命名实体识别整体逻辑框架(BERT+BiLSTM+CRF)
数据集标注:
标注方式
- BIO
- BMESO
每个句子以空行区分。
数据预处理
- 读取所有句子和标签存为两个个list,并判断是否对齐
def load_file(file_path):#读取数据集
contents = open(file_path, encoding='utf-8').readlines()
text =[]
label = []
texts = []
labels = []
for line in contents:
if line != '\n':
line = line.strip().split(' ')
text.append(line[0])
label.append(line[-1])
else:
texts.append(text)
labels.append(label)
text = []
label = []
return texts, labels
assert len(texts) == len(labels)#判断是否对齐
- 截取最大长度,添加额外的标签
if len(token) > max_length-2:
token = token[0:(max_length-2)]
label = label[0:(max_length-2)]
tokens_f =['[CLS]'] + token + ['[SEP]']
label_f = ["" ] + label + ['' ]
- 每个句子字符转id、标签转id,mask
备注: mask的作用:填充后的字符id全部相同,通过mask中的1和0区分哪些是填充的。
input_ids = [int(vocab[i]) if i in vocab else int(vocab['[UNK]']) for i in tokens_f]
label_ids = [label_dic[i] for i in label_f]
input_mask = [1] * len(input_ids)
- 小于最大句子长度需要填充padding
while len(input_ids) < max_length:#填充
input_ids.append(0)
input_mask.append(0)
label_ids.append(label_dic['' ])
- 多种方式存储转换为id的数据集
- 每一个句子都存储在一个类中
- ???
- 封装到pytorch中的Dataloader类中
- 读取每一个句子将id转换为Tensor格式,
train_ids = torch.LongTensor([temp.input_id for temp in train_data])
train_masks = torch.LongTensor([temp.input_mask for temp in train_data])
train_tags = torch.LongTensor([temp.label_id for temp in train_data])
- TensorDataset作用:可以用来对tensor进行,打包封装到DataLoader类中

train_dataset = TensorDataset(train_ids, train_masks, train_tags)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)#
7. 封装后的数据读取方式:
for i, train_batch in enumerate(tqdm(train_loader)):
sentence, masks, tags = train_batch
sentence, masks, tags = Variable(sentence), Variable(masks), Variable(tags)

模型
- 加载模型
#加载模型(初始化一个模型)
model = BERT_LSTM_CRF(bert_model_dir, tagset_size, 768, 200, 1,
dropout_ratio=0.4, dropout1=0.4, use_cuda = use_cuda)
- 是否使用gpu:
if use_cuda:
model = model.cuda()
model.load_state_dict(torch.load(model_path))
3.训练设置
model.train()#训练阶段可以更新,eval()不可更新
optimizer = getattr(optim, 'Adam')
optimizer = optimizer(model.parameters(), lr=0.00001, weight_decay=0.00005)
4.迭代epoch训练
for epoch in range(epochs):
print('epoch: {},train'.format(epoch))
for i, train_batch in enumerate(tqdm(train_loader)):
model.zero_grad()
sentence, masks, tags = train_batch
sentence, masks, tags = Variable(sentence), Variable(masks), Variable(tags)
if use_cuda:
sentence = sentence.cuda()
masks = masks.cuda()
tags = tags.cuda()
loss = model.neg_log_likelihood_loss(sentence, masks, tags)#计算损失
loss.backward()
optimizer.step()
5.计算损失
def neg_log_likelihood_loss(self, sentence, mask, tags):
lstm_feats = self.get_output_score(sentence)#得到LSTM输出向量
loss_value = self.crf.neg_log_likelihood_loss(lstm_feats, mask, tags)
batch_size = lstm_feats.size(0)
loss_value /= float(batch_size)
return loss_value
- 通过输出向量将其转换为对应的标签,采用viterbi解码
def _viterbi_decode(self, feats, mask=None):
"""
Args:
feats: size=(batch_size, seq_len, self.target_size+2)
mask: size=(batch_size, seq_len)
Returns:
