1)均值为0,方差为1

6、第六种方式生成一个全部为相同元素的Tensor
(1)torch.full(Tensor的shape形状,要产生元素数值)生成全为相同元素的Tensor

7、第七种方式生成递增/减得等差数列的Tensor
(1)torch.arange(起始位置,结束位置,步长)生成生成递增的序列
(2)torch.range()与torch.arange()区别就是arange包含结束位置的数值,而range不包含结束位置的数值

8、第八种方式生成等分的Tensor
(1)torch.linspace(起始位置,结束位置,steps=分为几份)表示从起始位置到结束位置(包含结束位置)等分为steps份。
(2)Torch.logspace(起始位置,结束位置,steps=分为几份)表示从起始位置到结束位置(包含结束位置)等分为steps份,然后做10的几次方

9、第九种方式生成全部为0、1、单位矩阵的Tensor
(1)torch.ones()生成全为1的Tensor,接收的是shape
(2)torch.zeros()生成全为0的Tensor,接收的是shape
(3)torch.eye()生成或转换成一个单位矩阵的Tensor,接收的是shape
(4)也可以使用torch.ones_like()方法生成全为1的Tensor,但是接收的Tensor


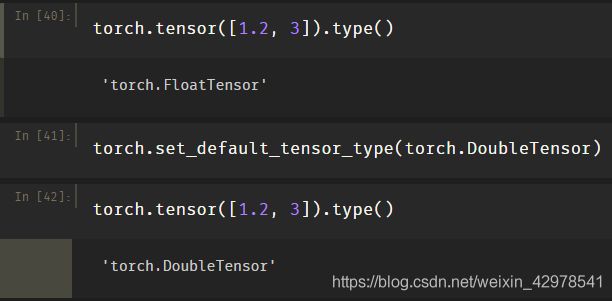
10、设置默认的Tensor类型
Pytorch默认的Tensor数据类型是FloatTensor,可以使用torch.set_default_tensor_type()将pytorch默认的数据类型更改为想要的数据类型。
11、随机打散
torch.randperm(10)随机打散0-9(不包含10)的数生成一个Tensor。


三、索引与切片
1、索引
(1)直接使用Tensor[索引值]方式索引就可以(注:这种索引方式都是从最左边开始索引)

2、取连续的一个片断
(1)直接使用Tensor[开始位置:结束位置,…,开始位置:结束位置]方式索引就可以,每一个维度上都是这种形式(注:这种索引方式都是从最左边开始索引,如果没补全则会从最左边开始索引)

3、取连续有一定间隔的片断
(1)直接使用Tensor[开始位置:结束位置:步长,…,开始位置:结束位置:步长]方式索引就可以间隔索引,每一个维度上都是这种形式(注:这种索引方式都是从最左边开始索引,如果没补全则会从最左边开始索引)

4、取指定维度指定行/列的Tensor
(1)Tensor.index_select(指定索引的维度, torch.tensor([开始位置:结束位置])),使用这种方式就可以对指定维度的指定行和列进行索引,但是要注意,指定行和列时给定的是一个Tensor而不是以列表的形式给出。
(2)Tensor.index_select(指定索引的维度, torch.arange(索引数量)),也可以是这种序列形式给出。

5、取所有的维度
使用…取所有的维度,…是任意长,要根据 实际情况判断出来
注:…仅仅是为了方便

6、使用掩码来索引
先使用Tensor.ge(掩码值范围)设定好掩码值,.ge(掩码值范围)表示大于等于这个范围的值置为True,再使用torch.masked_select(Tensor,掩码值)进行索引,这里值得注意的是被索引出来的值被打平成一个一维(dim=1)的向量。

7、先把Tensor打平后再做索引
使用torch.take(Tensor,torch.tensor([索引号]))进行索引,这里值得注意的是不管原来的Tensor是几维的都要先打平成一个一维的Tensor,之后再按索引号进行索引。

四、维度变换
1、常见的维度变换API
(1)View/reshape:将一个Tensor从一个维度转变成另一个维度
(2)Squeeze/unsqueeze:删减和增加维度
(3)Transpose/t/permute:维度交换
(4)Expand/repeat:维度扩展
2、改变维度
(1)使用Tensor.view(要改变的维度)或Tensor.reshape(要改变的维度)这两个API就可以对Tensor为维度进行改变。
(2)view等价于reshape,reshape是为了和numpy一致后来新出来的,所以view和reshape使用哪个都可以。
(3)这里需要注意的是变换后维度的数值数量需要和变换之前维度的数值数量保持一致,还要注意数据一旦reshape就恢复不到原来的数据,因为数据被打乱。


