【数据挖掘笔记】基础知识
理论
绪论
- 数据挖掘 (数据中的知识发现,KDD):发现隐藏在大型数据集中的模式(有趣的模式,即知识)
- 数据挖掘步骤(有时还包括数据归约:得到原始数据的较小表示,而不牺牲完整性)


- 数据库(管理)系统:数据(库)+软件程序
- 数据仓库:从多个数据源收集的信息存储库,存放在一致的模式下,并通常驻留在单个站点。/从结构角度看,有三种数据仓库模型:企业仓库、数据集市和虚拟仓库。/数据仓库通常采用三层体系结构:底层是数据仓库服务器,它通常是关系数据库系统;中间层是OLAP服务器;顶层是客户,包括查询和报表工具。
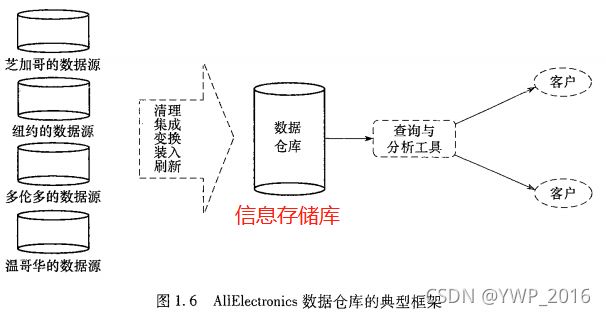
- 联机事务处理(Online Transaction Processing, OLTP)系统:联机操作数据库系统——执行联机事务和查询处理。
- 联机分析处理(Online Analytical Processing, OLAP)系统:数据仓库系统——为用户或“知识工人”提供服务。这种系统可以用不同的格式组织和提供数据,以便满足不同用户形形色色的需求。/数据仓库很适合OLAP。OLAP操作的例子如上卷roll-up(上钻drill-up)和下钻drill-down。上卷eg:在location维上卷,从城市到国家;下钻eg:在time维下钻,从季度到月。(详见《数据挖掘:概念与技术》P96)

- 数据立方体:通常,数据仓库用数据立方体这个多维数据结构建模,每个维对应模式中的一个/一组属性,每个单元存放某种聚集度量值。

- 频繁模式:数据中心频繁出现的模式,包括频繁项集、频繁子序列(序列模式)和频繁子结构。频繁项集:频繁地在事务数据集中一起出现的商品集合,如牛奶和面包。频繁子序列:如,顾客倾向于先买便携机,再买数码相机,然后买内存卡。频繁子结构:可能涉及不同结构(如,图、树 或格),可以与项集或子序列结合。
- 挖掘频繁模式→→→数据中有趣的关联和相关性。频繁项集挖掘是频繁模式挖掘的基础。
- 关联分析

认识数据
- 属性可以是标称的、二元的、序数的或数值的
- 分位数:取自数据分布的每隔一定间隔上的点。如,2-分位数(对应中位数)将数据分布划分为高低两半,4-分位数将数据分布划分为4个相等部分。
- 四分位数极差:第一个和第三个四分位数之间的距离。
- 方差与标准差:度量数据散布程度,低标准差——数据观测趋向均值,高标准差——数据散布在一个大的值域中
- 截尾均值trimmed mean:丢弃高低极端值(避免丢弃太多)后的均值
- 中列数midrange:最大值和最小值的平均值
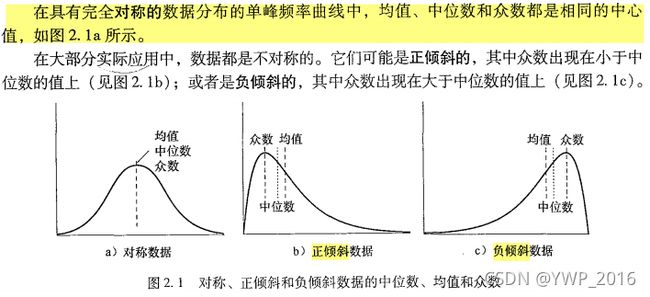
- 正倾斜、负倾斜
- 极差:最大值与最小值之差
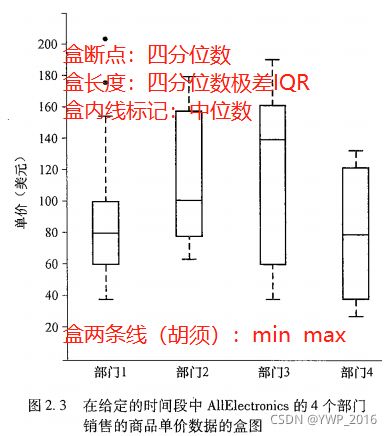
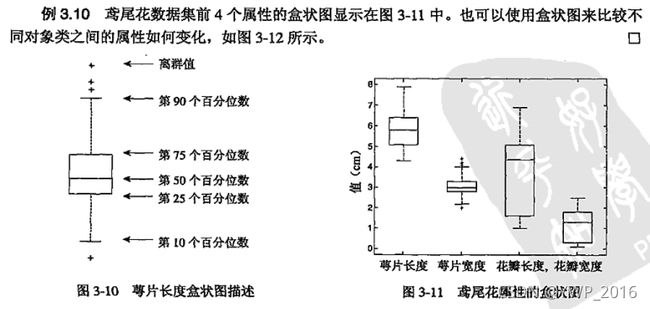
- 盒图
- 三维散点图