decode_idx: (batch_size, seq_len), viterbi decode结果
path_score: size=(batch_size, 1), 每个句子的得分
"""
batch_size = feats.size(0)
seq_len = feats.size(1)
tag_size = feats.size(-1)
length_mask = torch.sum(mask, dim=1).view(batch_size, 1).long()
mask = mask.transpose(1, 0).contiguous()
ins_num = seq_len * batch_size
feats = feats.transpose(1, 0).contiguous().view(
ins_num, 1, tag_size).expand(ins_num, tag_size, tag_size)
scores = feats + self.transitions.view(
1, tag_size, tag_size).expand(ins_num, tag_size, tag_size)
scores = scores.view(seq_len, batch_size, tag_size, tag_size)
seq_iter = enumerate(scores)
# record the position of the best score
back_points = list()
partition_history = list()
mask = (1 - mask.long()).byte()
try:
_, inivalues = seq_iter.__next__()
except:
_, inivalues = seq_iter.next()
partition = inivalues[:, self.START_TAG_IDX, :].clone().view(batch_size, tag_size, 1)
partition_history.append(partition)
for idx, cur_values in seq_iter:
cur_values = cur_values + partition.contiguous().view(
batch_size, tag_size, 1).expand(batch_size, tag_size, tag_size)
partition, cur_bp = torch.max(cur_values, 1)
partition_history.append(partition.unsqueeze(-1))
cur_bp.masked_fill_(mask[idx].view(batch_size, 1).expand(batch_size, tag_size), 0)
back_points.append(cur_bp)
partition_history = torch.cat(partition_history).view(
seq_len, batch_size, -1).transpose(1, 0).contiguous()
last_position = length_mask.view(batch_size, 1, 1).expand(batch_size, 1, tag_size) - 1
last_partition = torch.gather(
partition_history, 1, last_position).view(batch_size, tag_size, 1)
last_values = last_partition.expand(batch_size, tag_size, tag_size) + \
self.transitions.view(1, tag_size, tag_size).expand(batch_size, tag_size, tag_size)
_, last_bp = torch.max(last_values, 1)
pad_zero = Variable(torch.zeros(batch_size, tag_size)).long()
if self.use_cuda:
pad_zero = pad_zero.cuda()
back_points.append(pad_zero)
back_points = torch.cat(back_points).view(seq_len, batch_size, tag_size)
pointer = last_bp[:, self.END_TAG_IDX]
insert_last = pointer.contiguous().view(batch_size, 1, 1).expand(batch_size, 1, tag_size)
back_points = back_points.transpose(1, 0).contiguous()
back_points.scatter_(1, last_position, insert_last)
back_points = back_points.transpose(1, 0).contiguous()
decode_idx = Variable(torch.LongTensor(seq_len, batch_size))
if self.use_cuda:
decode_idx = decode_idx.cuda()
decode_idx[-1] = pointer.data
for idx in range(len(back_points)-2, -1, -1):
pointer = torch.gather(back_points[idx], 1, pointer.contiguous().view(batch_size, 1))
decode_idx[idx] = pointer.view(-1).data
path_score = None
decode_idx = decode_idx.transpose(1, 0)
return path_score, decode_idx
7.计算评价指标
######测试函数
def evaluate(medel, dev_loader):
medel.eval()#不更新参数
pred = []
gold = []
print('evaluate')
for i, dev_batch in enumerate(dev_loader):#验证集
sentence, masks, tags = dev_batch
sentence, masks, tags = Variable(sentence), Variable(masks), Variable(tags)
if use_cuda:
