SE模块理解+SE-Resnet模块pytorch实现
文章目录
-
-
- SE模块理解
- SE实现注意力机制原因
- SE-resnet网络pytorch实现
-
SE模块理解
SENet是Squeeze-and-Excitation Networks的简称,拿到了ImageNet2017分类比赛冠军,其效果得到了认可,其提出的SE模块思想简单,易于实现,并且很容易可以加载到现有的网络模型框架中。SENet主要是学习了channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果比较好。
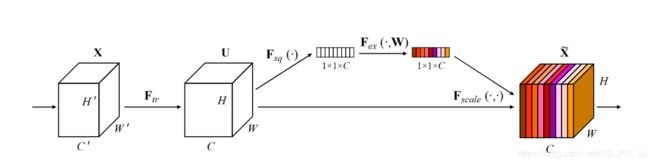 SE模块广泛应用于去噪,去雨方向,利用SE模块添加注意力机制,下面说一下为什么SE模块具有注意力机制的原因。
SE模块广泛应用于去噪,去雨方向,利用SE模块添加注意力机制,下面说一下为什么SE模块具有注意力机制的原因。
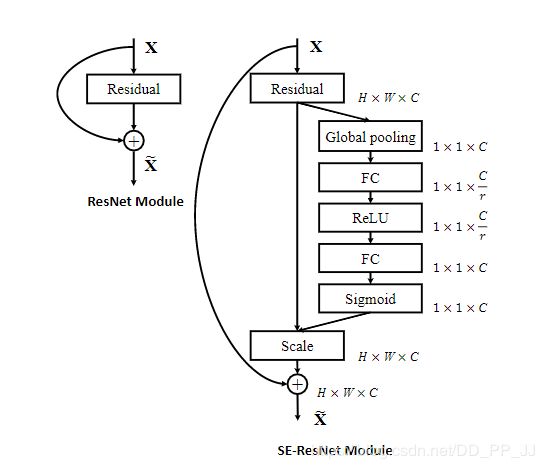
SE实现注意力机制原因
SE可以实现注意力机制最重要的两个地方一个是全连接层,另一个是相乘特征融合
假设输入图像H×W×C,通过global pooling+FC层,拉伸成1×1×C,然后再与原图像相乘,将每个通道赋予权重。在去噪任务中,将每个噪声点赋予权重,自动去除低权重的噪声点,保留高权重噪声点,提高网络运行时间,减少参数计算。这也就是SE模块具有attention机制的原因。
SE-resnet网络pytorch实现
import torch
import torch.nn as nn
# 定义residual
class RB(nn.Module):
def __init__(self, nin, nout, ksize=3, stride=1, pad=1):
super(RB, self).__init__()
self.rb = nn.Sequential(nn.Conv2d(nin, nout, ksize, stride, pad),
nn.BatchNorm2d(nout),
nn.ReLU(inplace=True),
nn.Conv2d(nin, nout, ksize, stride, pad),
nn.BatchNorm2d(nout))
def forward(self, input):
x = input
x = self.rb(x)
return nn.ReLU(input + x)
# 定义SE模块
class SE(nn.Module):
def __init__(self, nin, nout, reduce=16):
super(SE, self).__init__()
self.gp = nn.AvgPool2d(1)
self.rb1 = RB(nin, nout)
self.se = nn.Sequential(nn.Linear(nout, nout // reduce),
nn.ReLU(inplace=True),
nn.Linear(nout // reduce, nout),
nn.Sigmoid())
def forward(self, input):
x = input
x = self.rb1(x)
b, c, _, _ = x.size()
y = self.gp(x).view(b, c)
y = self.se(y).view(b, c, 1, 1)
y = x * y.expand_as(x)
out = y + input
return out
net=SE(64,64)
print(net)
SE(
(gp): AvgPool2d(kernel_size=1, stride=1, padding=0)
(rb1): RB(
(rb): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(se): Sequential(
(0): AvgPool2d(kernel_size=1, stride=1, padding=0)
(1): Linear(in_features=64, out_features=4, bias=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=4, out_features=64, bias=True)
(4): Sigmoid()
)
)