[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120915279
目录
第1章 卷积神经网络基础
1.1 卷积神经发展与进化史
1.2 卷积神经网络的核心要素
1.3 卷积神经网络的描述方法
1.4 人工智能三巨头 + 华人圈名人
第2章 ResNet网络概述
2.1 传统网络遇到的困境
2.2 ResNet网络概述
2.3 ResNet网络的层数
2.4 何明凯其人
2.5 什么是“残差”?
2.6 “残差”内在的思想
第3章 “残差”块的基本组成
第4章 ResNet的网络结构
4.1 NesNET-34网络结构-1(全部描述)
4.2 NesNET-34网络结构-2(简化描述)
4.3 不同层的残差网络
4.4 不同层的残差网络的性能比较
第1章 卷积神经网络基础
1.1 卷积神经发展与进化史
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第1张图片](http://img.e-com-net.com/image/info8/3f713fae8ed6457c8b9744c0038d78d5.jpg)
AlexNet是深度学习的起点,后续各种深度学习的网络或算法,都是源于AlexNet网络。
[人工智能-深度学习-31]:卷积神经网络CNN - 常见卷积神经网络综合比较大全_文火冰糖(王文兵)的博客-CSDN博客作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文网址:第1章 人工智能发展的3次浪潮1.1人工智能的发展报告2011-2020资料来源:清华大学、中国人工智能学会《人工智能的发展报告2011-2020》,赛迪研究院、人工智能产业创新联盟《人工智能实践录》,中金公司研究部► 第一次浪潮(1956-1974年):AI思潮赋予机器逻辑推理能力。伴随着“人工智能”这一新兴概念的兴起,人们对AI的未来充满了想象,人工智能迎来第一次发展浪潮。这.https://blog.csdn.net/HiWangWenBing/article/details/120835303
1.2 卷积神经网络的核心要素
[人工智能-深度学习-27]:卷积神经网络CNN - 核心概念(卷积、滑动、填充、参数共享、通道)_文火冰糖(王文兵)的博客-CSDN博客作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文网址:目录第1章 卷积中的“积”的定义第2章 卷积中的“卷”的定义第3章 填充第4章 单个卷积核的输出第5章 多个卷积核的输出第6章 卷积对图形变换第7章 池化层第8章 全连接的dropout第1章 卷积中的“积”的定义第2章 卷积中的“卷”的定义stride:反映的每次移动的像素点的个数。第3章 填充...https://blog.csdn.net/HiWangWenBing/article/details/120806277
1.3 卷积神经网络的描述方法
[人工智能-深度学习-28]:卷积神经网络CNN - 网络架构与描述方法_文火冰糖(王文兵)的博客-CSDN博客作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文网址:目录第1章 什么是卷积神经网络第2章 卷积神经网络的描述方法第3章 卷积神经网络的本质第4章 卷积神经网络的总体框框第5章卷积神经网络的发展与常见类型与分类第6章 常见的卷积神经网络6.1 AlexNet6.2 VGGNet6.3 GoogleNet: inception结构6.4 google net6.5 ResNet第7章 常见图形训练库第1.https://blog.csdn.net/HiWangWenBing/article/details/120806599
1.4 人工智能三巨头 + 华人圈名人
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第2张图片](http://img.e-com-net.com/image/info8/0f504626b011437d8baacf72ac931c6d.jpg)
Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年的图灵奖。