sentence = sentence.cuda()
masks = masks.cuda()
tags = tags.cuda()
predict_tags = medel(sentence, masks)
pred.extend([t for t in predict_tags.tolist()])
gold.extend([t for t in tags.tolist()])
pred_label,gold_label = recover_label(pred, gold, l2i_dic,i2l_dic)
acc, p, r, f = get_ner_fmeasure(gold_label,pred_label)
print('p: {},r: {}, f: {}'.format(p, r, f))
model.train()
return acc, p, r, f
模型输入输出计算
def forward(self, sentence, masks):
batch_size = sentence.size(0)
seq_length = sentence.size(1)
embeds, _ = self.word_embeds(sentence, attention_mask=attention_mask, output_all_encoded_layers=False)#BERT生成词向量
out = self.idcnn(embeds, seq_length)
# out = self.linear(out)
hidden = self.rand_init_hidden(batch_size)
# if embeds.is_cuda:
# hidden = (i.cuda() for i in hidden)
lstm_out, hidden = self.lstm(out, hidden)#输出和cell,双向维度*2
lstm_out = lstm_out.contiguous().view(-1, self.hidden_dim * 2)#因为线性变换输入两个维度,不然用自己的想法想,前两个维度是batch——size和length他们可以合并,关系的是最后一个维度做线性变换即(b,l,400)->(b*l,400)
d_lstm_out = self.dropout1(lstm_out)
l_out = self.liner(d_lstm_out)
lstm_feats = l_out.contiguous().view(batch_size, seq_length, -1)#恢复(b*l,class_num)->(b,l,class_num)
return lstm_feats
- BERT初始化词向量batch_sizelength768
模型结构
初始化网络结构
from pytorch_pretrained_bert import BertModel
def __init__(self, bert_config, tagset_size, embedding_dim, hidden_dim, rnn_layers, dropout_ratio, dropout1, use_cuda):
super(BERT_LSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.word_embeds = BertModel.from_pretrained(bert_config)#加载BERT预训练模型
self.idcnn = IDCNN(input_size=embedding_dim, filters=64)
self.linear = nn.Linear(64, 256)
self.lstm = nn.LSTM(64, hidden_dim,
num_layers=rnn_layers, bidirectional=True, dropout=dropout_ratio, batch_first=True)
self.rnn_layers = rnn_layers
self.dropout1 = nn.Dropout(p=dropout1)
self.crf = CRF(target_size=tagset_size, average_batch=True, use_cuda=use_cuda)
self.liner = nn.Linear(hidden_dim*2, tagset_size+2)
self.tagset_size = tagset_size
self.use_cuda = use_cuda
CRF网络结构函数解析[参考]
- 初始化函数
def __init__(self, **kwargs):
"""
Args:
target_size: int, target size
use_cuda: bool, 是否使用gpu, default is True
average_batch: bool, loss是否作平均, default is True
"""
super(CRF, self).__init__()
for k in kwargs:
self.__setattr__(k, kwargs[k])
self.START_TAG_IDX, self.END_TAG_IDX = -2, -1
init_transitions = torch.zeros(self.target_size+2, self.target_size+2)
init_transitions[:, self.START_TAG_IDX] = -1000.
init_transitions[self.END_TAG_IDX, :] = -1000.
if self.use_cuda:
init_transitions = init_transitions.cuda()
self.transitions = nn.Parameter(init_transitions)#转移分数
neg_log_likelihood_loss = forward_score - gold_score
2. 计算所有路径的分数(forward_score )参考参考网站
- 输入和之前的一样: scores, mask, tags ,
其中scores是上一步的输出,feats + transition matrix - 定义 new_tags
为了在 展平之后的 score :scores.view(seq_len, batch_size, -1) 中找到真实路径对应的索引位置
def _forward_alg(self, feats, mask=None):### 求CRF中的分母"Z", 用于loss
"""
Do the forward algorithm to compute the partition function (batched).
