网络参数重组论文四(Diverse Branch Block)
本系列文章介绍一种最近比较火的设计网络的思想,即利用网络的重参数化(意义在于训练时间模型有一组参数,而推理时间模型有另一组参数),把多层合成一层,进行网络加速。
Diverse Branch Block: Building a Convolution as an Inception-like Unit中了介绍一些可以用于参数重组的变换,可以根据这些变换组合成为一个可替代卷积层的模块,在训练过程中使用这些复杂的模块,在测试过程中将模块参数重组为简单的卷积。
1. 6种参数变换
在文中,作者总结了6种变换来对DBB进行BN添加、分支求和、串联1x1卷积、多尺度卷积求和(ACNet)、平均池化和分支拼接:
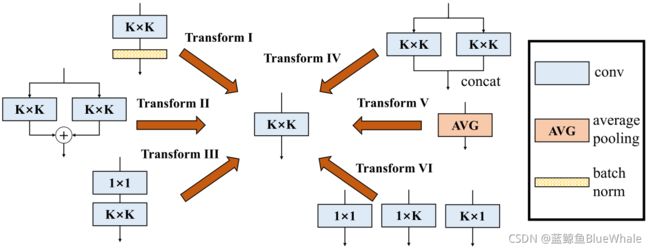
1.1. BN添加转换

def transI_fusebn(kernel, bn):
gamma = bn.weight
std = (bn.running_var + bn.eps).sqrt()
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
1.2. 分支添加转换

def transII_addbranch(kernels, biases):
return sum(kernels), sum(biases)
1.3. 串联1x1卷积

def transIII_1x1_kxk(k1, b1, k2, b2, groups):
if groups == 1:
k = F.conv2d(k2, k1.permute(1, 0, 2, 3)) #
b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))
else:
k_slices = []
b_slices = []
k1_T = k1.permute(1, 0, 2, 3)
k1_group_width = k1.size(0) // groups
k2_group_width = k2.size(0) // groups
for g in range(groups):
k1_T_slice = k1_T[:, g*k1_group_width:(g+1)*k1_group_width, :, :]
k2_slice = k2[g*k2_group_width:(g+1)*k2_group_width, :, :, :]
k_slices.append(F.conv2d(k2_slice, k1_T_slice))
b_slices.append((k2_slice * b1[g*k1_group_width:(g+1)*k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))
k, b_hat = transIV_depthconcat(k_slices, b_slices)
return k, b_hat + b2
1.4. 深度拼接
F ′ = C O N C A T ( F ( 1 ) , F ( 2 ) ) , b ′ = C O N C A T ( b ( 1 ) , b ( 2 ) ) F'=CONCAT(F^{(1)}, F^{(2)}), b'=CONCAT(b^{(1)}, b^{(2)}) F′=CONCAT(F(1),F(2)),b′=CONCAT(b(1),b(2))
def transIV_depthconcat(kernels, biases):
return torch.cat(kernels, dim=0), torch.cat(biases)
1.5. 平均池化

def transV_avg(channels, kernel_size, groups):
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
1.6. 多尺度卷积求和
对 1 × K , K × 1 1\times K, K\times 1 1×K,K×1卷积进行零填充变为 K × K K\times K K×K卷积,然后转变为转换2
def transVI_multiscale(kernel, target_kernel_size):
H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2
W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2
return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])
2. Diverse Branch Block结构
作者提出的DDB变换利用上述6种变换构造的结构如下,也可以通过这些变换构造更复杂的模型
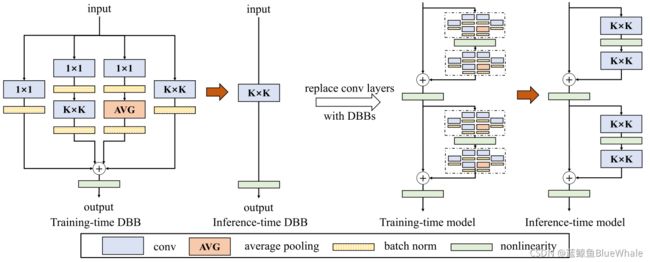
可以利用上述变换转换获得DBB结构的等价Kernal和Bias:
def get_equivalent_kernel_bias(self):
# k_origin
k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
# k_1x1
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
# k_1x1_kxk_merged
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second, b_1x1_kxk_second, groups=self.groups)
# k_1x1_avg_merged
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device), self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second, b_1x1_avg_second, groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
return transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged), (b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))