杰弗里·埃弗里斯特·辛顿(Geoffrey Everest Hinton),计算机学家、心理学家,被称为“神经网络之父”、“深度学习鼻祖”。Hinton是机器学习领域的加拿大首席学者,是加拿大高等研究院赞助的“神经计算和自适应感知”项目的领导者,是盖茨比计算神经科学中心的创始人,目前担任多伦多大学计算机科学系教授。2013年3月,谷歌收购 Hinton 的公司 DNNResearch 后,他便随即加入谷歌,直至目前一直在 Google Brain 中担任要职。
Yoshua Bengio是蒙特利尔大学(Université de Montréal)的终身教授,任教超过22年,是蒙特利尔大学机器学习研究所(MILA)的负责人,是CIFAR项目的负责人之一,负责神经计算和自适应感知器等方面,又是加拿大统计学习算法学会的主席,是ApSTAT技术的发起人与研发大牛。Bengio在蒙特利尔大学任教之前,是AT&T贝尔实验室 & MIT的机器学习博士后。
Yann LeCun,担任Facebook首席人工智能科学家和纽约大学教授,1987年至1988年,Yann LeCun是多伦多大学Geoffrey Hinton实验室的博士后研究员。
第2章 ResNet网络概述
2.1 传统网络遇到的困境
[人工智能-深度学习-36]:卷积神经网络CNN - 简单地网络层数堆叠导致的问题分析(梯度消失、梯度弥散、梯度爆炸)与解决之道_文火冰糖(王文兵)的博客-CSDN博客作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文网址:目录第1章 简单堆叠神经元导致参数量剧增的问题1.1 网络层数增加大带来的好处1.2 一个奇怪的现象1.3网络层数增加带来的负面效果第2章 参数量剧增导致的训练问题2.1 计算量的增加2.2 模型容易过拟合,泛化能力变差。2.3 梯度异常2.4 loss异常第3章 梯度消失:参数的变化率接近与3.1 什么是梯度消失和梯度弥散3.2梯度的由来:反向传播..https://blog.csdn.net/HiWangWenBing/article/details/120919308
2.2 ResNet网络概述
深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的又一件里程碑事件。
它由微软研究院的Kaiming He(何明凯)等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,在ILSVRC2015比赛中取得冠军, 取得了5项第一,并又一次刷新了CNN模型在ImageNet上的历史。
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第3张图片](http://img.e-com-net.com/image/info8/867a4ef37039448e889b64c53440080f.jpg)
其在top5上的错误率仅为3.57%,在ImageNet比赛中,是首个准确率超过人眼的网络。
那么ResNet为什么会有如此优异的表现呢?
其实ResNet是解决了深度(20层以上)CNN模型难训练的问题。
2.3 ResNet网络的层数
而15年的ResNet多达152层,无论是VGG, 还是GgooLnet,这在网络深度上,与ResNet完全不是一个量级上。这里就有一个关键问题:ResNet是如何做到在增加网络深度的时候,同时能够克服深度网络的问题呢?
根本原因是,ResNet对网络架构上的革新,这才使得网络的深度优势发挥出作用,这个革新就是残差学习(Residual learning)。
它使得,随着网络层数的增加,其性能也同时增加,如下图所示:
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第4张图片](http://img.e-com-net.com/image/info8/6a05bff2e4054a5d9abed66658873fc5.jpg)
2.4 何明凯其人
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第5张图片](http://img.e-com-net.com/image/info8/b533301d063d471ab51f59bf19fa9847.jpg)
何恺明,本科就读于清华大学,博士毕业于香港中文大学多媒体实验室。
2011年加入微软亚洲研究院(MSRA)工作,主要研究计算机视觉和深度学习。2016年,加入Facebook AI Research(FAIR)担任研究科学家。2020年1月11日,荣登AI全球最具影响力学者榜单。
2.5 什么是“残差”?