Args:
feats: size=(batch_size, seq_len, self.target_size+2)
mask: size=(batch_size, seq_len)
Returns:
xxx
"""
batch_size = feats.size(0)
seq_len = feats.size(1)
tag_size = feats.size(-1)
# 1. mask 转置 后 shape 为: (seq_len, batch),
# feats 原先 shape=(batch_size, seq_len, tag_size)
# 先转置: (seq_len, batch_size, tag_size)
# view: (seq_len*batch_size, 1, tag_size)
# 然后在 -2 维度复制: (seq_len*batch_size, [tag_size], tag_size)
mask = mask.transpose(1, 0).contiguous()
ins_num = batch_size * seq_len
feats = feats.transpose(1, 0).contiguous().view(
ins_num, 1, tag_size).expand(ins_num, tag_size, tag_size)#tagsize,tagsize目的是和转移矩阵维度一样
# 2. scores: LSTM所有时间步的输出 feats 先加上 转移分数
scores = feats + self.transitions.view(
1, tag_size, tag_size).expand(ins_num, tag_size, tag_size)
scores = scores.view(seq_len, batch_size, tag_size, tag_size)
seq_iter = enumerate(scores)
# seq_iter: t=0 开始的LSTM所有时间步迭代输出
# inivalues: t=1 开始的LSTM所有时间步迭代输出
try:
_, inivalues = seq_iter.__next__()
except:
_, inivalues = seq_iter.next()
# 2. 计算 a 在 t=0 时刻的初始值
partition = inivalues[:, self.START_TAG_IDX, :].clone().view(batch_size, tag_size, 1)
# 3. 迭代计算 a (即partition ) 在 t=1,2,。。。更新的值
for idx, cur_values in seq_iter: # fro idx = 1,2,3..., cur_values是LSTM输出+转移分数的值,循环的是每一个字符对应的标签分数计算,len=句子长度
cur_values = cur_values + partition.contiguous().view(
batch_size, tag_size, 1).expand(batch_size, tag_size, tag_size)
cur_partition = log_sum_exp(cur_values, tag_size)
mask_idx = mask[idx, :].view(batch_size, 1).expand(batch_size, tag_size)
masked_cur_partition = cur_partition.masked_select(mask_idx.byte())
if masked_cur_partition.dim() != 0:
# 将mask_idx中值为1元素对应的masked_cur_partition中位置的元素复制到本partition中。
# mask应该有和partition相同数目的元素。
# 即 mask 部分的 partition值不再更新
mask_idx = mask_idx.contiguous().view(batch_size, tag_size, 1)
partition.masked_scatter_(mask_idx.byte(), masked_cur_partition)
cur_values = self.transitions.view(1, tag_size, tag_size).expand(
batch_size, tag_size, tag_size) + partition.contiguous().view(
batch_size, tag_size, 1).expand(batch_size, tag_size, tag_size)
cur_partition = log_sum_exp(cur_values, tag_size)
final_partition = cur_partition[:, self.END_TAG_IDX]
return final_partition.sum(), scores
def log_sum_exp(vec, m_size):## 模型中经常用到的一种路径运算的实现
"""
结果和右式相同:torch.log(torch.sum(torch.exp(vec),1))
直接计算可能会出现 exp(999)=INF 上溢问题
所以 考虑 torch.max(vec, 1)这部分, 以避免 上溢问题
Args:
vec: size=(batch_ size, vanishing_dim, hidden_dim)
m_size: hidden_dim
Returns:
size=(batch_size, hidden_dim)
"""
_, idx = torch.max(vec, 1) # B * 1 * M ,为了防止 log(过大值max),所有值减去每列最大值
max_score = torch.gather(vec, 1, idx.view(-1, 1, m_size)).view(-1, 1, m_size) # B * M
return max_score.view(-1, m_size) + torch.log(torch.sum(
torch.exp(vec - max_score.expand_as(vec)), 1)).view(-1, m_size)
##############################################################
- 为了计算真实径的分数(gold_score)

lstm输出
def _score_sentence(self, scores, mask, tags):### 求路径pair: frames->tags 的分值
"""
Args:
scores: size=(seq_len, batch_size, tag_size, tag_size)
注:这个score是 _forward_alg中返回的第二项值
(即LSTM输出的feats 和transition matrix相加之后的结果)
mask: size=(batch_size, seq_len)
tags: size=(batch_size, seq_len)
Returns:
score:
"""
batch_size = scores.size(1)
seq_len = scores.size(0)
tag_size = scores.size(-1)
new_tags = Variable(torch.LongTensor(batch_size, seq_len))
if self.use_cuda:
new_tags = new_tags.cuda()
for idx in range(seq_len):
if idx == 0:
new_tags[:, 0] = (tag_size - 2) * tag_size + tags[:, 0]
else:
