深度学习:卷积神经网络中的卷积核
卷积核就是图像处理时,给定输入图像,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。又称滤波器。
同样提取某个特征,经过不同卷积核卷积后效果也不一样(这是个重点,为什么说重点,因为CNN里面卷积核的大小就是有讲究的)。
比如说:
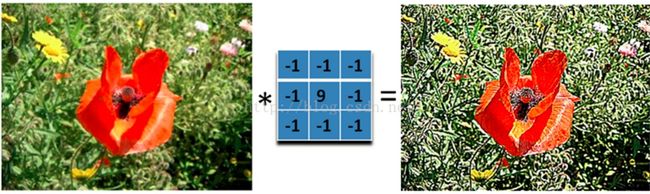

可以发现同样是锐化,下图5x5的卷积核要比上图3x3的卷积核效果细腻不少。
说了这么多,我只想说明,
(1)原始图像通过与卷积核的数学运算,可以提取出图像的某些指定特征(features)。
(2)不同卷积核,提取的特征也是不一样的。
(3)提取的特征一样,不同的卷积核,效果也不一样。
我为啥子要说这些,是因为,CNN实际上也就是一个不断提取特征,进行特征选择,然后进行分类的过程,卷积在CNN里,就是充当前排步兵,首先对原始图像进行特征提取。所以我们首先要弄懂卷积在干什么,才能弄懂CNN。
所以说CNN是在提取图像的每个局部(感受野)范围和卷积核的互相关函数。
神经网络的卷积核(convolutional kernel):
可以看作对某个局部的加权求和;它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。卷积核的大小一般有1x1,3x3和5x5的尺寸(一般是奇数x奇数)。
例如输入224x224x3(rgb三通道),输出是32位深度,卷积核尺寸为5x5。
那么我们需要32个卷积核,每一个的尺寸为5x5x3(最后的3就是原图的rgb位深3),每一个卷积核的每一层是5x5(共3层)分别与原图的每层224x224卷积,然后将得到的三张新图叠加(算术求和),变成一张新的feature map。 每一个卷积核都这样操作,就可以得到32张新的feature map了。 也就是说:不管输入图像的深度为多少,经过一个卷积核(filter),最后都通过下面的公式变成一个深度为1的特征图。不同的filter可以卷积得到不同的特征,也就是得到不同的feature map。。。


