【手撕反向传播】反向传播推导及代码实现
文章目录
- 理论
- 手推过程
- 代码实现
理论
理论层面看我以前的博文:(2020李宏毅)机器学习-Backpropagation
手推过程
单个神经元
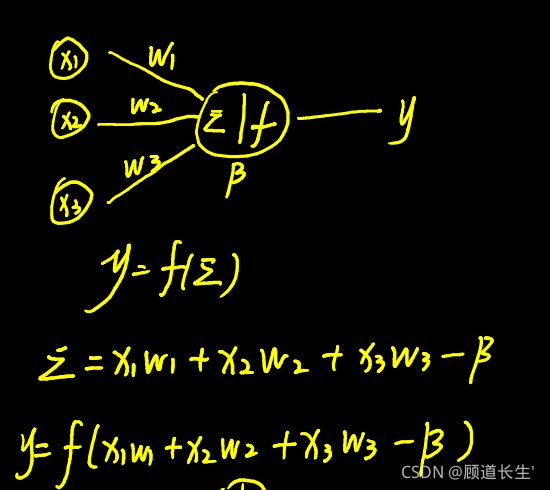
三层的神经网络(input layer+hidden layer+output layer)
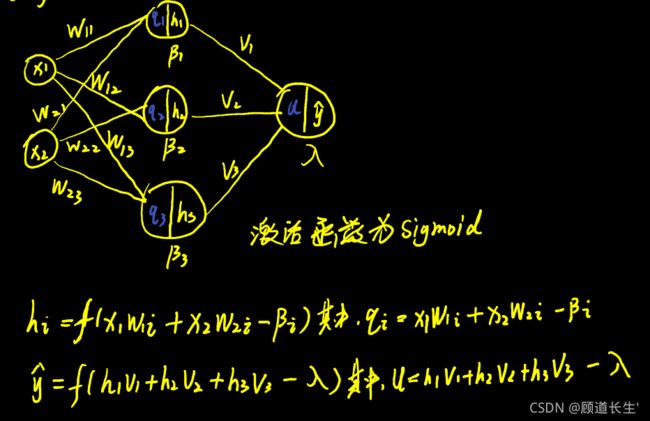
损失函数(MSE损失):
链式法则(chain rule )求梯度:
手推过程如下:


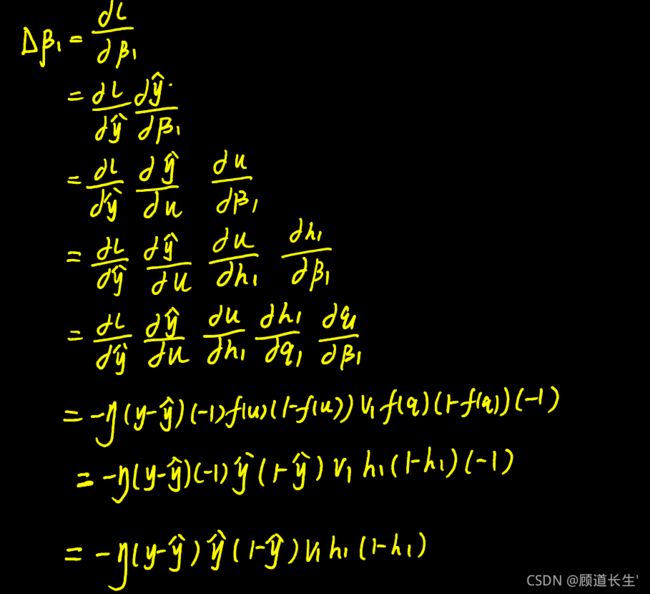

ps:sigmoid函数求导参考我的博文激活函数Sigmoid求导
代码实现
如果想深入理解反向传播,那就需要代码实现,不然理论只是空中楼阁,而C++语言偏底层一些,更容易理解反向传播的本质,所以我采用C++语言实现:
#include运行结果:
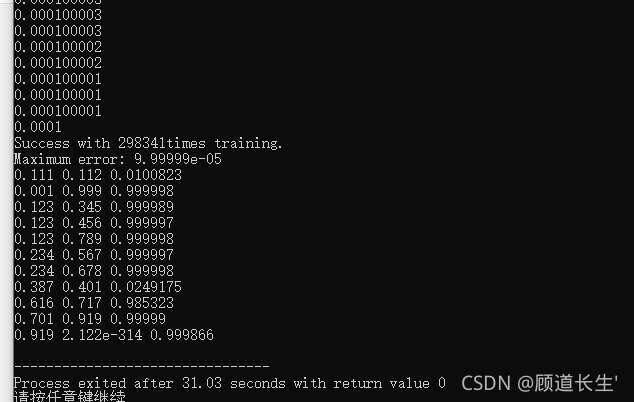
代码中的traindata.txt
0 0 0
0 1 1
1 0 1
1 1 0
0.8 0.8 0
0.6 0.6 0
0.4 0.4 0
0.2 0.2 0
1.0 0.8 1
1.0 0.6 1
1.0 0.4 1
1.0 0.2 1
0.8 0.6 1
0.6 0.4 1
0.4 0.2 1
0.2 0 1
0.999 0.666 1
0.666 0.333 1
0.333 0 1
0.8 0.4 1
0.4 0 1
0 0.123 1
0.12 0.23 1
0.23 0.34 1
0.34 0.45 1
0.45 0.56 1
0.56 0.67 1
0.67 0.78 1
0.78 0.89 1
0.89 0.99 1
testdata.txt
0.111 0.112
0.001 0.999
0.123 0.345
0.123 0.456
0.123 0.789
0.234 0.567
0.234 0.678
0.387 0.401
0.616 0.717
0.701 0.919
网络训练的目的是两个数相同输出为0,不同输出为1,traindata的格式为x,y,output