new_tags[:, idx] = tags[:, idx-1] * tag_size + tags[:, idx]
end_transition = self.transitions[:, self.END_TAG_IDX].contiguous().view(
1, tag_size).expand(batch_size, tag_size)
length_mask = torch.sum(mask, dim=1).view(batch_size, 1).long()
end_ids = torch.gather(tags, 1, length_mask-1)
end_energy = torch.gather(end_transition, 1, end_ids)
new_tags = new_tags.transpose(1, 0).contiguous().view(seq_len, batch_size, 1)
tg_energy = torch.gather(scores.view(seq_len, batch_size, -1), 2, new_tags).view(
seq_len, batch_size)
tg_energy = tg_energy.masked_select(mask.transpose(1, 0))
gold_score = tg_energy.sum() + end_energy.sum()
return gold_score
- 解码部分
_, last_bp = torch.max(last_values, 1)#取预测标签的id
- 采用viterbi解码,输出预测标签
def evaluate(medel, dev_loader):
medel.eval()
pred = []
gold = []
print('evaluate')
for i, dev_batch in enumerate(dev_loader):
sentence, masks, tags = dev_batch
sentence, masks, tags = Variable(sentence), Variable(masks), Variable(tags)
if use_cuda:
sentence = sentence.cuda()
masks = masks.cuda()
tags = tags.cuda()
predict_tags = medel(sentence, masks)#解码的是viterbi算法。
pred.extend([t for t in predict_tags.tolist()])
gold.extend([t for t in tags.tolist()])
pred_label,gold_label = recover_label(pred, gold, l2i_dic,i2l_dic)
- 将预测id转换为标签
pred_label,gold_label = recover_label(pred, gold, l2i_dic,i2l_dic)#得到标签序列
def recover_label(pred_var, gold_var, l2i_dic, i2l_dic):
assert len(pred_var) == len(gold_var)
pred_variable = []
gold_variable = []
for i in range(len(gold_var)):
start_index = gold_var[i].index(l2i_dic['' ])#寻找一个list中该值所在的下标位置
end_index = gold_var[i].index(l2i_dic['' ])
pred_variable.append(pred_var[i][start_index:end_index])#只取eos,去掉填充部分
gold_variable.append(gold_var[i][start_index:end_index])
pred_label = []
gold_label = []
for j in range(len(gold_variable)):#转换为预测标签和真实标签
pred_label.append([ i2l_dic[t] for t in pred_variable[j] ])
gold_label.append([ i2l_dic[t] for t in gold_variable[j] ])
return pred_label, gold_label
- 计算p/r/f1值
acc, p, r, f = get_ner_fmeasure(gold_label,pred_label)
def get_ner_fmeasure(golden_lists, predict_lists, label_type="BMES"):
sent_num = len(golden_lists)
golden_full = []
predict_full = []
right_full = []
right_tag = 0
all_tag = 0
for idx in range(0,sent_num):
# word_list = sentence_lists[idx]
golden_list = golden_lists[idx]
predict_list = predict_lists[idx]
for idy in range(len(golden_list)):
if golden_list[idy] == predict_list[idy]:
right_tag += 1#预测正确标签数
all_tag += len(golden_list)#所有真正标签数
if label_type == "BMES":
gold_matrix = get_ner_BMES(golden_list)#句子中的存在实体[(start,end)类型]
pred_matrix = get_ner_BMES(predict_list)
else:
gold_matrix = get_ner_BIO(golden_list)
pred_matrix = get_ner_BIO(predict_list)
right_ner = list(set(gold_matrix).intersection(set(pred_matrix)))#真实标签和预测标签位置是否正确
golden_full += gold_matrix
predict_full += pred_matrix
right_full += right_ner
right_num = len(right_full)
golden_num = len(golden_full)
predict_num = len(predict_full)
if predict_num == 0:
precision = -1
else:
precision = (right_num+0.0)/predict_num#准确率:正确预测实体数/所有预测实体数
if golden_num == 0:
recall = -1
else:
recall = (right_num+0.0)/golden_num#召回率:正确预测实体数/真实标签正确实体数量
if (precision == -1) or (recall == -1) or (precision+recall) <= 0.:
f_measure = -1
else:
f_measure = 2*precision*recall/(precision+recall)
accuracy = (right_tag+0.0)/all_tag#准确率:正确标签/所有标签
# print "Accuracy: ", right_tag,"/",all_tag,"=",accuracy
print ("gold_num = ", golden_num, " pred_num = ", predict_num, " right_num = ", right_num)