- 维归约(个人理解,即降维):通过创建新属性,将一些旧属性合并以降低数据集的维度。通过选择旧属性的子集得到新属性,这种维归约称为特征(子集)选择。
- 特征创建的三种有效方法:特征提取、映射数据到新的空间(如傅里叶变换:可将原始时间序列数据转换成频率信息表示,便于检测有趣模式;小波变换)、特征构造
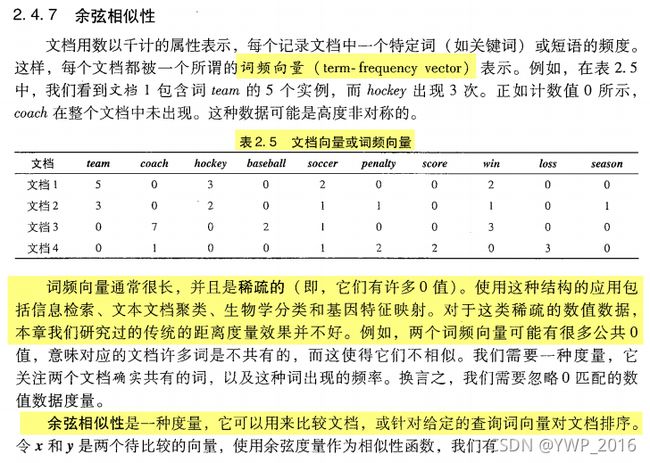
- 余弦相似度:文档相似性最常用的度量之一
探索数据
- 汇总统计:频率、众数、百分位数、位置度量:均值与中位数、散步度量:极差与方差
- 可视化:以图或表形式展示信息
- OLAP和多维数据分析:多维数组、数据立方体
数据预处理
- 数据清理:清除数据中的噪声,纠正不一致
- 数据集成:将数据由多个数据源合并成一个一致的数据存储,如数据仓库。应用案例如:顾客标识在不同数据库中的记录不同,customer_id与cust_id
- 数据归约:通过如聚集、删除冗余特征或聚类来降低数据的规模。分为维归约与数值归约,前者如主成分分析、小波变换,后者如聚类、抽样等。
- 数据变换(如规范化):用以将数据压缩到较小区间,如0.0到1.0
实践
- 鸢尾花(Iris)数据集 探索性数据分析
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。

from sklearn.datasets import load_iris #导入数据集iris
iris = load_iris() #载入数据集
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris # 导入数据集iris
# 载入数据集
iris = load_iris()
# 获取花卉两列数据集(只用两个特征 分析作图)
DD = iris.data
X = [x[0] for x in DD]
Y = [x[1] for x in DD]
# plt.scatter(X, Y, c=iris.target, marker='x')
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='Iris-setosa') # 前50个样本是Iris-setosa
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='Iris-versicolor') # 中间50个是Iris-versicolor
plt.scatter(X[100:], Y[100:], color='green', marker='+', label='Iris-virginica') # 后50个样本是Iris-virginica
plt.legend(loc=2) # loc=1,2,3,4分别表示label在右上角,左上角,左下角,右下角
plt.show()
文献阅读
文献:裴韬,刘亚溪,郭思慧,舒华,杜云艳,马廷,周成虎.地理大数据挖掘的本质[J].地理学报,2019,74(03):586-598.
- 地理数据挖掘的出现
早在30年前,计算机领域的研究者就已经预见到海量数据将会给计算机科学及其他学科的发展带来的挑战与机遇,提出了“数据挖掘”一词。1995年,李德仁院士率先倡导从GIS数据库中发现知识。之后,Harvey等提出“地理数据挖掘与知识发现”(Geographic Data Mining and Knowledge Discovery),标志着地理学与数据挖掘技术的实质性交叉……
- 大数据的“5V”特征:Volume(大量)、Velocity(更新快)、Variety(多样)、Value(价值)、Veracity(真实性);大数据的“5度”特征:时空粒度(细)、时空广度(宽)、时空密度(大)、时空偏度(重)和时空精度(差)等。
-
时空粒度 细:如果将地理信息承载单元的大小称为粒度,那么地理大数据的出现,则让地理信息的承载粒度由大变小。由于不同类型大数据的获取方式不同,因此粒度对于不同数据的含义也不一样。 在对地观测大数据中,粒度是指数据所代表的(地表)范围大小,粒度的变化体现在由对地观测大数据反演得到的地物单元不断地细化。 而在人类行为大数据中,粒度是指记录和统计单元的大小,粒度的变细表现为用以记录和统计的单元的缩小。
-
时空偏度 重:如人类行为大数据普遍存在有偏的现象,集中体现为数据载体在时间、空间和属性等几个方面的有偏性。
-
时空精度 差:地理大数据另一个不容忽视的缺陷是其精度较差。
- 数据挖掘的尺度性:体现在不同观察尺度下所挖掘出的模式不同。 地理模式都是在一定尺度下出现的,而地理大数据挖掘也离不开尺度。 我们认为大尺度的复杂模式可以视为若干局
部均匀模式的叠加。