卷积层尺寸的计算原理
- 输入矩阵格式:四个维度,依次为:样本数、图像高度、图像宽度、图像通道数
- 输出矩阵格式:与输出矩阵的维度顺序和含义相同,但是后三个维度(图像高度、图像宽度、图像通道数)的尺寸发生变化。
- 权重矩阵(卷积核)格式:同样是四个维度,但维度的含义与上面两者都不同,为:卷积核高度、卷积核宽度、输入通道数、输出通道数(卷积核个数)
- 输入矩阵、权重矩阵、输出矩阵这三者之间的相互决定关系
- 卷积核的输入通道数(in depth)由输入矩阵的通道数所决定。(红色标注)
- 输出矩阵的通道数(out depth)由卷积核的输出通道数所决定。(绿色标注)
- 输出矩阵的高度和宽度(height, width)这两个维度的尺寸由输入矩阵、卷积核、扫描方式所共同决定。计算公式如下。(蓝色标注)
* 注:以下计算演示均省略掉了 Bias ,严格来说其实每个卷积核都还有一个 Bias 参数。
2. 池化(pooling):卷积特征往往对应某个局部的特征。要得到global的特征需要将全局的特征执行一个aggregation(聚合)。池化就是这样一个操作,对于每个卷积通道,将更大尺寸(甚至是global)上的卷积特征进行pooling就可以得到更有全局性的特征。这里的pooling当然就对应了cross region。
与1x1的卷积相对应,而1x1卷积可以看作一个cross channel的pooling操作。pooling的另外一个作用就是升维或者降维,后面我们可以看到1x1的卷积也有相似的作用。
1x1卷积核
1x1卷积核,又称为网中网(Network in Network)[2]。
这里通过一个例子来直观地介绍1x1卷积。输入6x6x1的矩阵,这里的1x1卷积形式为1x1x1,即为元素2,输出也是6x6x1的矩阵。但输出矩阵中的每个元素值是输入矩阵中每个元素值x2的结果。
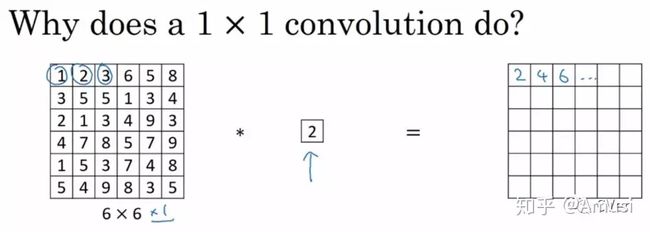
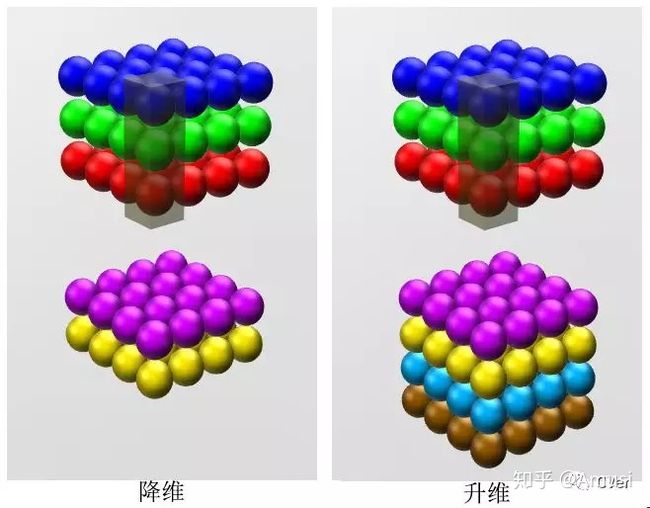
上述情况,并没有显示1x1卷积的特殊之处,那是因为上面输入的矩阵channel为1,所以1x1卷积的channel也为1。这时候只能起到升维的作用。这并不是1x1卷积的魅力所在。
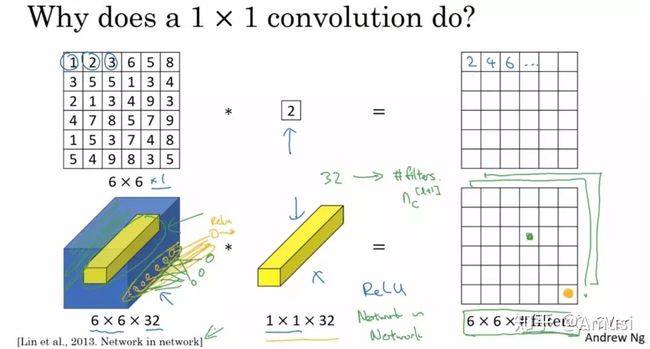
让我们看一下真正work的示例。当输入为6x6x32时,1x1卷积的形式是1x1x32,当只有一个1x1卷积核的时候,此时输出为6x6x1。此时便可以体会到1x1卷积的实质作用:降维。当1x1卷积核的个数小于输入channels数量时,即降维[3]。
注意,下图中第二行左起第二幅图像中的黄色立方体即为1x1x32卷积核,而第二行左起第一幅图像中的黄色立方体即是要与1x1x32卷积核进行叠加运算的区域。
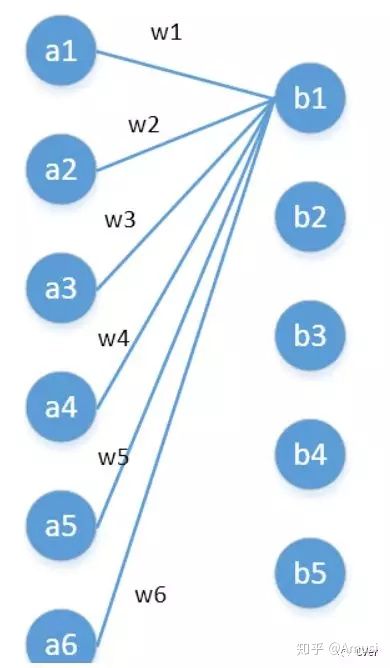
其实1x1卷积,可以看成一种全连接(full connection)。
第一层有6个神经元,分别是a1—a6,通过全连接之后变成5个,分别是b1—b5,第一层的六个神经元要和后面五个实现全连接,本图中只画了a1—a6连接到b1的示意,可以看到,在全连接层b1其实是前面6个神经元的加权和,权对应的就是w1—w6,到这里就很清晰了。
第一层的6个神经元其实就相当于输入特征里面那个通道数:6,而第二层的5个神经元相当于1*1卷积之后的新的特征通道数:5。
w1—w6是一个卷积核的权系数,若要计算b2—b5,显然还需要4个同样尺寸的卷积核[4]。
上述列举的全连接例子不是很严谨,因为图像的一层相比于神经元还是有区别的,图像是2D矩阵,而神经元就是一个数字,但是即便是一个2D矩阵(可以看成很多个神经元)的话也还是只需要一个参数(1*1的核),这就是因为参数的权值共享。
注:1x1卷积一般只改变输出通道数(channels),而不改变输出的宽度和高度
1x1卷积核作用
降维/升维
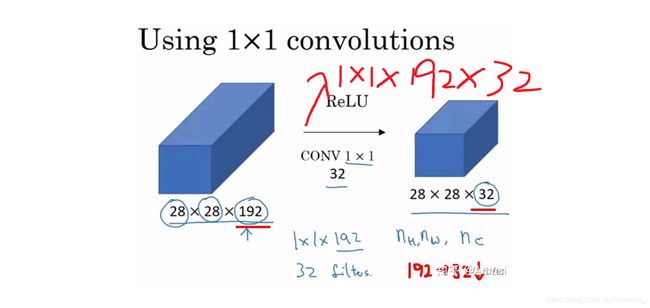
由于 1×1 并不会改变 height 和 width,改变通道的第一个最直观的结果,就是可以将原本的数据量进行增加或者减少。这里看其他文章或者博客中都称之为升维、降维。但我觉得维度并没有改变,改变的只是 height × width × channels 中的 channels 这一个维度的大小而已[5]。
增加非线性
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
备注:一个filter对应卷积后得到一个feature map,不同的filter(不同的weight和bias),卷积以后得到不同的feature map,提取不同的特征,得到对应的specialized neuron[7]。

跨通道信息交互(channal 的变换)
例子:使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3,64channels的卷积核后面添加一个1x1,28channels的卷积核,就变成了3x3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互[7]。
注意:只是在channel维度上做线性组合,W和H上是共享权值的sliding window
参考资料:https://zhuanlan.zhihu.com/p/40050371