3、增加维度
(1)使用Tensor.unsqueeze(选择在哪个维度进行增加)对Tensor的维度增加
(2)这里值得注意的是新插入的维度它的shape(形状)为1
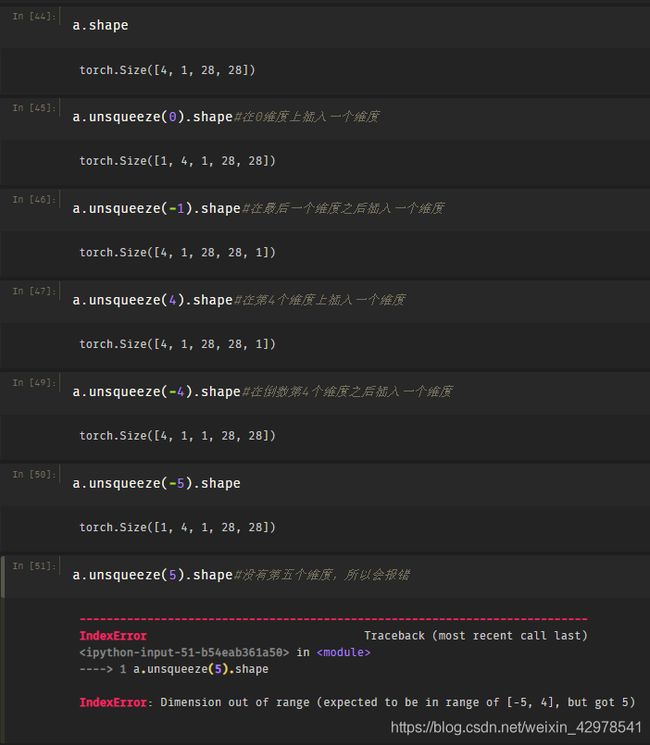

案列:

4、删减维度
(1)使用Tensor.squeeze(idx)可以删减维度,idx这个参数表示要删除的维度,要删除的这个维度它的shape(形状)必须是1,只有shape为1的才能被删除。
(2)这里值得注意的是idx这个参数可以删除指定的维度,如果idx这个参数不给出的话就会删除所有shape(形状)为1的维度

5、维度扩展(将维度的shape(形状)改变)
(1)Tensor.expand(要扩展的shape),这个API可以扩展Tensor维度的shape(形状)为1到指定的shape(形状),这里值得注意的就是Tensor.expand()只能扩展shape为1的维度。
(2)Tensor.repeat(要拷贝的shape的次数),这个API也可以扩展Tensor的shape,repeat顾名思义就是在此维度上要重复的次数,也可以理解为乘法运算。
(3)这里我来说一下expand和repeat这两个API的区别,expand的参数给出的是最终我想要的shape,而repeat的参数给出的是我要在原始维度上复制几次。
(4)expand扩展维度只是改变了理解方式,并没有增加数据,而repeat是实实在在的增加数据,他会复制数据到增加的shape上,也就是说repeat会把你的内存更改掉,他会重新申请一片内存空间来存放新复制出来的数据。这两个API都会达到最终的效果,所以我建议大家最好使用expand,不要使用repeat,因为扩展的维度过大的话会占用大量内存。
Expand:

Repeat:

6、矩阵转置
(1)使用Tensor.t()就可以实现矩阵的转置
(2)这里要注意的是Tensor.t()只适合用于二维的Tensor

7、维度交换
(1)Tensor.transpose(需要交换的两个维度的索引号),这个API可以实现两个维度的交换,并且只能实现单次交换,也就是说一次是能交换两个维度
(2)Tensor.permute(所有维度的索引号顺序),这个API可以实现多个维度的交换,并且可以实现多次交换,但是需要参数里面需要写全所有维度,可以理解为给维度排一下顺序。

总结
最后再总结一下,上面的代码部分后面的注释很重要,我在写代码过程中做了注释,我这次分享的笔记总结都是pytorch的一些基础操作,因为目前我也在改自己的代码,所以这些pytorch基础还挺有用的,我在改代码的过程中上面的大部分操作都用到了,所以还是挺重要的,希望我整理的笔记能对大家有用。最后,希望大家科研顺利,前途无量。