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。
“残差”蕴含了有关模型基本假设的重要信息。
如果回归模型正确的话, 我们可以将残差看作误差的观测值。
在ResNet网络中,“残差”表示的是ResNet网络的基本组成“块”,这个“块”表示具有差的性质,即使Y = X + F(X) => Y - X = F(X), 其中F(X)就是“残差”。
Y = X + F(X) 这样的结构就是“残差”块,由““残差”块叠加而成的网络就是“残差”。
2.6 “残差”内在的思想
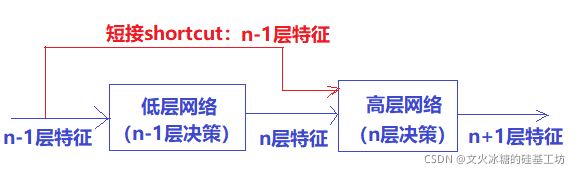
浅层网络具备更多的特征信息,如果我们把浅层(低层管理层)的特征传到高层(管理层),让高层根据这些信息进行决策(分类和特征提取),那么高层最后的效果应该至少不比浅层的网络效果差,最坏的情况是与低层更好的效果,更普遍的情况是,高层由于有更多、更抽象的特征信息,因此高层的决策效果会比低层更准确。
更抽象的讲,我们需要一种技术,确保保证了L+1层的网络一定比 L层包含更多的图像信息。
这就是ResNet shortcut网络结构的底层逻辑和内在思想!!!。
“残差”块是残差网络的核心,有必要深入了解其基本组成与原理。
第3章 “残差”块的基本组成
详解残差网络 - 知乎
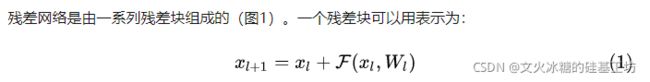
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第6张图片](http://img.e-com-net.com/image/info8/0d0e3fdc902d4067ad6b106f02c8034d.jpg)
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第7张图片](http://img.e-com-net.com/image/info8/f6d6cd4740d844a3bf460b3725dc59d3.jpg)
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第8张图片](http://img.e-com-net.com/image/info8/99c8f68e234649959cdee9353e6b1727.jpg)
shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。
第4章 ResNet的网络结构
4.1 NesNET-34网络结构-1(全部描述)
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第9张图片](http://img.e-com-net.com/image/info8/50041ddcd215430f88d779802e8d6f0b.png)
4.2 NesNET-34网络结构-2(简化描述)
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第10张图片](http://img.e-com-net.com/image/info8/5ce111762b4f4d3a95cb7d7c787d816e.jpg)
(1)输入
- 任意尺寸
(2)64通道卷积
- 7* 7 * 64的卷积核
(3)64通道的“残差块
- 3个残差块
- 每个残差块组成:2个3*3*64的卷积核
(4)128通道的“残差块
- 3+1=4个残差块
- 每个残差块组成:2个3*3*128的卷积核
(5)256通道的“残差块
- 5+1 = 6个残差块
- 每个残差块组成:2个3*3*256的卷积核
(6)512通道的“残差块
- 2+1 = 3个残差块
- 每个残差块组成:2个3*3*512的卷积核
(7)池化
- 平均池化
(8)1000分类的全连接
- 单层全连接
- 1000个全连接神经元
- 1000个输出
(9)总层数:34层
4.3 不同层的残差网络
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第11张图片](http://img.e-com-net.com/image/info8/8b96a1e9debb4b88b187b4611e9b9377.jpg)
- 随着网络层数的增加,精确度也在提升,网络的参数的数量和计算量也都在提升。
- 通过简单的堆叠“残差”块,提升网络的深度。
4.4 不同层的残差网络的性能比较
(1)比较图-1
![[人工智能-深度学习-38]:卷积神经网络CNN - 常见分类网络- ResNet网络架构分析与详解_第12张图片](http://img.e-com-net.com/image/info8/b199879a36624159b19dd7e9f3a05349.jpg)
备注:
Plain-18/34:表示非残差网络,34层的网络错误率反而低于18层的网络。
ResNet-18/34:表示残差网络,34层的网络错误率要高于18层的网络。
(2)比较图-2
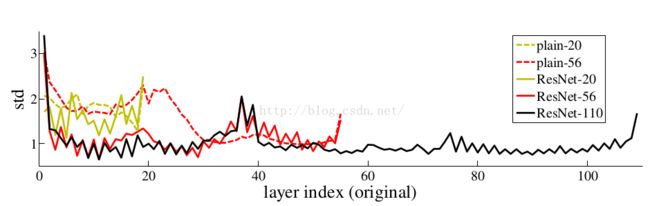
ResNet-110 > ResNet-56 > ResNet-20 > Plain-20 > Plain-56
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120915279