return accuracy, precision, recall, f_measure
def _viterbi_decode(self, feats, mask=None):## 求最优路径分值 和 最优路径
"""
Args:
feats: size=(batch_size, seq_len, self.target_size+2)
mask: size=(batch_size, seq_len)
Returns:
decode_idx: (batch_size, seq_len), viterbi decode结果
path_score: size=(batch_size, 1), 每个句子的得分
"""
batch_size = feats.size(0)
seq_len = feats.size(1)
tag_size = feats.size(-1)
length_mask = torch.sum(mask, dim=1).view(batch_size, 1).long()
mask = mask.transpose(1, 0).contiguous()
ins_num = seq_len * batch_size
feats = feats.transpose(1, 0).contiguous().view(
ins_num, 1, tag_size).expand(ins_num, tag_size, tag_size)
scores = feats + self.transitions.view(
1, tag_size, tag_size).expand(ins_num, tag_size, tag_size)
scores = scores.view(seq_len, batch_size, tag_size, tag_size)
seq_iter = enumerate(scores)
# record the position of the best score
back_points = list()
partition_history = list()
mask = (1 - mask.long()).byte()
try:
_, inivalues = seq_iter.__next__()
except:
_, inivalues = seq_iter.next()
partition = inivalues[:, self.START_TAG_IDX, :].clone().view(batch_size, tag_size, 1)
partition_history.append(partition)
for idx, cur_values in seq_iter:
cur_values = cur_values + partition.contiguous().view(
batch_size, tag_size, 1).expand(batch_size, tag_size, tag_size)
partition, cur_bp = torch.max(cur_values, 1)
partition_history.append(partition.unsqueeze(-1))
cur_bp.masked_fill_(mask[idx].view(batch_size, 1).expand(batch_size, tag_size), 0)
back_points.append(cur_bp)
partition_history = torch.cat(partition_history).view(
seq_len, batch_size, -1).transpose(1, 0).contiguous()
last_position = length_mask.view(batch_size, 1, 1).expand(batch_size, 1, tag_size) - 1
last_partition = torch.gather(
partition_history, 1, last_position).view(batch_size, tag_size, 1)
last_values = last_partition.expand(batch_size, tag_size, tag_size) + \
self.transitions.view(1, tag_size, tag_size).expand(batch_size, tag_size, tag_size)
_, last_bp = torch.max(last_values, 1)#取预测标签的id
pad_zero = Variable(torch.zeros(batch_size, tag_size)).long()
if self.use_cuda:
pad_zero = pad_zero.cuda()
back_points.append(pad_zero)
back_points = torch.cat(back_points).view(seq_len, batch_size, tag_size)
pointer = last_bp[:, self.END_TAG_IDX]
insert_last = pointer.contiguous().view(batch_size, 1, 1).expand(batch_size, 1, tag_size)
back_points = back_points.transpose(1, 0).contiguous()
back_points.scatter_(1, last_position, insert_last)
back_points = back_points.transpose(1, 0).contiguous()
decode_idx = Variable(torch.LongTensor(seq_len, batch_size))
if self.use_cuda:
decode_idx = decode_idx.cuda()
decode_idx[-1] = pointer.data
for idx in range(len(back_points)-2, -1, -1):
pointer = torch.gather(back_points[idx], 1, pointer.contiguous().view(batch_size, 1))
decode_idx[idx] = pointer.view(-1).data
path_score = None
decode_idx = decode_idx.transpose(1, 0)
return path_score, decode_idx
- 计算损失
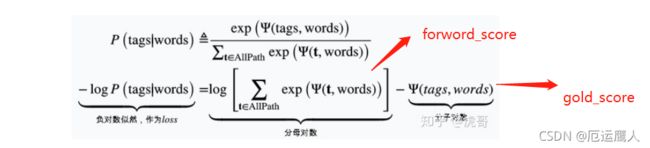
# 求一对 在当前参数下的负对数似然,作为loss
def neg_log_likelihood_loss(self, feats, mask, tags):
"""
Args:
feats: size=(batch_size, seq_len, tag_size)
mask: size=(batch_size, seq_len)
tags: size=(batch_size, seq_len)
"""
batch_size = feats.size(0)
mask = mask.byte()
forward_score, scores = self._forward_alg(feats, mask)# 所有路径的分数和
gold_score = self._score_sentence(scores, mask.byte().bool(), tags)## 正确路径的分数
if self.average_batch:
return (forward_score - gold_score) / batch_size
return forward_score - gold_score